Whenever we talk about the scalability of databases its end up with a lot of discussions and effort to implement. Some of you may even argue that it is a bad idea to auto scale the transactional databases. But the pace of innovation in databases — particularly on a world with public cloud, is breathtaking. AWS Aurora is a game changer database engine in DBaaS for Open Source Databases. It provides performance, reliability, availability, and Scalability. With Aurora features like custom endpoints and loadbalancing across replicas, on can explore some interesting use cases. In this post, we will discuss how we solved a customer’s problem by using scalability features of Aurora. We will focus on provisioned Aurora on AWS, not Aurora Serverless.
We have a customer who was doing all the reporting and massive read workloads on RDS Read Replica (note — plain RDS, not aurora). But in their case, it's not fit for unpredictable heavy read transactions. Even during the predictable traffic, it's hard to manage the query load balancing and maintaining multiple read replicas. We can use ProxySQL but there is additional overhead for managing ProxySQL’s availability, Pricing and etc. So we concluded this with replacing RDS read replica with Aurora for read intensive workloads. Although the replicas are Aurora, master continues to be RDS (didn’t want to mess with production, yet)
Problem Statement:
- The current architecture has one Master and one Slave. The slave node is pretty much bigger in size comparing to Master.
- The business reports will be generated on a daily basis, processes massive amount of data in Read replica.
- During this report generation, the Read Replica is being throttled with CPU and IOPS.
- There are 150+ Lambda functions and many application modules are directly talking to Read Replica to get the data.
- Sometimes due to sudden(unpredictable) heavy traffic, the Read replica was not able to handle the load which affects the performance a lot.
- There was no load balancing layer to split the read workloads to multiple read replica.
Solution:
If you look at the problem statement, the bottleneck is Scalability. Normal RDS instances never scale. And as mentioned in the introduction of managing the separate load balancing layer for multiple Read replica is an additional effort.
Replacing the RDS Read Replica with Aurora will give you better seamless scalability.
- Creating an Aurora read replica for the RDS master will give you more throughput than RDS.
- The auto-scaling feature will help to handle any unpredictable workload. Auto-scaling will be trigger by CPU and Connections metrics.
- AWS Lambda also will spin up the Aurora Read Replica to handle the predictable heavy traffic.
- Custom Endpoints will automatically add all new nodes which are coming from Autos scaling and provisioned by Lambda.
- Adding more nodes to Aurora cluster doesn’t take much time, unlike RDS.
Challenge with Aurora Cluster:
At any point of time, Aurora Cluster must have at least one node. This one node will be handling the Master Role. Once we create the Aurora Read Replica then the Writer Endpoint assigned to this node. But the writes are happening in RDS, not Aurora. I want to use this node for my Reporting/Read purpose.
Challenge with Reader Endpoint:
AWS Aurora provides Writer and Reader endpoint. This is good enough to split the read traffic among with all Read Replica nodes. But here the Aurora Master itself the replica for RDS. So partially its a Slave. And it will never get the traffic through Reader Endpoint.
while reading the above two challenges, you’ll get to know that we should use this Master Aurora Node for splitting the read queries and somehow the Reader endpoint should cover the Master node as well. Unfortunately, It's not possible for Reader EndPoint to Include the Master Node. (yes, its purpose is different).
Custom Endpoint:
So here we are coming to another interesting component for Aurora is Custom Endpoints. Generally, Reader Endpoint automatically sends the traffic to all of the Reader Nodes. But custom endpoints will help us to add any nodes in it. We can create an endpoint which will act as a load balancer for both Reader node and Writer node. If you have multiple Read nodes, you can split them for a different purpose.
Example:
You have a Data Science team and Data Analytics team. You have 3 Read Replicas. You want to grant Data Science team to use 2 read nodes meantime, remaining 1 master and 1 read replica will be accessed by Data Analytics team. So they have different use cases and workloads.
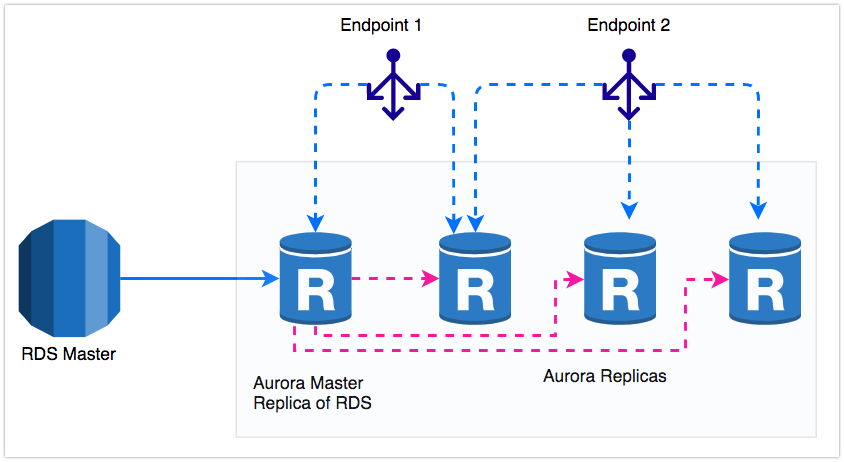
By using custom endpoints we can achieve this setup and these endpoints are highly available load balancers for your Aurora Nodes.
Architecture:
This is the final Architecture for this seamless scalability.
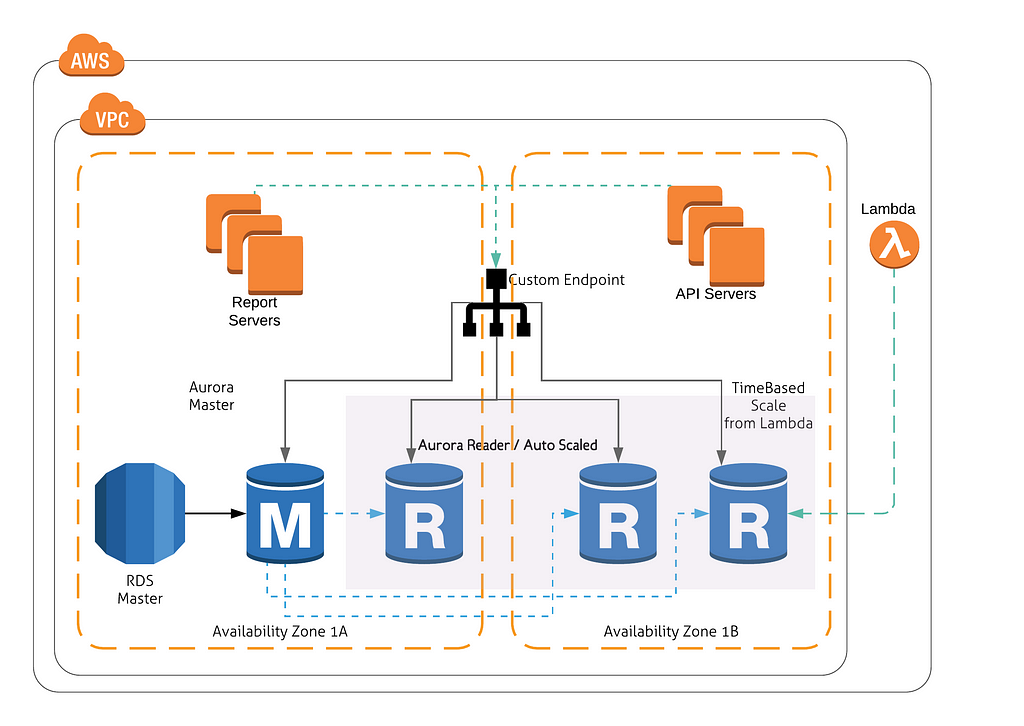
Implementation:
We have explained the solution in a detailed way. So for the implementation part, we are just going to give simple steps and you can refer the AWS documentation for further clarifications.
Initial Setup:
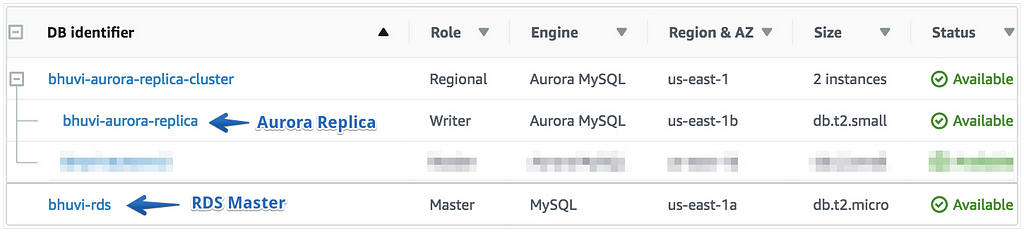
- Provision an RDS MySQL Instance.
- Create Aurora Read Replica for that RDS instance.
- It’ll create an Aurora Cluster and the Aurora Replica will be handling the Writer Role of the Cluster.
- Note: It’ll get write Access.
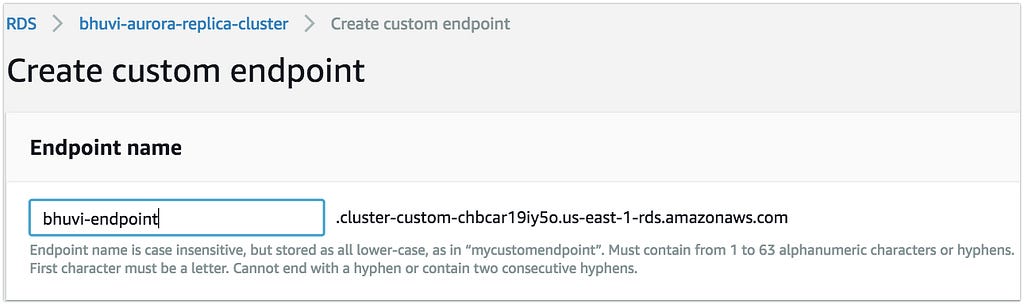
Create Custom Endpoint:
- Click on your cluster Name.
- Under the connectivity click on Create Custom Endpoint.
- In the Endpoint Name, give any of your favorite name.[Fig 1]
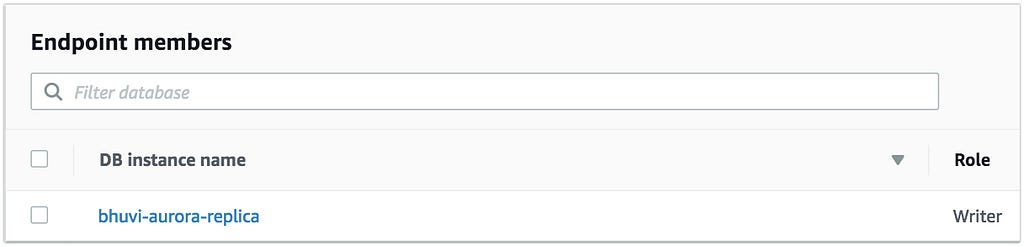
- In EndPoint Members, Add the Aurora Master(right now we have only one node). [Fig 2]
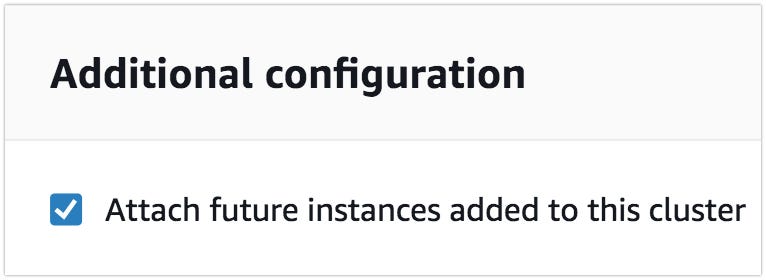
- Also, there is a checkbox Attach future instances added to this cluster. This will help you to automatically add it to the endpoint if auto-scaling spin up a new Node or if someone manually adds a new node to the cluster. [Fig 3]
- Click on Create Endpoint, then you’ll see 3 endpoints. [Fig 4]

Lambda Function — Provision one Node:
Now, we are aware of that daily reporting needs more power to generate the reports. So to handle this predictable workload, we need one additional instance. This lambda function will provision that. You can create a CloudWatch event to schedule this operation.
You need to attach the below policy to the Lambda function.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"rds:CreateDBCluster",
"rds:CreateDBInstance"
],
"Resource": "*"
}
]
}
Use the below code for Lambda(Python 3.7) Function:
import time
import boto3
import botocore
def lambda_handler(event, context):
rds = boto3.client('rds')
rds.create_db_instance(
DBParameterGroupName='default.aurora-mysql5.7',
Engine='aurora-mysql',
EngineVersion='5.7.12',
DBClusterIdentifier='bhuvi-aurora-replica-cluster',
AvailabilityZone='us-east-1b',
DBInstanceClass='db.t2.small',
DBInstanceIdentifier='bhuvi-aurora-lambda1',
PubliclyAccessible=True,
StorageEncrypted=False,
PromotionTier=15)
Lambda function to Delete the node which is provisioned by the above function.
import time
import boto3
import botocore
def lambda_handler(event, context):
rds = boto3.client('rds')
rds.delete_db_instance(
DBInstanceIdentifier='bhuvi-aurora-lambda1',
SkipFinalSnapshot=False)
Note: The parameters which I mentioned above are actually for my test purpose. You can give your cluster name, parameter group, Encryption and etc.
If you trigger this lambda function, you’ll get an instance called bhuvi-aurora-lambda1
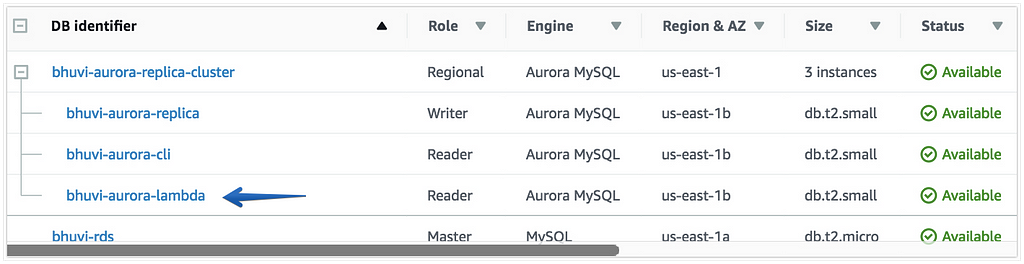
You can use AWS CLI instead of Lambda.
AutoScaling:
Let’s configure Aurora Autoscaling for handling any unpredictable workloads.
- Click on your Cluster Name and go to Logs & Events.
- Click on Add Auto scaling Policy.
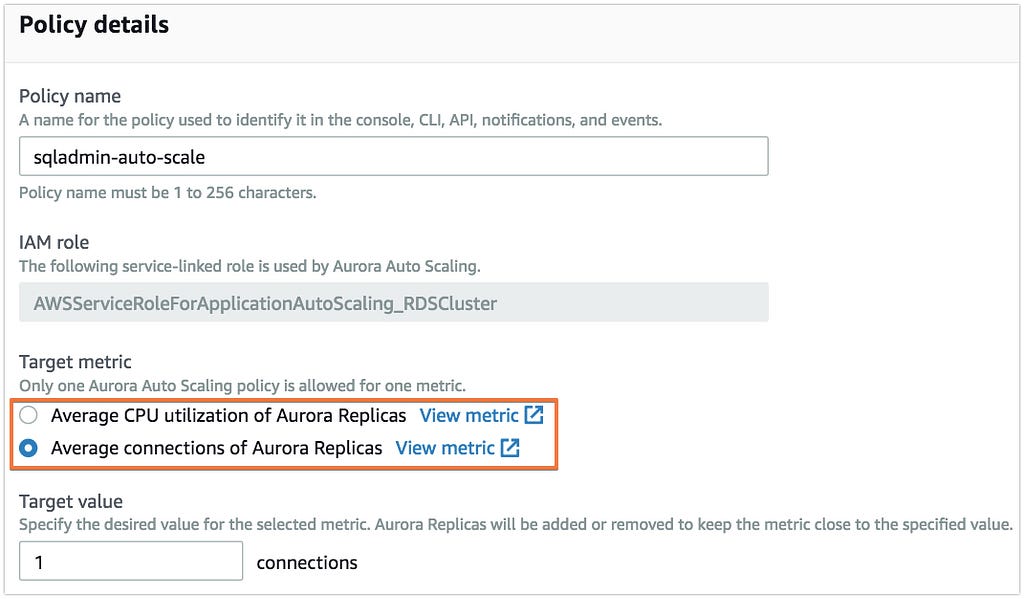
- We can scale based on CPU load or the number of connections.
- In our case, its CPU intensive, but for Demo, I select the number of connections.
- In the Target Value, give your threshold limit.
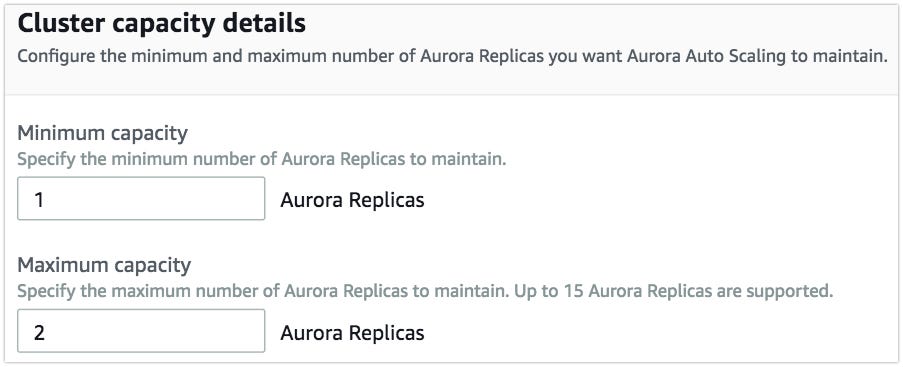
- In Cluster capacity details, you can mention How many instances must be running at any point in time and what the maximum instance count to scale.
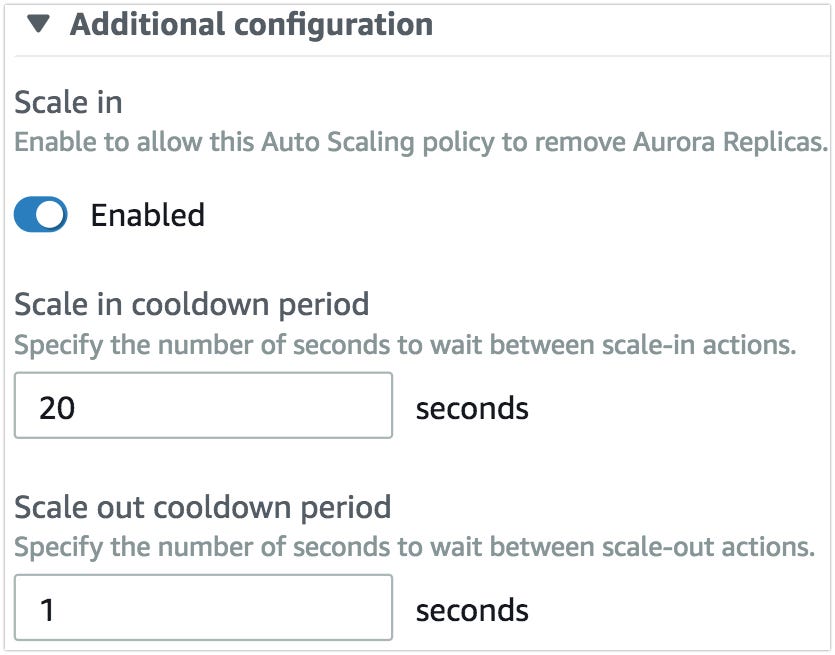
- There is one more option called Additional configuration. This option will help you to define, how many seconds needs to wait to scale in or scale out. For example, you want to scale out when your Cluster consumes 80% CPU for 5mins, it shouldn’t scale when it touched 80% immediately. So in Scaleout cooldown box, you can mention 300.
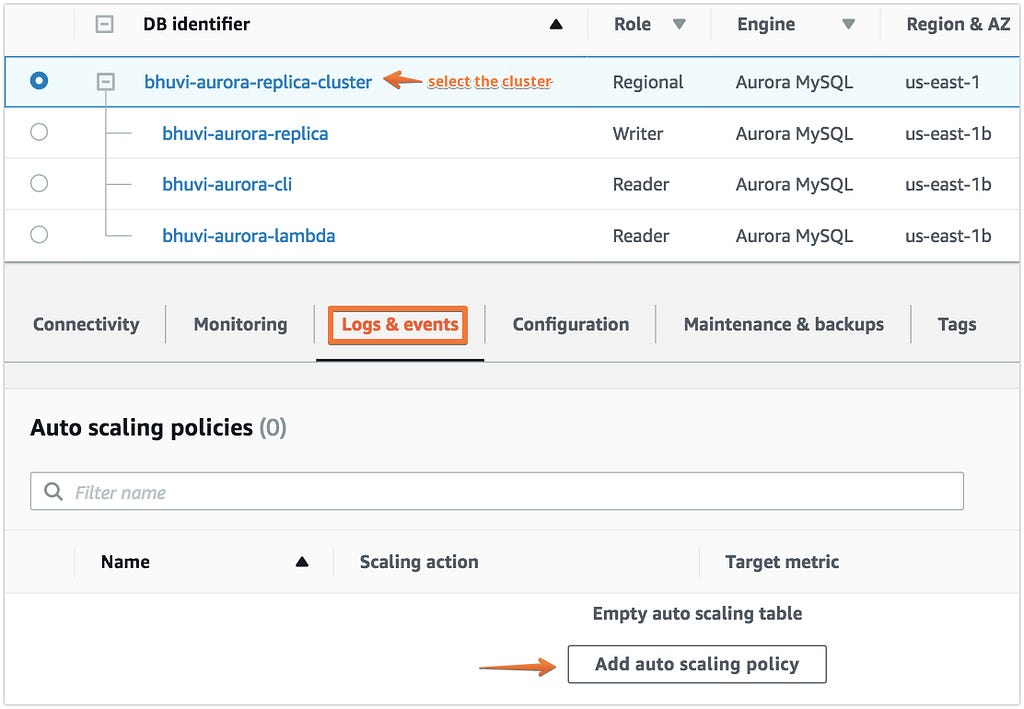
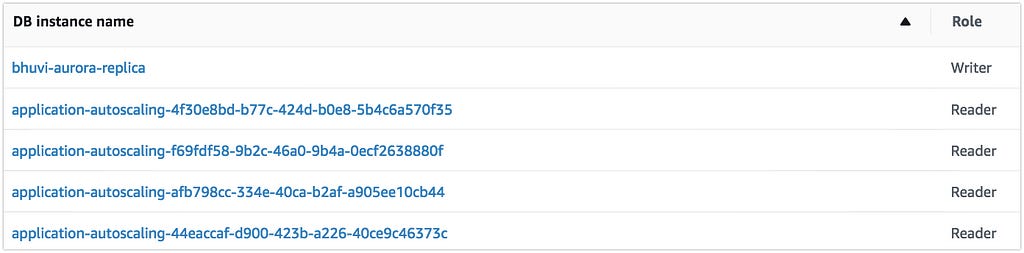
If the scale happened, you can see the number of instances has been provisioned and they are automatically added to the Custom Endpoint.
Our Feedback about Aurora Autoscaling:
- The auto-scaling works well, but all of the nodes will get the failover priority as 15, Because we don’t want these instances will be the Master after failover.
- Make sure about your Cluster capacity in AutoScaling configuration. Because if you select min 1 and max 2, but you already have 2 instances in the cluster, then the scaling never happen. Refer the Fig 4.
- During the scale in, it’ll never terminate the nodes which not provisioned by the auto-scaling.
- This might be a glitch, we have generated fake traffic using an infinite loop in a shell script, during the scale in, I was waiting to complete the transaction. But in the console, it was showing DELETING for an hour, and meantime, we can able to create new connections to that node. It would be a great improvement if they block the incoming connection when the node marked as deleting. Then we killed the loop and it removed from the cluster.
- The Aurora which is replicating from RDS has write Access. Nothing wrong with this. Because according to Aurora its the master. So careful while running any queries on top this custom endpoint.
Hope, you are going to scale your databases and make DBAs life peaceful.
Supercharge your Reporting: Aurora Autoscaling and Custom Endpoints was originally published in Searce Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.