During the last few months we had a lot of opportunities to present and discuss about a very powerful tool that will become more and more used in the architectures supporting MySQL, ProxySQL.
ProxySQL is becoming every day more flexible, solid, performant and used (http://www.proxysql.com/ and recent http://www.proxysql.com/compare).
This is it, the tool is a winner in comparing it with similar ones, and we all need to have a clear(er) idea on how integrate it in our architectures in order to achieve the best results.
The first to keep in mind is that ProxySQL is not natively supporting any high availability solution, in short we can setup a cluster of MySQL(s) and achieve 4 or even 5 nines of HA, but if we include ProxySQL, as it is, and as single block, our HA will include a single point of failure (SPOF) that will drag us down in case of crash.
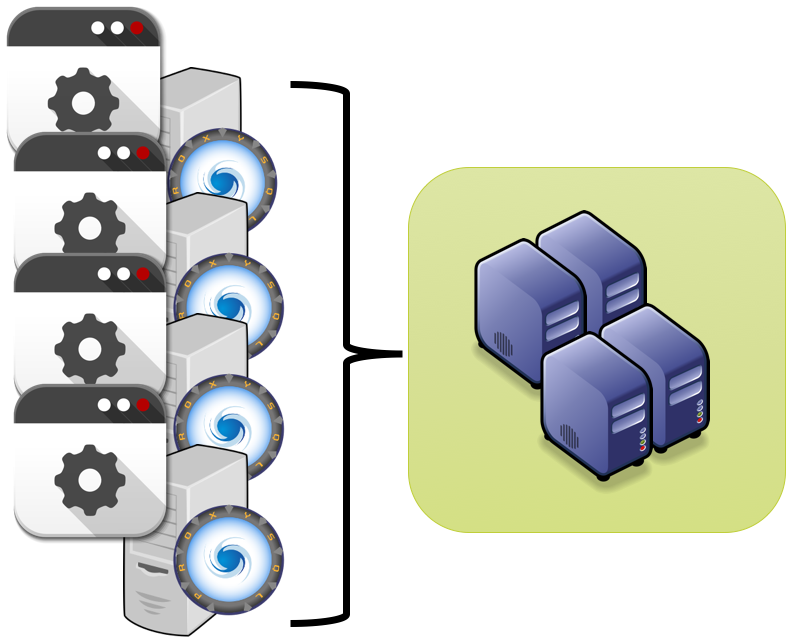
To solve this, the most common solution so far had be to setup ProxySQL as part of a tile architecture, where Application/ProxySQL where deploy together.
![tileProxy]()
This is a good solution for some cases, and for sure it reduce the network hops, but what it may be less than practical when our architecture has a very high number of tiles.
Say 100 or 400 application servers, not so unusual nowadays.
In that case managing the ProxySQL will be challenging, but most problematic it will be the fact that ProxySQL must perform several checks on the destination servers (MySQL), and if we have 400 instance of ProxySQL we will end up keeping our databases busy just because the checks.
In short ... is not a smart move.
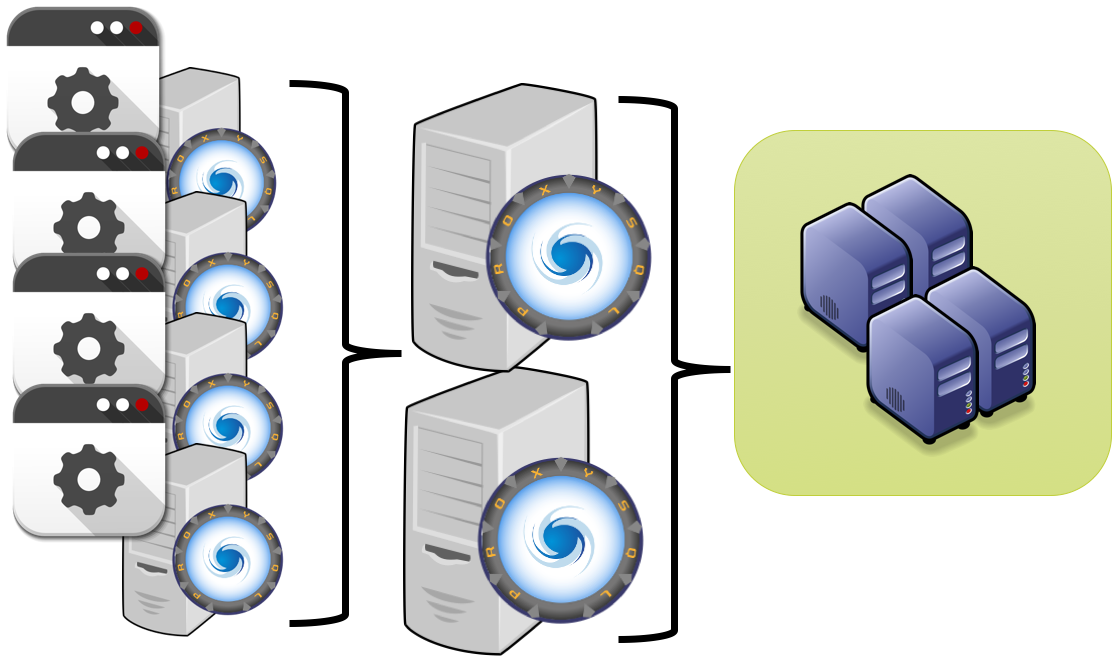
Another possible approach, used so far was to have two layers of ProxySQL, one close to the application, another in the middle to finally connect to the database.
I personally don't like this approach for many reasons, but the most relevants are that this approach create additional complexity in the management of the platform, and it adds network hops.
![ProxyCascade]()
So what can be done?
I like to have things simple, I love the KISS principle, I love to have things simple and because I am lazy I love to reuse the wheel instead re-invent things that someone else had already invent.
Last thing I like to have my customers not depending from me or any other colleague, once I am done, and gone, they must be able to manage their things, understand their things, fix their things by themselves.
Anyhow as said I like simple things. So my point here is the following:
- excluding the cases where a tile (application/ProxySQL) make sense;
- or when in the cloud and tools like ELB (Elastic load balancer) exist;
- or on architecture already including a balancer.
What I can use for the remaining cases?
The answer comes with existing solutions and combining existing blocks, KeepAlived + ProxySQl + MySQL.
![keepalived_logo]()
For KeepAlived explanation visit http://www.keepalived.org/.
Short description
"Keepalived is a routing software written in C. The main goal of this project is to provide simple and robust facilities for loadbalancing and high-availability to Linux system and Linux based infrastructures. Loadbalancing framework relies on well-known and widely used Linux Virtual Server (IPVS) kernel module providing Layer4 loadbalancing. Keepalived implements a set of checkers to dynamically and adaptively maintain and manage loadbalanced server pool according their health. On the other hand high-availability is achieved by VRRP protocol. VRRP is a fundamental brick for router failover. In addition, Keepalived implements a set of hooks to the VRRP finite state machine providing low-level and high-speed protocol interactions. Keepalived frameworks can be used independently or all together to provide resilient infrastructures."
Bingo! this is exactly what we need for our ProxySQL setup.
Below I will show how to setup:
- Simple solution base on a single VIP
- More complex solution using multiple VIPs
- Even more complex solution using virtual VIPs and virtual servers.
Just remind that what we want to achieve is to prevent ProxySQL to become a SPOF, that's it.
While achieving that we need to reduce as much as possible the network hops and keep the solution SIMPLE.
Another important concept to keep in mind is that ProxySQL (re)start take place in less then a second.
This means that if it crash and it can be restarted by the angel process, having it doing so and recovery the service is much more efficient than to have any kind of failover mechanism to take place.
As such whenever you plan your solution keep in mind the ~1 second time of ProxySQL restart as base line.
Ready?
Let's go.
Setup
Choose 3 machines that will host the combination of Keepalive and ProxySQL.
In the following example I will use 3 machines for ProxySQL and Keepalived and 3 hosting PXC, but you can have the Keepalived+ProxySQL whenever you like also on the same PXC box.
For the following examples we will have:
PXC
node1 192.168.0.5 galera1h1n5
node2 192.168.0.21 galera2h2n21
node3 192.168.0.231 galera1h3n31
ProxySQL-Keepalived
test1 192.168.0.11
test2 192.168.0.12
test3 192.168.0.235
VIP 192.168.0.88 /89/90
To check I will use this table, please create it in your MySQL server:
DROP TABLE test.`testtable2`;
CREATE TABLE test.`testtable2` (
`autoInc` bigint(11) NOT NULL AUTO_INCREMENT,
`a` varchar(100) COLLATE utf8_bin NOT NULL,
`b` varchar(100) COLLATE utf8_bin NOT NULL,
`host` varchar(100) COLLATE utf8_bin NOT NULL,
`userhost` varchar(100) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`autoInc`)
) ENGINE=InnoDB ROW_FORMAT=DYNAMIC;
And this bash TEST command to use later
while [ 1 ];do export mydate=$(date +'%Y-%m-%d %H:%M:%S.%6N');
mysql --defaults-extra-file=./my.cnf -h 192.168.0.88 -P 3311 --skip-column-names
-b -e "BEGIN;set @userHost='a';select concat(user,'_', host) into @userHost from information_schema.processlist where user = 'load_RW' limit 1;insert into test.testtable2 values(NULL,'$mydate',SYSDATE(6),@@hostname,@userHost);commit;select * from test.testtable2 order by 1 DESC limit 1" ;
sleep 1;done
- Install ProxySQL (refer to https://github.com/sysown/proxysql/wiki#installation)
- Install Keepalived (yum install keepalived; apt-get install keepalived)
- Setup ProxySQL users and servers
Once you have your ProxySQL up (run the same on all ProxySQL nodes, it is much simpler), connect to the Admin interface and:
DELETE FROM mysql_replication_hostgroups WHERE writer_hostgroup=500 ;
DELETE FROM mysql_servers WHERE hostgroup_id IN (500,501);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.0.5',500,3306,1000000000);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.0.5',501,3306,100);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.0.21',500,3306,1000000);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.0.21',501,3306,1000000000);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.0.231',500,3306,100);
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight) VALUES ('192.168.0.231',501,3306,1000000000);
LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK;
DELETE FROM mysql_users WHERE username='load_RW';
INSERT INTO mysql_users (username,password,active,default_hostgroup,default_schema,transaction_persistent) VALUES ('load_RW','test',1,500,'test',1);
LOAD MYSQL USERS TO RUNTIME;SAVE MYSQL USERS TO DISK;
DELETE FROM mysql_query_rules WHERE rule_id IN (200,201);
INSERT INTO mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply) VALUES(200,'load_RW',501,1,3,'^SELECT.*FOR UPDATE',1);
INSERT INTO mysql_query_rules (rule_id,username,destination_hostgroup,active,retries,match_digest,apply) VALUES(201,'load_RW',501,1,3,'^SELECT ',1);
LOAD MYSQL QUERY RULES TO RUNTIME;SAVE MYSQL QUERY RULES TO DISK;
Create a my.cnf file in your default dir with
[mysql]
user=load_RW
password=test
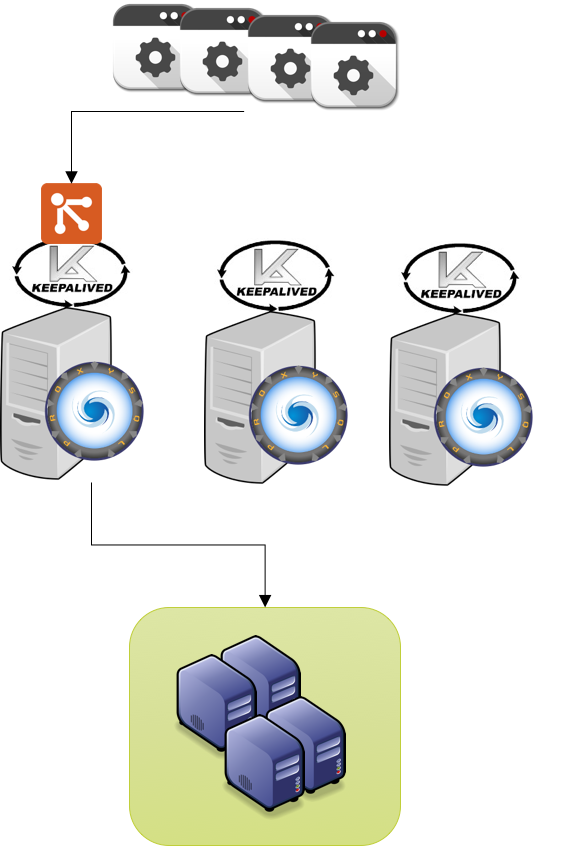
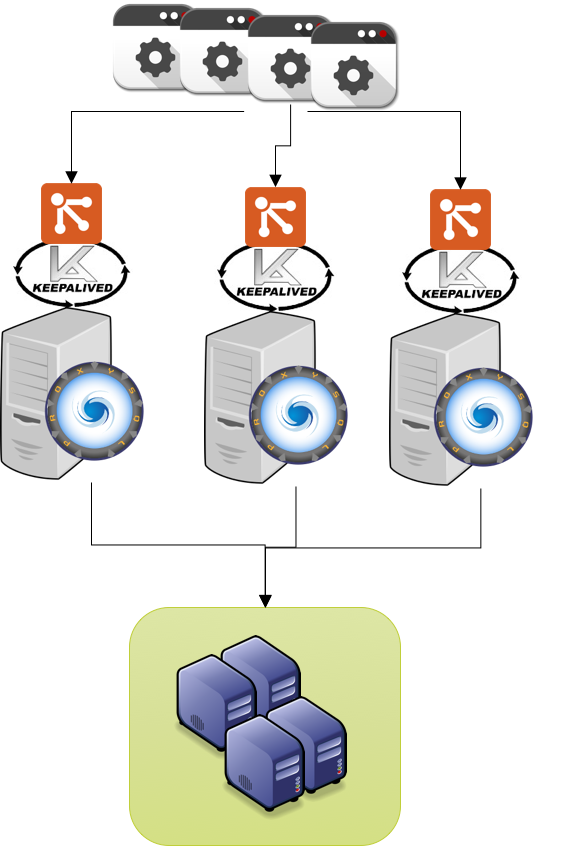
Simple Setup using a single VIP 3 ProxySQL 3 Galera nodes
![proxy_keep_single]()
First setup the keepalive configuration file (/etc/keepalived/keepalived.conf):
global_defs {
# Keepalived process identifier
lvs_id proxy_HA
}
# Script used to check if Proxy is running
vrrp_script check_proxy {
script "killall -0 proxysql"
interval 2
weight 2
}
# Virtual interface
# The priority specifies the order in which the assigned interface to take over in a failover
vrrp_instance VI_01 {
state MASTER
interface em1
virtual_router_id 51
priority <calculate on the WEIGHT for each node>
# The virtual ip address shared between the two loadbalancers
virtual_ipaddress {
192.168.0.88 dev em1
}
track_script {
check_proxy
}
}
Given the above and given I want to have test1 as main priority will be set as:
test1 = 101
test2 = 100
test3 = 99
Modify the config in each node following the above values and (re)start keepalived.
If all is set correctly in the system log of the TEST1 machine you will see:
Jan 10 17:56:56 mysqlt1 systemd: Started LVS and VRRP High Availability Monitor.
Jan 10 17:56:56 mysqlt1 Keepalived_healthcheckers[6183]: Configuration is using : 6436 Bytes
Jan 10 17:56:56 mysqlt1 Keepalived_healthcheckers[6183]: Using LinkWatch kernel netlink reflector...
Jan 10 17:56:56 mysqlt1 Keepalived_vrrp[6184]: Configuration is using : 63090 Bytes
Jan 10 17:56:56 mysqlt1 Keepalived_vrrp[6184]: Using LinkWatch kernel netlink reflector...
Jan 10 17:56:56 mysqlt1 Keepalived_vrrp[6184]: VRRP sockpool: [ifindex(2), proto(112), unicast(0), fd(10,11)]
Jan 10 17:56:56 mysqlt1 Keepalived_vrrp[6184]: VRRP_Script(check_proxy) succeeded
Jan 10 17:56:57 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) Transition to MASTER STATE
Jan 10 17:56:57 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) Received lower prio advert, forcing new election
Jan 10 17:56:57 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) Received higher prio advert
Jan 10 17:56:57 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) Entering BACKUP STATE
Jan 10 17:56:58 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) forcing a new MASTER election
...
Jan 10 17:57:00 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) Transition to MASTER STATE
Jan 10 17:57:01 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) Entering MASTER STATE <-- MASTER
Jan 10 17:57:01 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) setting protocol VIPs.
Jan 10 17:57:01 mysqlt1 Keepalived_healthcheckers[6183]: Netlink reflector reports IP 192.168.0.88 added
Jan 10 17:57:01 mysqlt1 avahi-daemon[937]: Registering new address record for 192.168.0.88 on em1.IPv4.
Jan 10 17:57:01 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) Sending gratuitous ARPs on em1 for 192.168.0.88
While in the other two:
Jan 10 17:56:59 mysqlt2 Keepalived_vrrp[13107]: VRRP_Instance(VI_01) Entering BACKUP STATE <---
Which means node is there as ... :D Backup.
Now is time to test our connection to our ProxySQL pool.
From an application node or just from your laptop.
Open 3 terminals and in each one:
watch -n 1 'mysql -h <IP OF THE REAL PROXY (test1|test2|test3)> -P 3310 -uadmin -padmin -t -e "select * from stats_mysql_connection_pool where hostgroup in (500,501,9500,9501) order by hostgroup,srv_host ;" -e " select srv_host,command,avg(time_ms), count(ThreadID) from stats_mysql_processlist group by srv_host,command;" -e "select * from stats_mysql_commands_counters where Total_Time_us > 0;"'
You will see that unless you are already sending queries to proxies, you have the Proxies just doing nothing.
Time to start the test bash as I indicate above.
If everything is working correctly you will see the bash command reporting this:
+----+----------------------------+----------------------------+-------------+----------------------------+
| 49 | 2017-01-10 18:12:07.739152 | 2017-01-10 18:12:07.733282 | galera1h1n5 | load_RW_192.168.0.11:33273 |
+----+----------------------------+----------------------------+-------------+----------------------------+
ID execution time in the bash exec time inside mysql node hostname user and where the connection is coming from
The other 3 running bash commands will show that ONLY the ProxySQL in TEST1 is currently getting/serving requests, because is the one with the VIP.
Like:
+-----------+---------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| hostgroup | srv_host | srv_port | status | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms |
+-----------+---------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
| 500 | 192.168.0.21 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 629 |
| 500 | 192.168.0.231 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 510 |
| 500 | 192.168.0.5 | 3306 | ONLINE | 0 | 0 | 3 | 0 | 18 | 882 | 303 | 502 |
| 501 | 192.168.0.21 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 629 |
| 501 | 192.168.0.231 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 510 |
| 501 | 192.168.0.5 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 502 |
+-----------+---------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+
+---------+---------------+-----------+-----------+-----------+---------+---------+----------+----------+-----------+-----------+--------+--------+---------+----------+
| Command | Total_Time_us | Total_cnt | cnt_100us | cnt_500us | cnt_1ms | cnt_5ms | cnt_10ms | cnt_50ms | cnt_100ms | cnt_500ms | cnt_1s | cnt_5s | cnt_10s | cnt_INFs |
+---------+---------------+-----------+-----------+-----------+---------+---------+----------+----------+-----------+-----------+--------+--------+---------+----------+
| BEGIN | 9051 | 3 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| COMMIT | 47853 | 3 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| INSERT | 3032 | 3 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| SELECT | 8216 | 9 | 3 | 0 | 3 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| SET | 2154 | 3 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
+---------+---------------+-----------+-----------+-----------+---------+---------+----------+----------+-----------+-----------+--------+--------+---------+----------+
So nothing special right, all as expected.
Time to see if the failover-failback works along the chain.
Let us kill the ProxySQL on TEST1 while the test bash command is running.
Here is what you will get:
+----+----------------------------+----------------------------+-------------+----------------------------+
| 91 | 2017-01-10 18:19:06.188233 | 2017-01-10 18:19:06.183327 | galera1h1n5 | load_RW_192.168.0.11:33964 |
+----+----------------------------+----------------------------+-------------+----------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.0.88' (111)
+----+----------------------------+----------------------------+-------------+----------------------------+
| 94 | 2017-01-10 18:19:08.250093 | 2017-01-10 18:19:11.250927 | galera1h1n5 | load_RW_192.168.0.12:39635 | <-- note
+----+----------------------------+----------------------------+-------------+----------------------------+
the source had change but not the PXC node.
If you check the system log for TEST1:
Jan 10 18:19:06 mysqlt1 Keepalived_vrrp[6184]: VRRP_Script(check_proxy) failed
Jan 10 18:19:07 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) Received higher prio advert
Jan 10 18:19:07 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) Entering BACKUP STATE
Jan 10 18:19:07 mysqlt1 Keepalived_vrrp[6184]: VRRP_Instance(VI_01) removing protocol VIPs.
Jan 10 18:19:07 mysqlt1 Keepalived_healthcheckers[6183]: Netlink reflector reports IP 192.168.0.88 removed
While on TEST2
Jan 10 18:19:08 mysqlt2 Keepalived_vrrp[13107]: VRRP_Instance(VI_01) Transition to MASTER STATE
Jan 10 18:19:09 mysqlt2 Keepalived_vrrp[13107]: VRRP_Instance(VI_01) Entering MASTER STATE
Jan 10 18:19:09 mysqlt2 Keepalived_vrrp[13107]: VRRP_Instance(VI_01) setting protocol VIPs.
Jan 10 18:19:09 mysqlt2 Keepalived_healthcheckers[13106]: Netlink reflector reports IP 192.168.0.88 added
Jan 10 18:19:09 mysqlt2 Keepalived_vrrp[13107]: VRRP_Instance(VI_01) Sending gratuitous ARPs on em1 for 192.168.0.88
Simple ... and elegant. No need to re-invent the wheel and works smooth.
The total time for the recovery given the ProxySQL crash had be of 5.06 seconds,
considering the wider window ( last application start, last recovery in PXC 2017-01-10 18:19:06.188233|2017-01-10 18:19:11.250927)
As such the worse scenario, keeping in mind we run the check for the ProxySQL every 2 seconds (real recover max window 5-2=3 sec).
OK what about fail-back?
Let us restart the proxysql service:
/etc/init.d/proxysql start (or systemctl)
Here the output:
+-----+----------------------------+----------------------------+-------------+----------------------------+
| 403 | 2017-01-10 18:29:34.550304 | 2017-01-10 18:29:34.545970 | galera1h1n5 | load_RW_192.168.0.12:40330 |
+-----+----------------------------+----------------------------+-------------+----------------------------+
+-----+----------------------------+----------------------------+-------------+----------------------------+
| 406 | 2017-01-10 18:29:35.597984 | 2017-01-10 18:29:38.599496 | galera1h1n5 | load_RW_192.168.0.11:34640 |
+-----+----------------------------+----------------------------+-------------+----------------------------+
Worse recovery time = 4.04 seconds of which 2 of delay because the check interval.
Of course the test is running every second and is running one single operation, as such the impact is minimal (no error in fail-back), and recovery longer.
But I think I have made clear the concept here.
Let see another thing... is the failover working as expected? Test1 -> 2 -> 3 ??
Let us kill 1 - 2 and see:
Kill Test1 :
+-----+----------------------------+----------------------------+-------------+----------------------------+
| 448 | 2017-01-10 18:35:43.092878 | 2017-01-10 18:35:43.086484 | galera1h1n5 | load_RW_192.168.0.11:35240 |
+-----+----------------------------+----------------------------+-------------+----------------------------+
+-----+----------------------------+----------------------------+-------------+----------------------------+
| 451 | 2017-01-10 18:35:47.188307 | 2017-01-10 18:35:50.191465 | galera1h1n5 | load_RW_192.168.0.12:40935 |
+-----+----------------------------+----------------------------+-------------+----------------------------+
...
Kill Test2
+-----+----------------------------+----------------------------+-------------+----------------------------+
| 463 | 2017-01-10 18:35:54.379280 | 2017-01-10 18:35:54.373331 | galera1h1n5 | load_RW_192.168.0.12:40948 |
+-----+----------------------------+----------------------------+-------------+----------------------------+
+-----+----------------------------+----------------------------+-------------+-----------------------------+
| 466 | 2017-01-10 18:36:08.603754 | 2017-01-10 18:36:09.602075 | galera1h1n5 | load_RW_192.168.0.235:33268 |
+-----+----------------------------+----------------------------+-------------+-----------------------------+
This image is where you should be at the end:
![proxy_keep_single_failover]()
In this case given I have done one kill immediately after the other, Keepalived had take a bit more in failing over, but still it did correctly and following the planned chain.
Fail-back as smooth as usual:
1
2
3
4
5
6
|
+-----+----------------------------+----------------------------+-------------+-----------------------------+
| 502 | 2017-01-10 18:39:18.749687 | 2017-01-10 18:39:18.749688 | galera1h1n5 | load_RW_192.168.0.235:33738 |
+-----+----------------------------+----------------------------+-------------+-----------------------------+
+-----+----------------------------+----------------------------+-------------+----------------------------+
| 505 | 2017-01-10 18:39:19.794888 | 2017-01-10 18:39:22.800800 | galera1h1n5 | load_RW_192.168.0.11:35476 |
+-----+----------------------------+----------------------------+-------------+----------------------------+
|
Let us see now another case.
The case above is nice and simple, but as a cavet.
I can access only one ProxySQL a time, which may be good or not.
In any case it may be nice to have the possibility to choose, and with Keepalived you can.
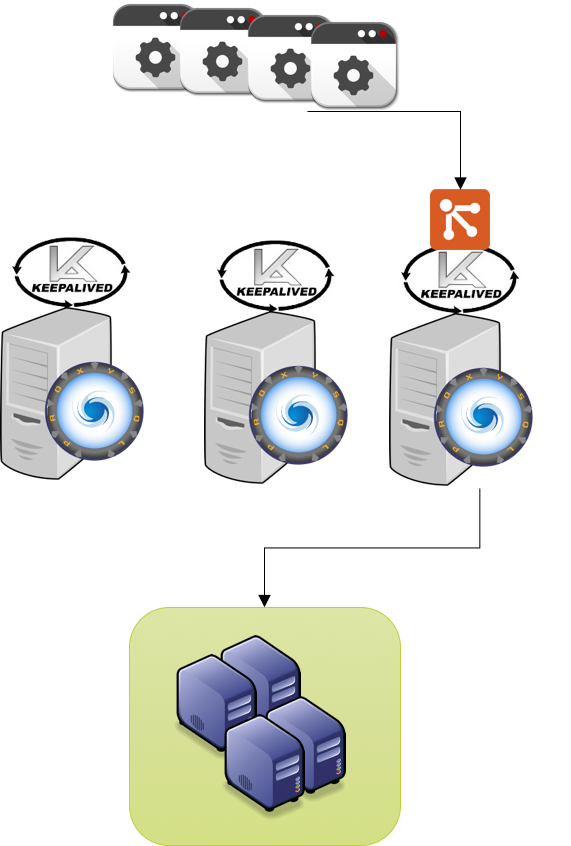
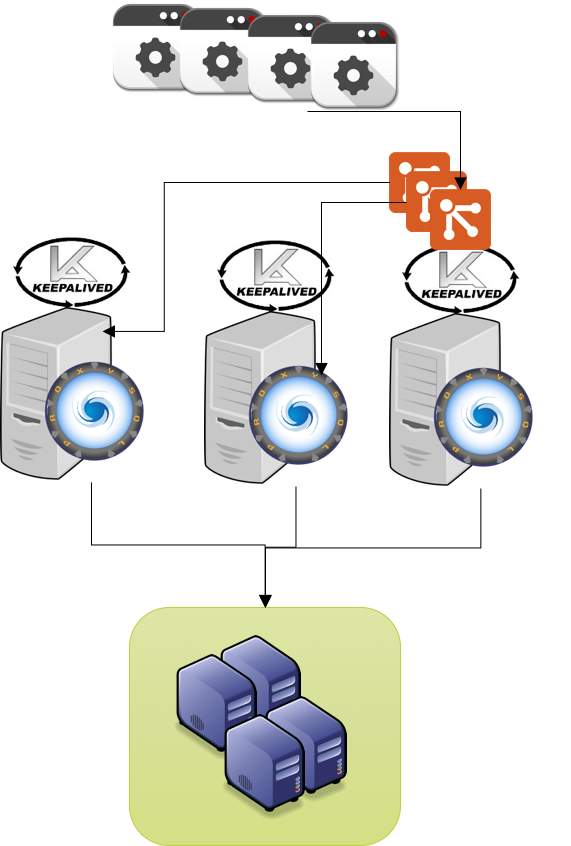
We can actually set an X number of VIP and associate them to each test box.
The result will be that each server hosting ProxySQL will also host a VIP, and will be eventually able to fail-over to any of the other two servers.
![proxy_keep_multiple]()
Failing-over/Back will be fully managed by Keepalived, checking as we did before if ProxySQL is running.
Example of configuration for one node can be the one below:
global_defs {
# Keepalived process identifier
lvs_id proxy_HA
}
# Script used to check if Proxy is running
vrrp_script check_proxy {
script "killall -0 proxysql"
interval 2
weight 3
}
# Virtual interface 1
# The priority specifies the order in which the assigned interface to take over in a failover
vrrp_instance VI_01 {
state MASTER
interface em1
virtual_router_id 51
priority 102
# The virtual ip address shared between the two loadbalancers
virtual_ipaddress {
192.168.0.88 dev em1
}
track_script {
check_proxy
}
}
# Virtual interface 2
# The priority specifies the order in which the assigned interface to take over in a failover
vrrp_instance VI_02 {
state MASTER
interface em1
virtual_router_id 52
priority 100
# The virtual ip address shared between the two loadbalancers
virtual_ipaddress {
192.168.0.89 dev em1
}
track_script {
check_proxy
}
}
# Virtual interface 3
# The priority specifies the order in which the assigned interface to take over in a failover
vrrp_instance VI_03 {
state MASTER
interface em1
virtual_router_id 53
priority 99
# The virtual ip address shared between the two loadbalancers
virtual_ipaddress {
192.168.0.90 dev em1
}
track_script {
check_proxy
}
}
The tricky part in this case is to play with the PRIORITY for each VIP and each server such that you will NOT assign the same ip twice.
The whole set of configs can be found here
Performing the check with the test bash as above we have:
Test 1 crash
+-----+----------------------------+----------------------------+-------------+----------------------------+
| 422 | 2017-01-11 18:30:14.411668 | 2017-01-11 18:30:14.344009 | galera1h1n5 | load_RW_192.168.0.11:55962 |
+-----+----------------------------+----------------------------+-------------+----------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.0.88' (111)
+-----+----------------------------+----------------------------+-------------+----------------------------+
| 426 | 2017-01-11 18:30:18.531279 | 2017-01-11 18:30:21.473536 | galera1h1n5 | load_RW_192.168.0.12:49728 | <-- new server
+-----+----------------------------+----------------------------+-------------+----------------------------+
....
Test 2 crash
+-----+----------------------------+----------------------------+-------------+----------------------------+
| 450 | 2017-01-11 18:30:27.885213 | 2017-01-11 18:30:27.819432 | galera1h1n5 | load_RW_192.168.0.12:49745 |
+-----+----------------------------+----------------------------+-------------+----------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.0.88' (111)
+-----+----------------------------+----------------------------+-------------+-----------------------------+
| 454 | 2017-01-11 18:30:30.971708 | 2017-01-11 18:30:37.916263 | galera1h1n5 | load_RW_192.168.0.235:33336 | <-- new server
+-----+----------------------------+----------------------------+-------------+-----------------------------+
Final state of IPs on Test3:
enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:c2:16:3f brd ff:ff:ff:ff:ff:ff
inet 192.168.0.235/24 brd 192.168.0.255 scope global enp0s8 <-- Real IP
valid_lft forever preferred_lft forever
inet 192.168.0.90/32 scope global enp0s8 <--- VIP 3
valid_lft forever preferred_lft forever
inet 192.168.0.89/32 scope global enp0s8 <--- VIP 2
valid_lft forever preferred_lft forever
inet 192.168.0.88/32 scope global enp0s8 <--- VIP 1
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fec2:163f/64 scope link
valid_lft forever preferred_lft forever
And this is the image:
![proxy_keep_multiple_full_failover]()
Recovery times:
test 1 crash = 7.06 sec (worse case scenario)
test 2 crash = 10.03 sec (worse case scenario)
Conclusions
In this example I had just use a test that checks the process, but a check can be anything reporting 0|1, the limit is define only from what you need.
The times for the failover can be significant shorter, reducing the check time and considering only the time taken to move the VIP, I had prefer to show the worse case scenario considering an application with a second interval, but that is a pessimistic view of what normally happens with real traffic.
I was looking for a simple, simple simple way to add HA to ProxySQL, something that can be easily integrate with automation and that is actually also well established and maintained.
In my opinion using Keepalived is a good solution because it match all the above expectations.
Implementing a set of ProxySQL and have Keepalived manage the failover between them is pretty easy, but you can expand the usage (and the complexity) if you need, counting on tools that are already part of the Linux stack, no need to re-invent the wheel with crazy mechanism.
If you want to have fun doing crazy things... at least start from something that helps you to go beyond the basiscs.
For instance I was also playing a bit with keepalived and virtual server, creating set of redundant Proxysql with load balancers and ... .. but this is another story (blog).
Great MySQL & ProxySQL to all!


 On February 3rd, just before Fosdem and the
On February 3rd, just before Fosdem and the 
















 What does that really mean ? In fact, when you are a website hosting provider, you host the website (apache, nginx) on vhosts and you share a database server in which every customer has access to their own schema for their website.
What does that really mean ? In fact, when you are a website hosting provider, you host the website (apache, nginx) on vhosts and you share a database server in which every customer has access to their own schema for their website. To avoid any problem, when using MySQL Group Replication in Multi-Primary node, it’s recommended to route all DDLs to the same node (this is not needed if you use the default
To avoid any problem, when using MySQL Group Replication in Multi-Primary node, it’s recommended to route all DDLs to the same node (this is not needed if you use the default 










 Don’t forget to
Don’t forget to 