Last week we proudly announced the first Release Candidate (RC) of MySQL 5.7. MySQL 5.7.7 includes additional enhancements and aggregates the Development Milestones Releases (DMRs) the MySQL team at Oracle previously delivered to the MySQL community. With the first Release Candidate, it’s more important than ever that we hear your feedback on the pre-GA version in order to help ensure very high quality for the GA release.
MySQL 5.7 is an extremely exciting new version of the world’s most popular open source database that is 2x faster than MySQL 5.6, while also improving usability, manageability, and security. Some key enhancements include:
- Performance & Scalability: Improved InnoDB scalability and temporary table performance, enabling faster online and bulk load operations, and more.
- JSON Support: Native JSON support (JSON Labs Release).
- Replication improvements for increased availability and performance. They include multi-source replication, multi-threaded slave enhancements, online GTIDs, and enhanced semi-sync replication.
- Performance Schema delivering much better insights. We’ve added numerous new monitoring capabilities, reduced the footprint and overhead, and significantly improved ease of use with the new SYS Schema.
- Security: We are fulfilling “secure by default” requirements and many new MySQL 5.7 features will help users keep their database secure.
- Optimizer: We have rewritten large parts of the parser, optimizer, and cost model. This has improved maintainability, extendability, and performance.
- GIS: Completely new in MySQL 5.7 and including InnoDB spatial indexes, use of Boost.Geometry, along with increased completeness and standard compliance.
The above represents some of the highlights and I encourage you to further drill into the complete series of Milestone blog posts—5.7.1, 5.7.2, 5.7.3, 5.7.4, 5.7.5, 5.7.6, 5.7.7—and even further down in to the individual worklogs with their specifications and implementation details. Or perhaps you prefer to just look at the source code at github.com/mysql. We have implemented 317 worklogs, added 816 MTR tests, and fixed 1476 5.7-specific bugs in 5.7. It might all be a bit overwhelming, so this “little” guide might be useful.
A big THANK YOU to everyone in the development team that made this happen! By development I mean everyone: requirements, design, coding, reviewing, testing, bug fixing, documentation, release, and lab support. A real team effort.
Performance & Scalability
Performance and scalability is a priority for MySQL, learning from community feedback and taking into account trends and developments in computer hardware and its architecture. So far in 5.7 we have delivered impressive read-only (RO) scalability results with InnoDB and significantly sped up the connection handling in the server layer. We are also making good progress on InnoDB read-write (RW) scalability, improved internal operations (faster and more stable flushing/purging), and fast bulk data loads.
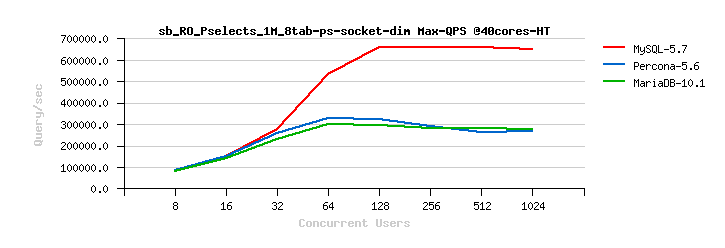
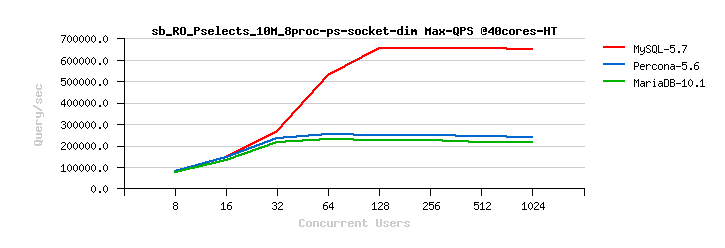
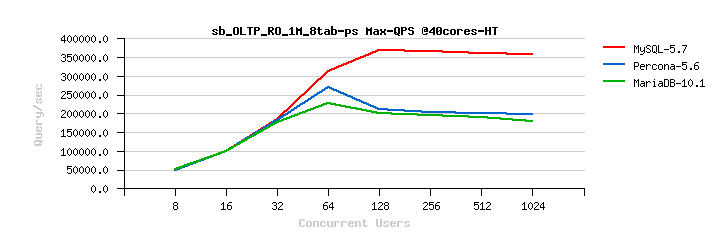
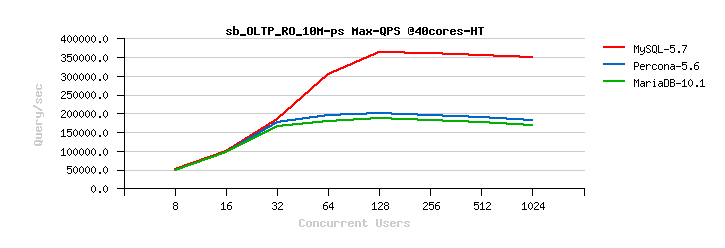
InnoDB Read-Only Scalability. We have improved the performance for Read-Only (RO) and Read-Mostly workloads. We have significantly improved how InnoDB handles RO transactions (WL#6047, WL#6899, WL#6906, WL#6578). We have also removed server layer contentions related to Meta Data Locking (MDL) and removed the use of THR_LOCK locks for InnoDB (WL#7304, WL#7305, WL#7306, WL#6671). After WL#6671, the LOCK_grant lock then became more visible as the next scalability bottleneck in some workloads; for example, the single table InnoDB POINT_SELECT Sysbench tests (see also Bug#72829). This has now been fixed by partitioning the LOCK_grant lock (see WL#8355). Finally we have removed bottlenecks around LOCK_plugin and THR_LOCK_lock in workloads which involve the creation of internal memory based temporary tables; for example, like Sysbench’s SELECT_DISTINCT test for InnoDB. There is no real reason why we should acquire these locks for internal temporary tables, so we removed this unnecessary overhead (see WL#8356). See also Dimitri Kravtchuk’s articles “MySQL Performance: reaching 500K QPS with MySQL 5.7“, “MySQL 5.7 : Over 1M QPS with InnoDB Memcached Plugin“, Sunny Bains’ article “Transaction life cycle improvements in 5.7.3“, and Jimmy Yang’s article “MySQL 5.7.3: Deep dive into 1mil QPS with InnoDB Memcached“.
InnoDB Read-Write Scalability. We have also improved the performance of Read-Write (RW) workloads. We have removed the “index lock contention” in InnoDB (WL#6363, WL#6326). The index lock that was used to protect the entire index tree structure is now replaced by more fine grained “block locks” in the tree. See Yasufumi Kinoshita’s article “MySQL-5.7 improves DML oriented workloads“.
InnoDB Faster & Parallel Flushing. We have reduced the number of pages scanned when doing flush list batches, speeding up page flushing (WL#7047). The time complexity of a scan is reduced from O(n*n) to O(n). We have also implemented parallel flushing by having multiple page_cleaner threads (WL#6642). This gives improved scalability and throughput on multi-core systems and avoids flushing becoming the bottleneck. Finally, we have improved the adaptive flushing algorithm and related mechanisms in order to achieve more consistent or smooth throughput (see WL#7868).
Speeding up Connection Handling. In some application scenarios (e.g. PHP applications) client connections have very short life spans, perhaps only executing a single query. This means that the time spent processing connects and disconnects can have a large impact on the overall performance. In 5.7 we have offloaded thread initialization and network initialization to a worker thread (WL#6606) and more than doubled MySQL’s ability to do high frequency connect/disconnect cycles, from 26K to 56K connect/disconnect cycles per second. See also Jon Olav Hauglid’s article “Improving connect/disconnect performance“.
Bulk Data Load Improvements. Bulk Load for Create Index (WL#7277). This work implements bulk sorted index builds, thus making CREATE INDEX operations much faster. Prior to this work InnoDB looped through the base table and created one index record at a time for each record in the base table. After this work InnoDB reads many records from the base table, sorts the records using the index key, and then creates a chunked set of index records in one single bulk operation.
Online Operations
“Always ON” properties are essential to state of the art web solutions. It is important for DBAs or DevOps to be able to tune and extend their production systems without interrupting service. Thus, we continue to ensure that MySQL is leading in this area. So far in 5.7 we have delivered the following:
We have provided a way to enable GTIDs online (WL#7083), so that reads and writes are allowed during the procedure, servers do not need to synchronize, and no restarts are necessary. Prior to this work, the user had to stop all updates, synchronize all servers, and then restart all of them simultaneously. This previously meant that enabling GTIDs implied several minutes of planned downtime. See Sven Sandberg’s article “Enabling Global Transaction Identifiers Without Downtime in MySQL 5.7.6“.
We have added the capability to change the value of innodb_buffer_pool_size dynamically (WL#6117). This provides the ability to tune the buffer pool size—without incurring any downtime—as your database usage patterns evolve over time. See Yasufumi Kinoshita’s article “Resizing the InnoDB Buffer Pool Online“.
We have implemented automatic truncation of UNDO logs when separate UNDO tablespaces have been configured (WL#6965). InnoDB operates with several UNDO tablespaces that are periodically truncated, one at a time. While one UNDO tablespace is being truncated, the other UNDO tablespaces will still be available to service transaction management and ensure minimal impact on transaction processing. The purpose of this work is to avoid ever growing UNDO log file sizes that could occur in some usage scenarios. See also Bug#1287 reported by Scott Ellsworth.
We have added support for online ALTER TABLE RENAME INDEX (WL#6752, WL#6555) and enlarge VARCHAR column size operations (WL#6554).
We have made the slave options --replicate-* settable via the new CHANGE REPLICATION FILTER command (WL#7057). These options can now be changed dynamically while the server is running, enabling users to modify replication filtering rules without requiring a server stop and restart. This work originates in a contribution from Davi Arnaut (Bug#67362). See also Venkatesh Duggirala’s article “Making MySQL Slave Replication Filters Dynamic“.
And we have made it possible to issue CHANGE MASTER without stopping replication (WL#6120). In order to add/alter an option using the CANGE MASTER TO command, it was previously necessary to issue a STOP SLAVE command before the CHANGE MASTER TO command. This work relaxes that constraint. See also Shivji Jha’s article “Change master without stopping slave altogether“.
Optimizer Improvements
Many exciting things are going on in the optimizer area, such as the new Cost Model work, a new and improved parser, a layered optimizer architecture, and a new GIS implementation. In addition we have implemented the following set of feature requests:
Generated Columns (WL#411) : We have implemented Generated Columns. The values for such columns, unlike a regular field’s value, aren’t set by the user but instead computed by the server when the row is created or updated, using the expression specified by the user as part of the table definition. See Evgeny Potemkin’s article “Generated Columns in MySQL 5.7.5“.
Query Rewrite Plugins (WL#7589) : We have implemented a Query Rewrite Plugin, as well as a framework (APIs) for people to write their own custom query rewrite plugins. A query rewrite plugin specifies how certain queries that arrive at the server should be rewritten before they are processed and executed by the server. One usage is to enforce/prevent a certain query plan by adding hints to a query. Our query rewrite plugin is a superb tool for handling such problematic queries when users cannot rewrite the query within the application itself, e.g. because it originates from an external tool (like an Object Relational Mapping tool such as Hibernate) or from some other 3rd party application. See also Martin Hansson’s article “Write Yourself a Query Rewrite Plugin: Part 1” and “Part 2“.
Process subqueries in FROM clause in the same way as view (WL#5275) : We have to a large extent unified the handling of derived tables and views. Until now, subqueries in the FROM clause (derived tables) were unconditionally materialized, while views created from the same query expressions were sometimes materialized and sometimes merged into the outer query. This behavior, beside being inconsistent, can lead to a serious performance penalty. This work fixes Bug#59203, Bug#67631, and Bug#1275.
Make switching of index due to small limit cost-based (WL#6986) : We have made the decision in make_join_select() of whether to switch to a new index in order to support "ORDER BY ... LIMIT N" cost-based. This work fixes Bug#73837.
Improved “IN queries” With Row Value Expressions to Be Executed Using Range Scans (WL#7019) : We removed the previous requirement on rewriting the WHERE condition into its equivalent AND/OR form. See Bug#31188 reported by Mark Callaghan and Bug#16247 reported by Domas Mituzas. See also Martin Hansson’s article “Range access: now in an IN predicate near you“.
“UNION ALL” No Longer Creates a Temporary Table (WL#1763) : In 5.7 the optimizer avoids creating a temporary table for the result of UNION ALL queries when there is no need for it, i.e. when there is no top-level ORDER BY clause. This reduces the need for disk space and disk I/O when executing large unions, and perhaps even more important, the client will get the first rows immediately. See Bug#50674 reported by Mark Callaghan. See also Norvald H. Ryeng’s article “State of the UNION“.
Non-Sorted Fields in the Sort Buffer are Now Compacted (WL#1509) : This optimization is about better utilizing the sort buffer, thus avoiding/reducing the need to go to disk while sorting. The user benefit is increased query performance.
EXPLAIN for Running Queries (WL#6369) : This feature is useful if you are running a statement in one session that is taking a long time to complete; using EXPLAIN FOR CONNECTION in another session may yield useful information about the cause of the delay and thus help you optimize your schema and statements.
JSON EXPLAIN (WL#6510) : We have enhanced the JSON EXPLAIN output by printing the total query cost, the cost per table, and the amount of data processed. This will make it easier for a user to see the difference between good and bad execution plans. See also Øystein Grøvlen’s article “MySQL EXPLAIN Explained“.
Make Use of Condition Filtering in the Optimizer (WL#6635) : This work improves join ordering. It provides a much better prefix rows estimate by taking into account not only conditions that are used by the chosen access method, but all other relevant conditions as well. See Jørgen Løland’s articles “A New Dimension to MySQL Query Optimization” part 1 and part 2.
Improved ONLY_FULL_GROUP_BY SQL Mode (WL#2489) : We have improved the behavior of the ONLY_FULL_GROUP_BY SQL mode and also enabled it by default in 5.7.5+. This work makes the SQL mode far less strict about selected/order expressions because the server now properly recognizes functional dependencies. This work addresses many user complaints, such as those described in Roland Bouman’s article “Debunking GROUP BY myths” and Bug#51058. See also Guilhem Bichot’s article “MySQL 5.7: only_full_group_by Improved, Recognizing Functional Dependencies, Enabled by Default!“.
Parser Refactoring
We are in the process of refactoring the SQL parser in an incremental way. The old parser had critical limitations because of its grammar complexity and top-down parsing style which lead to poor maintainability and extensibility. So far we have done a lot of preparatory work (WL#5967, WL#7199), refactored the SELECT statement (WL#7200), the SET statement (WL#7203), the INSERT/REPLACE statement (WL#7201), the DELETE statement (WL#7202), and the UPDATE statement (WL#8062). We plan to rewrite the entire parser. See the article by Gleb Shchepa “SQL parser refactoring in 5.7.4 LAB release“.
Optimizer Hints
We have added parser rules to support a new hint syntax for optimizer hints (WL#8016). Hints can now be specified directly after the SELECT|INSERT|REPLACE|UPDATE|DELETE keywords in an SQL statement, and they must be enclosed in /*+ */ style comments. Not only does this provide the end-user with a more consistent and easy to use method of managing hints, but the internal refactoring done makes it far easier to add Server side support for additional hints moving forward (see WL#8241 and WL#8243 below). We have also implemented the general infrastructure (WL#8017) common to all hints given the new syntax (see WL#8016). This includes: 1. a data structure for associating hints with the relevant query block during parsing 2. utility functions for resolving the names of database objects (e.g. table names, index names, etc.) and associating the hints with the relevant objects 3. a data structure that the Optimizer can use to look up hints within the current query.
We have added new “index level hints” that allow the user to control which indexes should be candidates for index condition pushdown (ICP), multi-range read (MMR), and range optimization (WL#8243). We have also added new hints that allow the user to influence the Optimizer as it decides whether to use join buffering or batched key access during the execution of the query against the given set of tables (WL#8241).
Optimizer Refactoring
Previously the phases of parsing, optimizing, and execution were all intermixed. Almost every module was spread over different parts and sections of the optimizer. As a consequence, the cost of maintaining the codebase was high and extensibility poor. We started out on an optimizer refactoring project with the goal of a clear separation of these phases. With a refactored code base, the optimizer will be able to evolve much faster. For example, we see this as a prerequisite for improving our Prepared Statements. See WL#6016, WL#6042, WL#7082, WL#7540, and WL#7870. See also Guilhem Bichot’s article “Re-factoring some internals of prepared statements in 5.7“.
Work towards a New Cost Model
We want to improve the cost based optimizer and replace existing heuristics with cost based decisions. We want to produce better cost estimates which also take into account new hardware architectures (larger buffers, caches, SSDs, etc.). Better cost estimates will lead to better decisions by the optimizer and thus to better query performance. We have started to refactor the existing cost model code and to remove hard-coded constants. This will make the code more maintainable and make it possible to tune and configure the cost model for your particular hardware configuration, as well as laying the groundwork for storage engines to provide costs that factor in whether the data requested resides in memory or on disk. So far we have done preparatory infrastructure work and removed hard coded cost constants. These are now replaced by configurable cost values that can be changed by the user, without touching the source code, and that can be adjusted by the server administrator. (WL#7182, WL#7209, WL#7338, WL#5869, WL#6068, WL#7339, WL#7276, WL#7315, WL#7316). We have also extended the handler interface with a new API to provide estimates for how much of table and index data is in main memory. It also contains a default implementation that will be used if the storage engine does not provide this information (WL#7168). See also Jørgen Løland’s article “The MySQL Optimizer Cost Model Project“.
InnoDB Fulltext Search
We introduced InnoDB Fulltext Search in 5.6. We have now added greater flexibility and further optimizations. For example, fulltext indexes in InnoDB now support an external parser just like MyISAM (WL#6943). The plugin can either replace the built-in parser or it can act as a front-end for it. See also Feature requests from Daniel van Eeden (Bug#68816) and Hartmut Holzgraefe (Bug#70400). We have also implemented optimizer hints that are passed down to InnoDB about a query so that InnoDB may skip part of the full text search processing, e.g. not to compute the ranking values if they are not needed (WL#7123). See Shaohua Wang’s article “InnoDB supports plugin parser in fulltext index” and Matt Lord’s article “Rankings with InnoDB Full-Text Search“.
We have also implemented CJK (Chinese, Japanese, and Korean) support for InnoDB Full-Text Search (WL#6607) : This work provides a default fulltext parser for CJK (N-GRAM support) and an alternative plugin which provides MeCab support for Japanese. Users can also implement their own pluggable fulltext parser for CJK using the pluggable parser support. See also Shaohua Wang’s two articles “InnoDB Full-Text : N-gram Parser” and “InnoDB Full-Text: MeCab Parser“.
Performance Schema
Monitoring is important to our users and customers, and essential to any data management system. Our goal is to be “best in class” in this space. At the core of our monitoring strategy we have Performance Schema, which was first introduced in MySQL 5.5. Performance Schema is a specialized MySQL Storage Engine built for the special purpose of storing dynamically created events, and at the same time providing a uniform well known SQL interface to events and their configuration. In 5.7 we continue to extend and enhance our monitoring, utilizing the Performance Schema infrastructure. We have instrumented Metadata Locking (WL#5879), Transactions (WL#5864), Memory Usage (WL#3249, WL#7777), Stored Programs (WL#5766), and Prepared Statements (WL#5768).
We have exposed SHOW SLAVE STATUS information (WL#3656) and user variables (WL#6884) in Performance Schema. We also expose the GLOBAL and SESSION level STATUS and VARIABLES (WL#6629) while preserving the corresponding SHOW STATUS and SHOW VARIABLES commands for backward compatibility. We have also enabled progress reporting for long running operations (WL#5889) .
We have changed the way performance schema does memory allocations (WL#5889) . Previously, the Performance Schema allocated all of the memory it needs up front when the server starts. We are now automatically scaling the memory consumption to match the actual server load, thus reducing overhead (WL#7802). We have also reduced memory usage by refactoring Performance Schema’s internal buffers so that the memory overhead for the table instrumentation scales better when the number of tables in the database is large (WL#7698) .
We have improved ease-of-use by allowing user/host exclusion (WL#7800) . To allow this, a new column named ENABLED has been added to the setup_actors table to provide users with the ability to specify exclusion as well as inclusion rules. We have made the two entities related to Query Text Length—SQL text and digest—configurable (WL#7270). The default for both remains at 1024 bytes.
See also Mayank Prasad’s articles “Performance Schema implementation Internals: Registering instruments“, “MySQL Performance Schema : Prepared Statements Instrumentation“, “MySQL Performance Schema: Instrumentation Exceptions“, and “MySQL Statement Digests“.
SYS Schema
We have integrated the SYS Schema (formerly ps_helper) within the MySQL Server by default (WL#8159). The MySQL SYS schema project has become increasingly popular within our user base over the last year. Many DBAs and developers within our user base noted that it brought some needed simplicity to configuring and querying the Performance Schema, integrating it with Information_Schema, and more. For example, see a community post here. See also Mark Leith’s article “The MySQL SYS Schema in MySQL 5.7.7“.
Fabric Support
Oracle announced GA for MySQL Fabric on May 27, 2014. The Server team is working on some features to improve sharding, failover, and management of server farms. We have implemented a new server method for clearing session state (WL#6797). It is now possible for a client to do a reset of the existing connection, i.e. to clean the existing session context and free up resources. We have also implemented a new server method to bring servers off line (WL#3836). The intended usage is for upgrades and other maintenance purposes. Setting the server to offline mode will gracefully disconnect all connected clients except those with the SUPER privilege. “Super” users are allowed to connect and manage the system while in offline mode.
Secure by Default
MySQL 5.7 aims to be the most secure MySQL Server release ever, and that means some significant changes around SSL/TLS and work to secure deployments overall.
MySQL deployments are now secure by default (WL#6962). The installation process creates only a single root account,
root@localhost
, automatically generates a random password for this account, and marks the password as expired. The MySQL administrator must then connect as root using the generated random password and use the
SET PASSWORD command to set a new password .
The installation process creates no anonymous user accounts, no test database, and no demo related files by default (WL#6977, WL#6973). Secure deployments, initially done for Oracle Linux, has been extended to all other Unix variants and Unix like operating systems in WL#7787. The test database and the demo related files is included as a separate package.
We have simplified the server bootstrap process and removed the need for the mysql_install_db script (WL#7307). Simply specifying --initialize on the server command line is now enough to create a database directory if it’s absent, and then initialize it. The --initialize option also creates the user with a strong random and expired password.
We have restricted the scope of the FILE privilege to a secure default value for --secure-file-priv (WL#6782). The server will also warn users of insecure configurations for --secure-file-priv at start-up time.
We have redefined the client --ssl option to imply enforced encryption (WL#6791). Before, when a MySQL client specified the --ssl option a connection could still happen without encryption being enforced. Now if specified, and no SSL connection is available, the connection will instead fail. We have also added SSL support for mysqlbinlog (WL#7198).
We provide a “best effort” SSL setup process during installation. If successful, the MySQL server configuration file is also modified to reference the newly generated SSL certs and keys (WL#7706). We ensure the use of SSL whenever it has been enabled within the Server (WL#7712). If none of the SSL options are specified, the libmysql client will attempt an SSL connection if it is supported by the Server. If an SSL connection is not possible, however, then libmysql client will fall back to an unencrypted connection. See also Todd Farmer’s article “SSL/TLS in MySQL 5.7” and “Implications of TLS plans for third-party products“.
We have changed the default value of sql_mode to include NO_AUTO_CREATE_USER (WL#8326)
Security Features
In addition to “secure by default” installations we we have added many features that help users keep their database instances free from unintended use. This includes better data encryption, better password handling, better transport layer security, and more.
We now support multiple AES Encryption modes (WL#6781). We have enhanced the security strength of our Advanced Encryption Standard (AES) encryption/decryption functions—AES_ENCRYPT() and AES_DECRYPT()—by adding support for larger key sizes and different block modes. See also Georgi Kodinov’s article “Understand and satisfy your AES encryption needs with 5.6.17“.
We have added a timestamp field to the mysql.user table on the last time the password was changed (WL#7131). This work provides the means for implementing password rotation policies. See Todd Farmer’s article “Implementing a password policy in MySQL“.
We have made it possible to enable (unlock) or disable (lock) a user account (login permission) by extending the CREATE USER and ALTER USER commands (WL#6054). See Todd Farmer’s article “Building a better CREATE USER command“.
We have extended the built-in authentication plugins to support proxy users (WL#7724). MySQL had an existing concept of proxy users which can support a major use case that is typically met by SQL Roles: the ability to abstract user credentials/identity from the privileges assigned. This allows multiple users—identified, logged, and audited in a distinct manner—to share a single set of managed privileges. For deployments with many users having identical privileges, this can provide major operational benefits, but until now, proxy users could only be leveraged by external authentication plugins. This work removes that previous limitation. See Todd Farmer’s article “Emulating roles with expanded proxy user support in 5.7.7“.
InnoDB Native Partitioning
We have added native partitioning support to InnoDB (WL#6035). Until now, partitioning support for InnoDB has relied on the ha_partition handler, which created a new handler for each partition, which in turn wasted a lot of resources when using many partitions. By supporting native partitioning within InnoDB one can use far fewer overall resources (see also: bug#62536, bug#37252, and bug#70641). InnoDB native partitioning also paves the way for better overall partitioning. That would include things such as parallel query processing, improved partition pruning (due to more accurate index statistics), foreign key support, global secondary indexes, and full-text searches on partitioned tables. As part of this work have also separated the partitioning specific parts of the handler class into its own partitioning interface (WL#4807). This is refactoring done to modularize and decouple the partitioning engine from the rest of the server code base.
Furthermore, we have added support for Index Condition Pushdown (ICP) for partitioned tables (WL#7231, motivated by Bug#70001). We have added support for the [{WITH| WITHOUT} VALIDATION] clause to the EXCHANGE PARTITION command (WL#5630, motivated by Bug#57708). We have added support for transportable tablespaces for partitioned InnoDB tables (WL#6867, WL#6868). See also Mattias Jonsson’s article “MySQL 5.7.4 now supports Transportable Tablespaces for InnoDB Partitions“.
InnoDB General Tablespaces
We have added the ability for InnoDB to create a general tablespace using the CREATE TABLESPACE syntax (WL#6205, WL#8109). This work gives the user the freedom to choose their own mapping between tables and tablespaces, i.e. which tablespaces to create and what tables they should contain. This provides the means for doing things such as grouping all tables for a given user or customer within a single tablespace, and thus having all of their data within a single file on the filesystem. We have also implemented meta data locking (MDL) for general tablespaces (WL#7957). This is specifically needed for the new general tablespaces in InnoDB, and for the already existing NDB Cluster general tablespaces.
InnoDB Temporary Table Performance
One of the goals of 5.7 is to optimize for better performance for normal SQL temporary tables. First, we made temp table creation and removal a more light-weight operation by avoiding the unnecessary step of persisting temp table metadata to disk. We moved temp tables to a separate tablespace (WL#6560) so that the recovery process for temp tables becomes a single stateless step by simply re-creating it at start-up. We removed unnecessary persistence for temp tables (WL#6469). Temp tables are only visible within the connection/session in which they were created, and they are bound by the lifetime of the server. We optimized DML for Temp Tables (WL#6470) by removing unnecessary UNDO and REDO logging, change buffering, and locking. We added an additional type of UNDO log (WL#6915), one that is not REDO logged and resides in a new separate temp tablespace. These non-redo-logged UNDO logs are not required during recovery and are only used for rollback operations.
Second, we made a special type of temporary tables which we call “intrinsic temporary tables” (WL#7682, WL#6711). An intrinsic temporary table is like a normal temporary table but with relaxed ACID and MVCC semantics. The purpose is to support internal use cases where internal modules such as the optimizer demand light-weight and ultra-fast tables for quick intermediate operations. We then made the optimizer capable of using InnoDB “intrinsic temporary tables” for internal storage (WL#6711). Finally, we made InnoDB the default engine used for the internal temporary tables (WL#6737). See Krunal Bauskar’s article “MySQL 5.7: InnoDB Intrinsic Tables“.
Buffer Pool—Dump and Load
We have improved both the buffer pool dump and load scenarios (WL#6504). It is now possible to dump only the hottest N% of the pages from each buffer pool. The load operation is also made less disruptive to user activity because the load now happens in the background while continuing to serve clients; while also attempting not to be too aggressive and taking too much IO capacity away from servicing new client requests. See also Tony Darnell’s article “MySQL Dumping and Reloading the InnoDB Buffer Pool”.
We have also changed the server to use the buffer pool dump and load feature by default and changed the default percentage to 25% (WL#8317). This offers a good default balance between 1. supporting a “hot” working data set and 2. shutdown and startup times.
Tools
The Server comes with a set of utility programs or scripts (tools). The general direction is to improve and add more tools. We also want to move away from “scripts” and over to C/C++ to improve on portability and cover more usage scenarios (one cannot run scripts in all environments).
We have significantly extended the innochecksum utility’s functionality (WL#6045). It is now possible to specify the checksum algorithm (innodb/crc32/none), rewrite the current checksum using the specified algorithm, rewrite the checksum even if the current checksum is invalid, and specify the maximum checksum mismatch allowed before terminating the program. innochecksum can also now operate on multiple tablespace files and on multiple files in the same tablespace. See Anil Toshniwal’s article “Improving Innochecksum“.
We have rewritten the mysql_upgrade tool (WL#7308), which fixes many reported bugs while also making mysql_upgrade more robust and easier to maintain. For example, this work fixes Bug#65288 reported by Nicholas Bamber and Bug#71579 reported by Florian Weimer.
We have added SSL options and support for the mysqlbinlog client program (WL#7198), allowing system administrators to perform remote binlog queries (--read-from-remote-server) over secure connections. This was previously the last remaining MySQL client program without SSL support.
We have converted mysql_secure_installation script to C/C++ (WL#6441). This program can now connect to the server directly and execute the specified commands using the C API (libmysql). This removes the need for storing the user supplied password in a temporary option file on the filesystem.
We started out with converting the mysql_install_db script to C/C++ (WL#7688), to make the program usable on all platforms—particularly on Windows—while also redesigning the program to provide a better user experience, cover more functionality, and improve security. Later in the 5.7 cycle we decided to fold this functionality into the server itself (see WL#7307). The mysql_install_db program is in 5.7, it can be used but is no longer needed, and we plan to remove it in a future release.
Community Contributions
Server-side statement timeouts (WL#6936) : This work is based on a contribution submitted by Davi Arnaut (Bug#68252). The work implements a server-side time limit for the execution of top-level read-only SELECT statements. After the specified amount of time, the statement will be aborted without affecting the session (connection) or the transaction contexts. See Praveen Hulakund’s article “Server-side SELECT statement timeouts“.
Multiple User Level Locks : Allow multiple locks in GET_LOCK() (WL#1159). User-level locks are often used to organize mutual exclusion when accessing some resource in cases when table or row-level locks are not appropriate. This work allows for multiple user level locks per connection. The work is based on a contribution by Konstantin Osipov (Bug#67806). See Dmitry Lenev’s article “The Story of One Contribution“.
Triggers
BEFORE Triggers Are Not Processed for NOT NULL Columns (WL#6030) : This work ensures that we check column constraints at the end of the SQL statement. This is in compliance with the SQL standard. In 5.6 and earlier, MySQL checks the column constraints too soon. See Bug#6295 reported by Peter Gulutzan, and Dmitry Shulga’s article “BEFORE triggers and NOT NULL columns in MySQL“.
Multiple Triggers Per Table (WL#3253) : This work provides the ability to have more than one trigger for every action (INSERT, UPDATE, DELETE) and timing (BEFORE or AFTER). This is in accordance with the SQL standard. See Dmitry Shulga’s article “Support for multiple triggers per table for the same value of action/timing“.
IGNORE Clause
Define and Reimplement IGNORE (WL#6614) : This work properly defines the meaning and handling of the IGNORE clause, a MySQL extension to the SQL standard. It reimplements IGNORE so that it is consistent across all supported SQL statements while also making it much easier to maintain. See also Bug#30191, Bug#49539, Bug#55421, Bug#54543, Bug#54106, Bug#49534, Bug#47788, Bug#46539, and Bug#46425. See also Abhishek Ranjan’s article “Improvements to the MySQL IGNORE Implementation“.
STRICT Mode
Define and Reimplement STRICT Mode (WL#6891) : We have made STRICT MODE behaviour consistent across all supported SQL statements. We have also made STRICT MODE the default for all transactional storage engines (WL#7764). The IGNORE clause downgrades errors to warnings to allow statements to skip row(s) which would have otherwise have caused the entire statement to abort. STRICT MODE does just the opposite—it upgrades warnings to errors. Similar to IGNORE, STRICT MODE has not previously been clearly and consistently defined, thus the implementation has been the source of many bugs like Bug#42910, Bug#5929, Bug#43880, Bug#48637, Bug#5912, and Bug#5913. See also Abhishek Ranjan’s article “Improvements to STRICT MODE in MySQL“.
Error Reporting & Logging
Introduce a separate error code range for 5.7 (WL#8206) : This work implements a separate range of numbers for new server error messages introduced in 5.7. These codes are currently numbered consecutively, starting at 1000. We also have a second range of error codes used by the client, starting at 2000. The problem is that the first range of codes is currently up to 1974 which means that the two ranges would soon overlap, making it hard to differentiate between server and client errors. The new 5.7 server error codes will now instead start at 3000.
Error Reporting — Stacked Diagnostic Areas (WL#6406) : This work implements support for stacked diagnostic areas as defined by the SQL standard. The GET DIAGNOSTICS statement has been extended to support GET [STACKED] DIAGNOSTICS.
Error Reporting — Most Statements Should Clear the Diagnostic Area (WL#5928) : This work makes MySQL follow the SQL standard with respect to clearing the diagnostic area. This work fixes bugs like Bug#35296, Bug#43012, and Bug#49634.
Error Logging — Allow Control of Verbosity (WL#6661, WL#6755) : This work gives the DBA control of how verbose the MySQL Server should be when writing to the error log (ERROR/WARNING/NOTE). This work also changes the timestamp format printed to a more standard format (UTC timestamp) and converts the existing fprintf(stderr, …) in the server layer to use the new internal error logging API.
Add Native Support for Syslog on Unixoid Platforms (WL#7793) : This work adds full support for logging server output to the system’s native syslog facility. See also Bug#55370 reported by Kyle Joiner and later enhanced by Simon Mudd and Mark Alff. See Tatiana’s article “Logging with MySQL: Error-Logging to Syslog & EventLog“.
MySQL Client
Log Interactive Commands to Syslog (WL#6788) : This work introduces a new client option, --syslog, which enables/disables the logging of attributes like sudo_user (or user), mysql_user, connection_id, db_server, DB, and query entered in an interactive session. This has been requested by some users due to auditing compliance requirements, i.e. requirements to log all interactive commands entered at the mysql command-line prompt to syslog.
Client Side Protocol Tracing (WL#6226) : This work creates hooks inside the client library code which allows tracing of protocol events such as sending packets to the server, receiving server replies, and authentication handshakes. This provides a mechanism for collecting performance data about the client-server connections, from the client’s perspective.
Client-Server Protocol
Extend mysql_real_escape_string() to be aware of the string type it’s escaping for (WL#8077) : We have added an argument of a “quote type” to the function mysql_real_escape_string_quote(). This provides the means to explicitly distinguish between single-quoted and double-quoted strings. This breaks the ABI, so it will not be backported to 5.6.
Extending the Protocol’s OK Packet (WL#4797) : This work extends the client-server protocol’s OK packet to allow the server to send additional information, e.g. server state changes. By default the server now sends information about the effect of SET character_set and USE database commands. This avoids situations like, for example, after SET NAMES big5 the server assumes that the client will send big5 encoded data, while the client character set is still using latin1.
Flag for Session-Specific State (WL#6885) : This work makes it possible for the client to tell the server that it wants notification about session state changes. One possible usage for this feature is to be able to detect if it is possible to migrate a user session context to another physical connection within a load balanced or clustered environment.
GIS: InnoDB Spatial Indexes
We have implemented spatial (R-tree) indexing within InnoDB (WL#6968, WL#6968, WL#6745) : InnoDB spatial indexes can be used with all existing syntax that has been developed for MyISAM spatial indexes. In addition, InnoDB spatial indexes support full transactional, ACID, and MVCC properties (as well as isolation levels). It employs predicate locks to prevent phantom scenarios (WL#6609). We have added a new InnoDB internal datatype called DATA_GEOMETRY, and we map all MySQL GEOMETRY datatypes to this new internal datatype (WL#6455). We have also extended CHECK TABLE so that it is able to determine whether any spatial indexes are valid (WL#7740). It now checks for a valid R-tree structure and ensures that the entry count matches up with the clustered index. See also Jimmy Yang’s article “InnoDB Spatial Indexes in 5.7.4 LAB release“.
GIS: Geometry Functions & Formats
After a careful evaluation of various open source geometry engines, we decided to replace our original GIS algorithms with Boost.Geometry. For those that build MySQL from source, it’s important to read about the new CMake options we added in the process. Changing the geometry engine is not a simple task, so a lot of the GIS effort has gone into this work (WL#7220, WL#7221, WL#7224, WL#7225, WL#7236, WL#7280, WL#7420, WL#7929). In the process, we’ve also fixed a number of bugs and added support for many additional SQL/MM standard spatial operations.
As part of the increased GIS effort, we’ve started cleaning up the name space for GIS functions. With the exception of the constructor functions that have the same names as the data types (Point, LineString, Polygon, MultiPoint, MultiLineString, MultiPolygon and
GeometryCollection) and functions that do calculations on minimum bounding rectangles
(MBRs), all spatial functions now have names prefixed by the standard “ST_” (spatio-temporal) convention, and function names without that prefix have been deprecated (WL#8055).
Support for two new import and export formats, GeoJSON and geohash, has been added. These come in addition to the existing WKT and WKB support. The new GeoJSON functions ST_AsGeoJSON and ST_GeomFromGeoJSON will encode and decode GeoJSON documents (WL#7444). The new geohash ST_Geohash, ST_LongFromGeohash, ST_LatFromGeohash and ST_PointFromGeohash will do the same for geohash representation of points (WL#7928).
We’ve also added various other helper functions (WL#8034): ST_Distance_Sphere, ST_MakeEnvelope, ST_IsValid, ST_Validate and ST_Simplify. Among these, ST_Distance_Sphere may be the most exciting one. While GIS support in MySQL still only uses a flat 2d plane, ST_Distance_Sphere will calculate distance between two points (or multipoints) on a sphere with a given radius. Two new MBR functions have also been added: MBRCoveredBy and MBRCovers (WL#7541). Since the MBR functions do calculations on MBRs instead of exact shapes, the calculations are faster than the corresponding ST_ functions.
To see how it all fits together, have a look at Matt Lord’s article, “MySQL 5.7 and GIS, an Example.
Multi-Source Replication
We have implemented Multi-Source Replication (WL#1697). It allows a slave to replicate from multiple sources/masters, but without any additional conflict detection and resolution. One use case is to commission a “fan in slave” for data aggregation or backups. This version takes into consideration the great feedback we got from the community when we first released this via MySQL Labs some time ago. See Shivji Jha’s article “MySQL-5.7.6: Introducing Multi-source replication“.
Replication — Multi-Threaded Slaves (MTS)
We have implemeted intra-schema multi-threaded slaves (WL#6314). With this implementation (--slave-parallel-type=LOGICAL-CLOCK) the slave will be able to apply transactions in parallel, even within a single database or schema, as long as they have a disjoint read and write set. See also Rohit’s article “MySQL 5.7 Enhanced MTS: configuring slave for Intra-database parallelization“.
We have also implemented ordered commits (Sequential Consistency) (WL#6813). This ensures that the commits by slave applier threads running in parallel will be done in the same order as they were on the master. This also means that the slave will never externalize a database state which was never externalized by the master. This is a requirement when the applications reading from the slave must observe the same set of states that existed on the master due to some application enforced constraint. This has become a necessity after WL#6314, which enables multiple transactions to be executed in parallel by the slave threads, some of which may be modifying a single database.
We have allowed for replication slave servers to automatically retry a transaction after a temporary failure (WL#6964). Before this, only non-MTS replication slave servers attempted to retry a transaction after a temporary failure. See Bug#68465 reported by Yoshinori Matsunobu. Finally, we have improved the performance of Multi-Threaded Slaves (MTS) by using a more precise algorithm to determine which transactions are non-conflicting (WL#7165). This allows more transactions to execute in parallel when using --slave-parallel-type=LOGICAL_CLOCK, thus greatly improving the overall replication performance.
Semi-Sync Replication
We have implemented an option to make the master wait for N slaves to acknowledge back, instead of just one, when semi-sync is enabled (WL#7169). Choosing to wait for N slaves (N > 1), adds resiliency to consecutive failures. It also improves transaction durability, as one transaction gets persisted in more than two servers before the results are externalized on the master. Furthermore, we now externalize transactions only after ACK is received (WL#6355). This allows for true lossless failovers when using semi-sync replication. If the master crashes, the slave is still ensured to be up to date. The implementation makes the master wait for the ACK after preparing within the storage engine and writing to the binary log, but before committing to the storage engine. See also Libing Song’s article “Loss-less Semi-Synchronous Replication on MySQL 5.7.2“. Finally, we have reduced semi-sync delays by using separate threads to send and receive semi-sync acknowledgements (WL#6630). So event and ACK streams can now be sent and received simultaneously.
Replication — GTID
As mentioned earlier we have provided a way to enable GTIDs online (WL#7083), so that reads and writes are allowed during the procedure, and servers do not need to synchronize. Prior to this work, the user had to stop all updates, synchronize all servers, and then restart all of them simultaneously. In addition we are now ensuring that similar events are generated regardless of the current value for GTID_MODE (WL#7592). Without ensuring this consistent behavior, there were cases where you could potentially lose GTID_EXECUTED and GTID_PURGED values (see the details in the WorkLog entry). (This was originally part of WL#7083). See also Sven Sandberg’s article “Enabling Global Transaction Identifiers Without Downtime in MySQL 5.7.6“.
Finally, we have implemented protocol support for GTIDs to allow clients to be GTID aware. We have implemented a mechanism to collect the necessary set of GTIDs to be sent over the wire in the response packet (WL#6972). We have added a tracker to the response packet of the MySQL protocol (WL#6128). This is done to be able to pass the connector information about the session state collected which can then be used to implement session consistency.
Replication — Refactoring
We have created stable interfaces useful for MySQL Group Replication and other server plugins (WL#8007 and WL#8202). Server plugins can now be informed of server events in the form of server callbacks. We have also separated out the deserialization of events in a MySQL replication stream into the a separate module (WL#7440). The goal of this refactoring is to break the dependencies between the server core and the replication framework.
Other Replication Features
- Non-Blocking
SHOW SLAVE STATUS (WL#6402) : This work adds a non-blocking option to SHOW SLAVE STATUS. The new option makes SHOW SLAVE STATUS non-blocking when run in parallel with STOP SLAVE (stopping the slave may take a long time to complete when it is waiting for an SQL thread to finish applying large events).
- Add Idempotent Mode to mysqlbinlog (WL#6403) : This work provides an idempotent mode of operation for the mysql server. In this mode the server will ignore errors while applying ROW based events from a binlog file. This mode is useful when a DBA wants to replay binlogs using mysqlbinlog, but against a MySQL server which may not contain all of the data, so suppressing expected duplicate-key and no-key-found errors can be very useful.
- Add a Rewrite-DB Option to mysqlbinlog for ROW Events (WL#6404) : This work adds support for a rewrite-db option to mysqlbinlog, so that a ROW based events can be applied to a different database/schema. I.E. replace “from_db” with “to_db” when reading a ROW based event from the binlog.
- Binlog_sender: Do Not Reallocate (WL#7299) : This work implements an optimization on the dump thread that removes unnecessary reallocation of the send buffer. The user visible effect is that CPU usage will be lessened for each dump thread that the master spawns. See also Bug#31932 reported by Mark Callaghan.
- Move Status Variables to Replication Performance Schema Tables (WL#7817) : This work moves replication system variables to Performance Schema tables so that they can be monitored per-source and not simply as global variables. This work was a requirement for Multi-source Replication.
- Make Master-Slave Syncing Option Independent of the Slave Threads (WL#7796) : This work adds a new SQL function
WAIT_FOR_EXECUTED_GTID_SET which makes the master-slave syncing option independent of the slave threads. If the slave thread is not running the WAIT_FOR_EXECUTED_GTID_SET(GTID_SET [, TIMEOUT]) function, then keep waiting until success (0) or timeout (1).
- Optimize GTIDs for Passive Slaves — Store GTIDs in a Table (WL#6559) : This work adds the option of storing GTIDs in a table instead of in the binary log. The use case may be a slave that is only used for read scale-out and is never going to become a master, thus it may not have any use for the transactions in the binary log, but it may have a use for the related GTID features (e.g. to initiate a fail over to another new master).
- Waiting for More Transactions to Enter Binlog Group Commit (BGC) Queues (WL#7742) : This work adds two new options to introduce an artificial delay to make the binary log group commit procedure pause:
--binlog_group_commit_sync_delay and --binlog_group_commit_sync_no_delay_count. This increases the likelihood that more transactions are flushed and synced together to disk, thus reducing the overall time spent in creating a group of transactions (the bigger the groups the less number of sync operations). With the correct tuning, this can make the slave perform several times faster without compromising the master’s throughput.
- Binlogging XA-prepared transactions (WL#6860) : We have added full support for XA-transactions within replication. An XA-transaction allows the client to participate in a two-phase commit protocol. The state of the XA-transaction being prepared is persisted in the database; this means that a prepared XA-transaction will survive client reconnects and server restarts. This work fixes Bug#12161.
Other Improvements
- Make InnoDB fill factor settable (WL#6747) : This work makes the
merge_threshold settable per index. Until now it has been fixed at 50%. If the amount of data within the page falls below the merge_threshold, e.g. when deleting a row or shortening it via an UPDATE, InnoDB will attempt to merge it with a neighbor page. This offers a way to decrease InnoDB’s overall disk footprint, at the expense of some additional work due to the additional page merges.
- Support for 32k and 64k pages (WL#5757) : This work adds support for 32k and 64k page sizes (the default remains 16k). Bigger page sizes will help to improve compression ratios (the bigger the page size, the more redundant bits), thus offering much improved data compression in conjunction with the new transparent page compression. Furthermore, bigger page sizes allow more “on page” or “inline” storage of BLOBs and large VARCHAR/TEXT fields, thus improving I/O performance when such fields are used.
- High Priority Transactions in InnoDB (WL#6835) : This work implements high priority transactions within InnoDB, i.e. transactions that shall never be chosen to be aborted in a deadlock scenario. The motivation is to better support MySQL Group Replication, where a transaction cannot be aborted in one replica and committed in another.
- ENSURE 5.7 SUPPORTS SMOOTH LIVE UPGRADE FROM 5.6 (WL#8350) : This work ensures a smooth upgrade fom 5.6 to 5.7 without having to specify
--skip-grant-tables as part of an intermediate step.
- Move the plugin and servers tables from MyISAM to transactional storage (WL#7160) : This work makes InnoDB the default storage engine used for the plugin and server system tables (MyISAM remains optional).
- Refactor low-level thread handling (WL#8190) : This work improves the low-level code for handling OS threads. For example, by harmonizing the APIs for Windows and non-Windows platforms (thread create & join).
- Non-intrusive refactoring of the
Security_context class code (WL#8048) : This work by refactors the Security_context code to ensure proper data encapsulation.
- DTrace Support (WL#7894) : We have added full Dtrace support to MySQL in the Server 5.6+ packages we ship for Oracle Linux 6+.
- Update_time for InnoDB Tables (WL#6658) : This work implements in-memory maintenance of
UPDATE_TIME for InnoDB tables. This functionality was previously missing in InnoDB and people have been asking for it, see Bug#2681 reported by Phil Sladen.
TRUNCATE TABLE Statement Becomes Atomic (WL#6501) : This work makes the internal InnoDB TRUNCATE TABLE statement atomic by reinitializing the original table-space header with the same space id and then physically truncating its .ibd file during the truncation of a single table tablespace.- Proper Connection ID Handling (WL#7293) : This work avoids the attempted reuse of any connection IDs that are still being used. See also Bug#44167 reported by Jan Kneschke.
- GB 18030 Chinese Character Set Support (WL#4024) : This work adds the MySQL character set GB18030, which supports the China National Standard GB 18030 character set.
The above does not include a description of deprecations and removals, neither of changes we made to system defaults. These are candidates for a follow up blog post.
That’s it for now, and thank you for using MySQL!
PlanetMySQL Voting:
Vote UP /
Vote DOWN
 The MariaDB project is pleased to announce the immediate availability of
The MariaDB project is pleased to announce the immediate availability of