Details of Re-execution and Empty Transactions
In my previous post, we saw how GTIDs are generated and propagated, we described the new replication protocol, and we saw how these simple elements fit together to allow failover in a range of examples, from simple tree topologies to circular topologies to any topology you could possibly think about.We will now dive deeper into how GTIDs work. In particular, we will see how the slave thread ensures that no transaction is executed more than once. As a side note, mysqlbinlog uses the same mechanism. We will introduce the concept of empty transactions and see how this allows us to suppress transactions in a safe manner.
The replication thread
Let us start with looking at the replication thread. As we remember from previous post, the master stores GTIDs as events in the binary log, and the GTID event preceds the transaction. When the slave thread reads the GTID, it sets the session server variable gtid_next to that GTID. For example, if the slave thread reads 4d8b564f-03f4-4975-856a-0e65c3105328:4711, then it executes the following SQL statement:SET GTID_NEXT = 4d8b564f-03f4-4975-856a-0e65c3105328:4711;This tells the server to use 4d8b564f-03f4-4975-856a-0e65c3105328:4711 instead of generating a new identifier.
Mysqlbinlog
The same statement can be executed by any client, if the client has SUPER privileges (the reason for this seemingly very strict requirement will soon be explained).The same mechanism is also used by mysqlbinlog. (If you don't know: mysqlbinlog is a command line utility, separate from the core server, that reads a binary log file and outputs the contents in text form, as a sequence of SQL statements. By piping this output to a client, you make that client act as the replication thread.) When mysqlbinlog reads a GTID-event, it outputs a SET GTID_NEXT statement. Thus, the client that executes the output from mysqlbinlog will correctly re-execute not only the transactions but also the GTIDs.
Transactions Must Only Execute Once
Now, what if the transaction specified by GTID_NEXT has already been executed? We don't want the transaction to be executed more than once: first, it would likely take the server to an inconsistent state. Second, and more fundamentally, we can't have two transactions with the same GTID in the binary log; that would lead to other errors on the next failover.Therefore, when the server executes SET GTID_NEXT, it checks if that transaction is already executed (i.e., if the GTID is in @@GLOBAL.GTID_DONE):
- If not, then everything is fine and the server executes the transaction.
- But if the GTID is in @@GLOBAL.GTID_DONE, then the transaction is not executed by the server – this second attempt to execute the same transaction is completely ignored by the server and has no effect whatsoever.
Empty Transactions – Making the Slave Skip Transactions
The fact that the server skips already executed transactions is more than a mechanism to prevent disastrous mistakes. It is also an important tool that allows us to make filters GTID-safe, let the DBA skip a transaction in a safe manner, or to start replicate from a specific point in the replication stream in a safe manner. (And by “safe”, I wish to emphasize that an “obvious” way to accomplish these things, which we have deliberately not implemented, would be highly unsafe, risking such nasty things as data corruption not immediately but at the next failover.)Let us start with an example:

A is the master, B is the slave; A has executed three transactions and B has replicated all of them. Now suppose we want to attach another slave, C, to A. Also suppose that we do not want C to execute trx1 or trx2. There may be many reasons to skip the transactions: perhaps C is only supposed to hold a subset of the tables, and trx1 and trx2 touch a table that C does not have; or maybe trx1 was a mistake and trx2 is an “anti-transaction” that undoes trx1, and both are really huge so it would be more efficient to skip both; or trx1 and trx2 are in some other way unnecessary or unwanted on C.
It is tempting to think that we can just skip trx1 and trx2 and make C replicate starting from trx3, so that we would have the following situation:
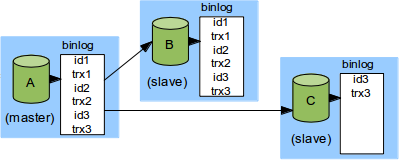
Not only can this corrupt the database (because the transactions are re-executed out of order on C). It corrupts the database silently – no error message – and in a failover situation where a server has just crashed and the DBA certainly has enough trouble already. Moreover, the problematic transactions may be really old – maybe we did not have to failover until years after trx1 and trx2 were skipped – so both the context of trx1 and trx2, and the context where they were skipped may be long forgotten by the DBA, possibly making the situation even more difficult to debug and correct.
The good news is that we don't allow the type of skipping that leads to this DBA nightmare. Instead, we provide a robust mechanism to achieve the wanted effect in a safe manner.
Recall that the server skips transactions if GTID_NEXT is set to a GTID that already exists in GTID_DONE. Therefore, to skip a transaction with a given GTID, all we have to do is to firstexecute a transaction that has no effect – a “no-op” – with the same GTID. It is as simple as this:
mysql> SET GTID_NEXT = “4d8b564f-03f4-4975-856a-0e65c3105328:4711”;
mysql> COMMIT;
mysql> COMMIT;
Normally, a single commit statement would not make a difference in any way. But when GTID_NEXT is set to a GTID, it causes the server to write an empty transaction, just a BEGIN/COMMIT pair with nothing inbetween, to the binary log:
Empty Transactions and Failover
Let us revisit the last example and see what happens when we “skip” trx1, trx2 using empty transactions. Before we connect C as a slave of A, we commit two empty transactions on C, with GTID id1 and id2, respectively:So far we have accomplished what we want: C has skipped trx1 and trx2 (but it has id1 and id2) and started to replicate.
Now, what happens on failover? Suppose again that A crashes, we make B the new master and wish to connect C as a slave to B. C then sends “id1-id3” to B, and B will send everything else to C. trx1 and trx2 do not come back to C in this case because we committed empty transactions with the same GTIDs.
This example highlights one important point: GTIDs are a part of the server state. Two servers that have the exact same data but different sets of GTIDs in their binary logs should not be considered “the same”. Luckily, the tools we provide (e.g., empty transactions) ensure that server states do not diverge in unwanted ways.
Replication Filters and Empty Transactions
Another scenario where empty transactions play an important role is when using replication filters. Filters were designed to allow a slave to hold only a subset of the master's database. For instance, if the slave server is started with the command line option --replicated-ignore-db=mydatabase, then the slave will check that database of every binary log event it receives from the master and skip everything that belongs to mydatabase.Suppose again we have a setup where A is the master, with two immediate slaves B and C, and C filters out updates from database mydatabase:
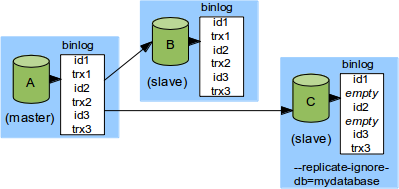
Suppose, moreover, that trx1 and trx2 operate on mydatabase, so that C skips them. We have implemented it so that C then commits empty transactions with GTIDs id1 and id2, as in the illustration.
If A crashes as this point, and B becomes the new master, and C a slave of B, then the empty transactions ensure that id1 and id2 are included in C's GTID_DONE. This in turn implies that C sends id1 and id2 to B when it connects as a slave, so that B does not send trx1 or trx2 to B again.
This is important for performance: the sum of all transactions that ever operated on database mydatabase naturally occupies no less gigabytes than the entire database mydatabase itself. If we did not have the empty transactions on C, blocking B from sending this potentially huge amount of data to C, then the failover would risk causing a significant disruption while C wades through oceans of transactions that it has already skipped.
GTID_NEXT is only settable by SUPER
Remember I said that GTID_NEXT is only settable by users that have SUPER privileges? Now it should be evident why this is the case: by setting GTID_NEXT, you make the replication thread suppress arbitrary transactions from the master. This is true no matter which user committed the transaction on the master. Therefore, it would not be safe to allow non-SUPER users to set GTID_NEXT.
Summary
We have seen that the slave thread executes SET GTID_NEXT to specify the GTID of the next transaction to come. The mysqlbinlog utility does the same, and a DBA can do the same if that is needed.A transaction that has the same GTID (specified by GTID_NEXT) as an already committed transaction, is skipped.
To suppress a transaction on a slave that has not yet replicated it, commit an empty transaction with the GTID of the transaction to skip.

PlanetMySQL Voting: Vote UP / Vote DOWN