Note: DO NOT use this procedure in production, this is a proof of concept (POC). MaxScale 1.1.0 does not yet fully support that procedure and things could go wrong in some situations (see at the end of the post for the details).
In my talk at PLMCE 2015, I presented an architecture to promote a slave as a new master without touching any other slave and I claimed that I tested it. This HOWTO will show you how I did my test so you are able to reproduce my results.
In the Install and Configure HOWTO, we learn how to configure the following replication topology:
First, make sure that the binary log number on A is ahead of the binary logs on B, C and D. You can achieve that by running "FLUSH BINARY LOGS;" a few times on A. The promotion of C as the new master will only work if C is behind A in its binary log numbering. This constraint is not unrealistic as C should never write to its binary log (log-slave-updates disabled).
Once the binary log constraint above is met, run some transactions on A:
Then, to simulate that Y is ahead of X, stop MaxScale on X and insert two new rows on A:
Now, let's start the fun part: kill MySQL on a A:
Bingo ! we did a master failover without touching any slave except the new master and reconfiguring the Binlog Servers ! We now have this fully working topology:
However, this is only a POC, some work must still be done on the Binlog Router implementation to avoid restarting MaxScale and manually putting files in the binary log directory. Nonetheless, the most important thing is this works and we will be able to take advantage of it in production soon.
A last observation: this will only work if the latest binary log on the Binlog Servers ends at a transaction boundary. In our example, we do not have partial transaction on X or Y. If we have had those, things would have gone wrong. To make sure this does not happen, the version of the Binlog Router implementing this failover mechanism needs to:
PlanetMySQL Voting: Vote UP / Vote DOWN
In my talk at PLMCE 2015, I presented an architecture to promote a slave as a new master without touching any other slave and I claimed that I tested it. This HOWTO will show you how I did my test so you are able to reproduce my results.
In the Install and Configure HOWTO, we learn how to configure the following replication topology:
----- / \ -----
| A | -> / X \ -> | B |
----- ----- -----
From this, you should be able to build the topology below. You will need it for the rest of this HOWTO, so start by setting it up in your environment. Make sure that:
- binary logging is enabled everywhere: log-bin=binlog,
- log-slave-updates is disabled everywhere,
- the replication user 'repl'@'%' exists on all nodes with its password being slavepass,
- the user 'repl'@'%' has the right GRANTs for accepting a MaxScale connection (search "user list" in Install and Configure HOWTO for more details).
From the replication topology above, we will simulate a failure of A when X and Y are not at the same position downloading binary logs. Then, we will level the Binlog Servers, the slaves will follow, and we will finally promote C as the new master.-----
| A |
-----
|
+-------------+
| |
/ \ / \
/ X \ / Y \
----- -----
| |
+------+ |
| | |
----- ----- -----
| B | | C | | D |
----- ----- -----
First, make sure that the binary log number on A is ahead of the binary logs on B, C and D. You can achieve that by running "FLUSH BINARY LOGS;" a few times on A. The promotion of C as the new master will only work if C is behind A in its binary log numbering. This constraint is not unrealistic as C should never write to its binary log (log-slave-updates disabled).
Once the binary log constraint above is met, run some transactions on A:
Make sure all those transactions are replicated to all slaves by running "SELECT * from test_mbls.t1;".# On A in a MySQL client session.
CREATE DATABASE test_mbls;
CREATE TABLE test_mbls.t1
(user BIGINT PRIMARY KEY, pass BIGINT DEFAULT NULL);
INSERT INTO test_mbls.t1 VALUES (1, 0);
INSERT INTO test_mbls.t1 VALUES (2, 0);
INSERT INTO test_mbls.t1 VALUES (3, 0);
Then, to simulate that Y is ahead of X, stop MaxScale on X and insert two new rows on A:
At this point, D has all rows, and B and C are missing the last 2 rows.# On X in bash.
sudo service maxscale stop;
# On A in a MySQL client session.
INSERT INTO test_mbls.t1 VALUES (4, 0);
INSERT INTO test_mbls.t1 VALUES (5, 0);
Now, let's start the fun part: kill MySQL on a A:
We are now in this situation with Y ahead of X:# On A in bash.
sudo killall -9 mysqld_safe;
sudo killall -9 mysqld;
To promote a new master, we must first level the slaves by chaining X to Y. This operation is explained in the Operations HOWTO. Once done, all the slaves should eventually be leveled. This might take a few seconds as B and C were disconnected from X when it was restarted (needed for chaining). In a future version, this restart will not be needed, the slaves will stay connected, and they will level much quicker. After chaining, we are in the following situation:-\-/-
| A |
-/-\-
/ \ / \
/ X \ / Y \
----- -----
| |
+------+ |
| | |
----- ----- -----
| B | | C | | D |
----- ----- -----
Once the slaves are leveled (at least C as we want it as our new master), do the following on C:-\-/-
| A |
-/-\-
/ \ / \
/ X \ <------ / Y \
----- -----
| |
+------+ |
| | |
----- ----- -----
| B | | C | | D |
----- ----- -----
- run "SHOW MASTER LOGS;" to get the binary log filename,
- then run enough "FLUSH BINARY LOGS;" to get one file further than the last binary log available on X and Y,
- then run "STOP SLAVE; RESET SLAVE ALL;" to drop all replication configuration from C,
- and then run "PURGE BINARY LOGS BEFORE NOW();" to forget all binary logs on C that would exist/conflict on X and Y.
Those changes are now in the binary logs of C but nowhere else. We need to make both MaxScale Binlog Server replicate from C. Do the following on both X and Y:# On C in a MySQL client session.
INSERT INTO test_mbls.t1 VALUES (6, 0);
DELETE FROM test_mbls.t1 WHERE user = 3;
- sudo service maxscale stop
- Edit the MaxScale configuration file to replicate from C but DO NOT start MaxScale yet.
- Create, in the binary log directory, a new 4 bytes binary log file with the name of the first binary log available on C (the next file in the sequence of binary logs):
xxd -r <<< "0000000: fe62 696e" > $right_binlog_file - Make sure the new binary log file has the right ownership and permissions (the same as the other binary log files).
- sudo service maxscale start
Bingo ! we did a master failover without touching any slave except the new master and reconfiguring the Binlog Servers ! We now have this fully working topology:
No GTID required, log-slave-updates disabled everywhere, all the slaves replicating from the same binary logs, and only the good old file/offset replication (and the Binlog Server).-\-/- -----
| A | | C |
-/-\- -----
|
+------+------+
| |
/ \ / \
/ X \ / Y \
----- -----
| |
----- -----
| B | | D |
----- -----
However, this is only a POC, some work must still be done on the Binlog Router implementation to avoid restarting MaxScale and manually putting files in the binary log directory. Nonetheless, the most important thing is this works and we will be able to take advantage of it in production soon.
A last observation: this will only work if the latest binary log on the Binlog Servers ends at a transaction boundary. In our example, we do not have partial transaction on X or Y. If we have had those, things would have gone wrong. To make sure this does not happen, the version of the Binlog Router implementing this failover mechanism needs to:
- never serve binary log event downstream before having received the complete transaction,
- be able to truncate its local binary log at the last completed transaction before creating the next binary log.
Those two should not be very difficult to implement.
PlanetMySQL Voting: Vote UP / Vote DOWN
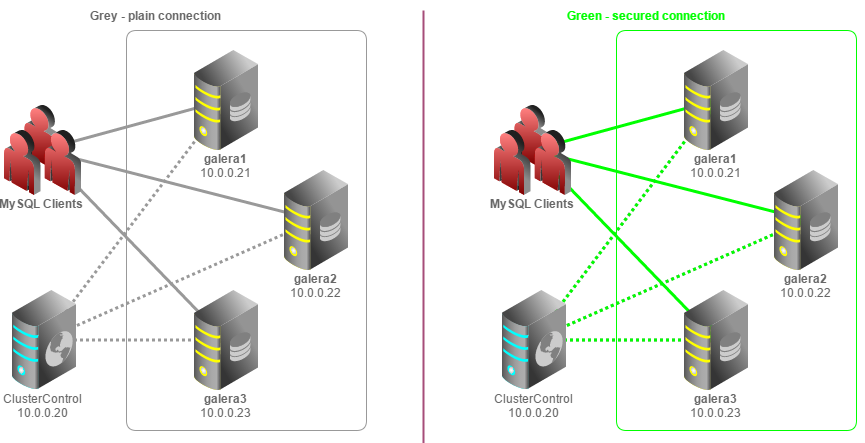

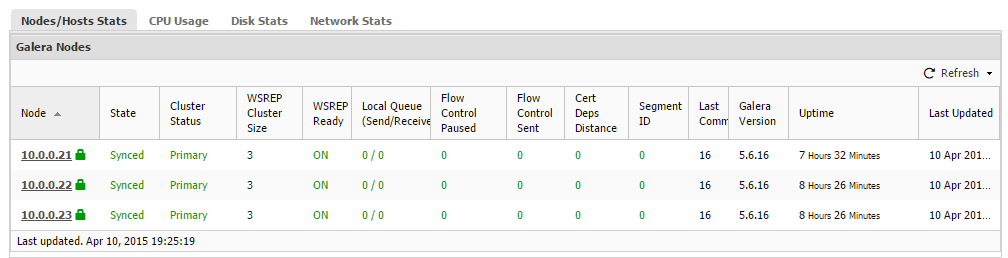

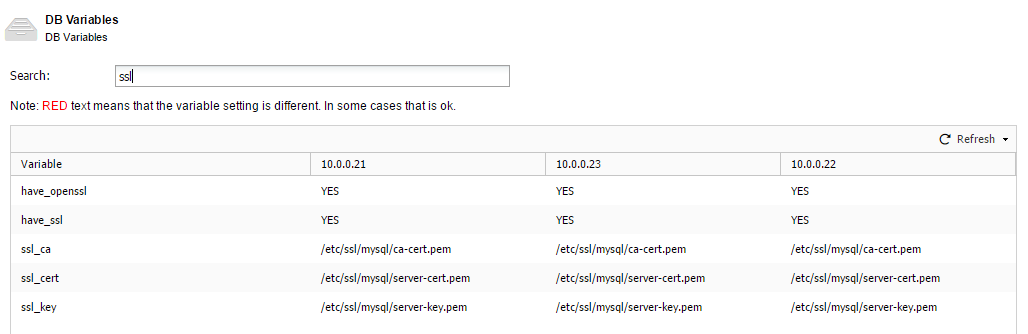
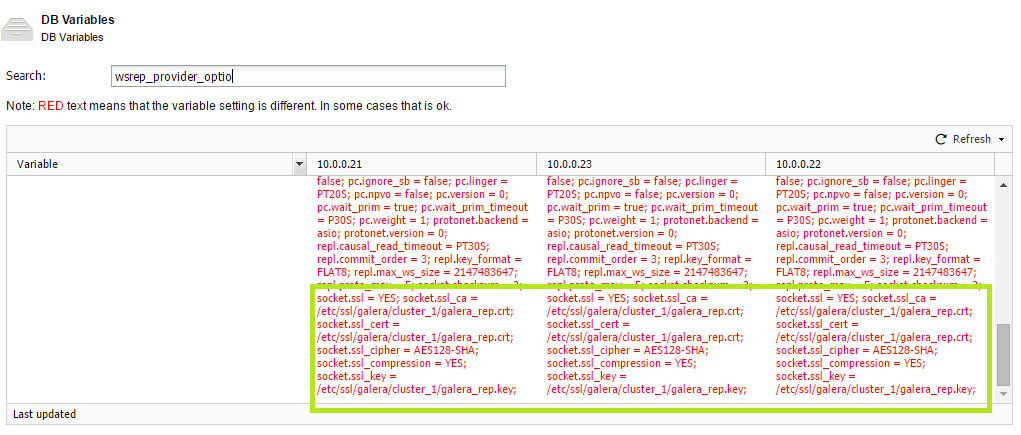











 Recently, I asked Colt Engine to help us with the MaxScale Beta Testing process. They agreed to do this, but they had to find the best way to test a new environment, with MaxScale on top and with as little impact as possible on their datacenter. The traditional approach would be to create as many virtual machines as needed and configure them for the designed test environment. This is a valid approach, but it requires some time to setup and the unnecessary use of resources. Instead, they decided to use an “Application Container”; they decided to use
Recently, I asked Colt Engine to help us with the MaxScale Beta Testing process. They agreed to do this, but they had to find the best way to test a new environment, with MaxScale on top and with as little impact as possible on their datacenter. The traditional approach would be to create as many virtual machines as needed and configure them for the designed test environment. This is a valid approach, but it requires some time to setup and the unnecessary use of resources. Instead, they decided to use an “Application Container”; they decided to use  Figure - Virtual Box
Figure - Virtual Box Figure - Docker
Figure - Docker