As of MySQL 5.6.24, MySQL Enterprise Edition includes MySQL Enterprise Firewall, an application-level firewall (it runs within the mysql database process) that enables database administrators to permit or deny SQL statement execution based on matching against whitelists of accepted statement patterns. This helps harden MySQL Server against attacks such as SQL injection or attempts to exploit applications by using them outside of their legitimate query workload characteristics.
Each MySQL account registered with the firewall has its own whitelist of statement patterns (a tokenized representation of a SQL statement), enabling protection to be tailored per account. For a given account, the firewall can operate in recording or protecting mode, for training in the accepted statement patterns or protection against unacceptable statements. The diagram illustrates how the firewall processes incoming statements in each mode.
MySQL Enterprise Firewall Operation
![]()
(from https://dev.mysql.com/doc/refman/5.6/en/firewall.html)
If you do not have a MySQL Enterprise Edition license, you may download a trial version of the software via Oracle eDelivery. The MySQL Firewall is included in the MySQL Product Pack, specifically for MySQL Database 5.6.24 or higher.
MySQL Enterprise Firewall has these components:
- A server-side plugin named MYSQL_FIREWALL that examines SQL statements before they execute and, based on its in-memory cache, renders a decision whether to execute or reject each statement.
- Server-side plugins named MYSQL_FIREWALL_USERS and MYSQL_FIREWALL_WHITELIST implement INFORMATION_SCHEMA tables that provide views into the firewall data cache.
- System tables named firewall_users and firewall_whitelist in the mysql database provide persistent storage of firewall data.
- A stored procedure named sp_set_firewall_mode() registers MySQL accounts with the firewall, establishes their operational mode, and manages transfer of firewall data between the cache and the underlying system tables.
- A set of user-defined functions provides an SQL-level API for synchronizing the cache with the underlying system tables.
- System variables enable firewall configuration and status variables provide runtime operational information.
(from https://dev.mysql.com/doc/refman/5.6/en/firewall-components.html)
Installing the Firewall
Installing the firewall is fairly easy. After you install MySQL version 5.6.24 or greater, you simply execute an SQL script that is located in the $MYSQL_HOME/share directory. There are two versions of the script, one for Linux and one for Windows (the firewall isn’t supported on the Mac yet).
The scripts are named win_install_firewall.sql for Windows and linux_install_firewall.sql for linux. You may execute this script from the command line or via MySQL Workbench. For the command line, be sure you are in the directory where the script is located.
shell> mysql -u root -p mysql < win_install_firewall.sql
Enter password: (enter root password here)
The script create the firewall tables, functions, stored procedures and installs the necessary plugins. The script contains the following:
# Copyright (c) 2015 Oracle and/or its affiliates. All rights reserved.
# Install firewall tables
USE mysql;
CREATE TABLE IF NOT EXISTS mysql.firewall_whitelist( USERHOST VARCHAR(80) NOT NULL, RULE text NOT NULL) engine= MyISAM;
CREATE TABLE IF NOT EXISTS mysql.firewall_users( USERHOST VARCHAR(80) PRIMARY KEY, MODE ENUM ('OFF', 'RECORDING', 'PROTECTING', 'RESET') DEFAULT 'OFF') engine= MyISAM;
INSTALL PLUGIN mysql_firewall SONAME 'firewall.dll';
INSTALL PLUGIN mysql_firewall_whitelist SONAME 'firewall.dll';
INSTALL PLUGIN mysql_firewall_users SONAME 'firewall.dll';
CREATE FUNCTION set_firewall_mode RETURNS STRING SONAME 'firewall.dll';
CREATE FUNCTION normalize_statement RETURNS STRING SONAME 'firewall.dll';
CREATE AGGREGATE FUNCTION read_firewall_whitelist RETURNS STRING SONAME 'firewall.dll';
CREATE AGGREGATE FUNCTION read_firewall_users RETURNS STRING SONAME 'firewall.dll';
delimiter //
CREATE PROCEDURE sp_set_firewall_mode (IN arg_userhost VARCHAR(80), IN arg_mode varchar(12))
BEGIN
IF arg_mode = "RECORDING" THEN
SELECT read_firewall_whitelist(arg_userhost,FW.rule) FROM mysql.firewall_whitelist FW WHERE FW.userhost=arg_userhost;
END IF;
SELECT set_firewall_mode(arg_userhost, arg_mode);
if arg_mode = "RESET" THEN
SET arg_mode = "OFF";
END IF;
INSERT IGNORE INTO mysql.firewall_users VALUES (arg_userhost, arg_mode);
UPDATE mysql.firewall_users SET mode=arg_mode WHERE userhost = arg_userhost;
IF arg_mode = "PROTECTING" OR arg_mode = "OFF" THEN
DELETE FROM mysql.firewall_whitelist WHERE USERHOST = arg_userhost;
INSERT INTO mysql.firewall_whitelist SELECT USERHOST,RULE FROM INFORMATION_SCHEMA.mysql_firewall_whitelist WHERE USERHOST=arg_userhost;
END IF;
END //
delimiter ;
After you run the script, the firewall should be enabled. You may verify it by running this statement:
mysql> SHOW GLOBAL VARIABLES LIKE 'mysql_firewall_mode';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| mysql_firewall_max_query_size | 4096 |
| mysql_firewall_mode | ON |
| mysql_firewall_trace | OFF |
+-------------------------------+-------+
Testing the Firewall
To test the firewall, you may use a current mysql user, but we are going to create a test user for this example – webuser@localhost. (The user probably doesn’t need all privileges, but for this example we will grant everything to this user)
CREATE USER 'webuser'@'localhost' IDENTIFIED BY 'Yobuddy!';
'GRANT ALL PRIVILEGES ON *.* TO 'webuser'@'localhost' WITH GRANT OPTION'
OPTIONAL: For our test, we will be using the sakila schema provided by MySQL. You may download the sakila database schema (requires MySQL 5.0 or later) at http://dev.mysql.com/doc/index-other.html. If you don’t want to use the sakila database, you may use your own existing database or create a new database.
After downloading the sakila schema, you will have two files, named sakila-schema.sql and sakila-data.sql. Execute the sakila-schema.sql first, and then sakila-data.sql to populate the database with data. If you are using the command line, simply do the following: (substitute UserName for a mysql user name)
# mysql -uUserName -p < sakila-schema.sql
# mysql -uUserName -p < sakila-data.sql
After creating the sakila schema and importing the data, we now set the firewall to record those queries which we want to allow:
mysql> CALL `mysql`.`sp_set_firewall_mode`("webuser@localhost","RECORDING")
+-----------------------------------------------+
| read_firewall_whitelist(arg_userhost,FW.rule) |
+-----------------------------------------------+
| Imported users: 0 Imported rules: 0 |
+-----------------------------------------------+
1 row in set (0.14 sec)
+-------------------------------------------+
| set_firewall_mode(arg_userhost, arg_mode) |
+-------------------------------------------+
| OK |
+-------------------------------------------+
1 row in set (0.22 sec)
Query OK, 5 rows affected (0.28 sec)
We can check to see the firewall mode via this statement, to be sure we are in the recording mode:
mysql> SELECT * FROM MYSQL.FIREWALL_USERS;
+-------------------+------------+
| USERHOST | MODE |
+-------------------+------------+
| webuser@localhost | RECORDING |
+-------------------+------------+
1 row in set (0.02 sec)
Now that we have recording turned on, let’s run a few queries:
mysql> use sakila
Database changed
mysql> show tables;
+----------------------------+
| Tables_in_sakila |
+----------------------------+
| actor |
| actor_info |
| address |
| category |
| city |
| country |
| customer |
| customer_list |
| film |
| film_actor |
| film_category |
| film_list |
| film_text |
| inventory |
| language |
| nicer_but_slower_film_list |
| payment |
| rental |
| sales_by_film_category |
| sales_by_store |
| staff |
| staff_list |
| store |
+----------------------------+
23 rows in set (0.00 sec)
mysql> select * from actor limit 2;
+----------+------------+-----------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+-----------+---------------------+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 |
+----------+------------+-----------+---------------------+
2 rows in set (0.13 sec)
mysql> select first_name, last_name from actor where first_name like 'T%';
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| TIM | HACKMAN |
| TOM | MCKELLEN |
| TOM | MIRANDA |
| THORA | TEMPLE |
+------------+-----------+
4 rows in set (0.00 sec)
We turn off the recording by turning on the protection mode:
mysql> CALL `mysql`.`sp_set_firewall_mode`("webuser@localhost","PROTECTING");
+-------------------------------------------+
| set_firewall_mode(arg_userhost, arg_mode) |
+-------------------------------------------+
| OK |
+-------------------------------------------+
1 row in set (0.00 sec)
We can check to see the firewall mode via this statement:
mysql> SELECT * FROM MYSQL.FIREWALL_USERS;
+-------------------+------------+
| USERHOST | MODE |
+-------------------+------------+
| webuser@localhost | PROTECTING |
+-------------------+------------+
1 row in set (0.02 sec)
And we can look at our whitelist of statements:
mysql> SELECT * FROM MYSQL.FIREWALL_WHITELIST;
+-------------------+-------------------------------------------------------------------+
| USERHOST | RULE |
+-------------------+-------------------------------------------------------------------+
| webuser@localhost | SELECT * FROM actor LIMIT ? |
| webuser@localhost | SELECT SCHEMA ( ) |
| webuser@localhost | SELECT first_name , last_name FROM actor WHERE first_name LIKE ? |
| webuser@localhost | SHOW TABLES |
+-------------------+-------------------------------------------------------------------+
4 rows in set (0.00 sec)
The firewall is now protecting against non-whitelisted queries. We can execute a couple of the queries we previously ran, which should be allowed by the firewall.
mysql> show tables;
+----------------------------+
| Tables_in_sakila |
+----------------------------+
| actor |
| actor_info |
| address |
| category |
| city |
| country |
| customer |
| customer_list |
| film |
| film_actor |
| film_category |
| film_list |
| film_text |
| inventory |
| language |
| nicer_but_slower_film_list |
| payment |
| rental |
| sales_by_film_category |
| sales_by_store |
| staff |
| staff_list |
| store |
+----------------------------+
23 rows in set (0.01 sec)
Now we run two new queries, which should be blocked by the firewall.
mysql> select * from rental;
ERROR 1045 (42000): Firewall prevents statement
mysql> select * from staff;
ERROR 1045 (42000): Firewall prevents statement
The server will write an error message to the log for each statement that is rejected. Example:
2015-03-21T22:59:05.371772Z 14 [Note] Plugin MYSQL_FIREWALL reported:
'ACCESS DENIED for webuser@localhost. Reason: No match in whitelist.
Statement: select * from rental '
You can use these log messages in your efforts to identify the source of attacks.
To see how much firewall activity you have, you may look look at the status variables:
mysql> SHOW GLOBAL STATUS LIKE 'Firewall%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Firewall_access_denied | 42 |
| Firewall_access_granted | 55 |
| Firewall_cached_entries | 78 |
+-------------------------+-------+
The variables indicate the number of statements rejected, accepted, and added to the cache, respectively.
The MySQL Enterprise Firewall Reference is found at https://dev.mysql.com/doc/refman/5.6/en/firewall-reference.html.
![]()
![]()
PlanetMySQL Voting:
Vote UP /
Vote DOWN
 this year, and this was once again a big hit. You can check out the rest of the
this year, and this was once again a big hit. You can check out the rest of the 


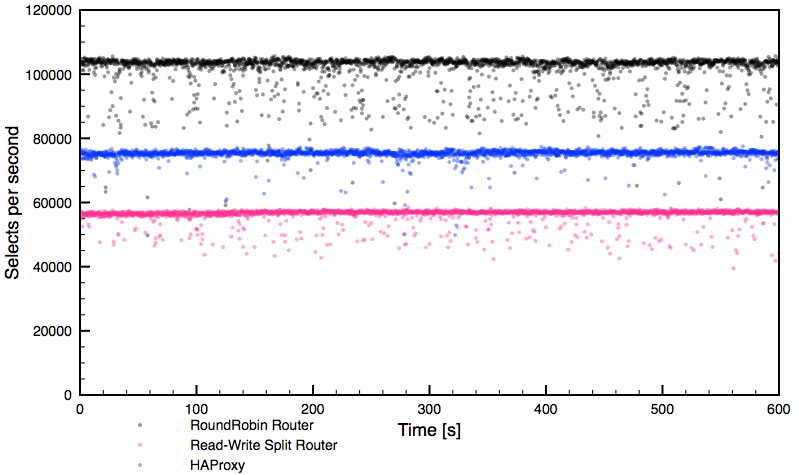
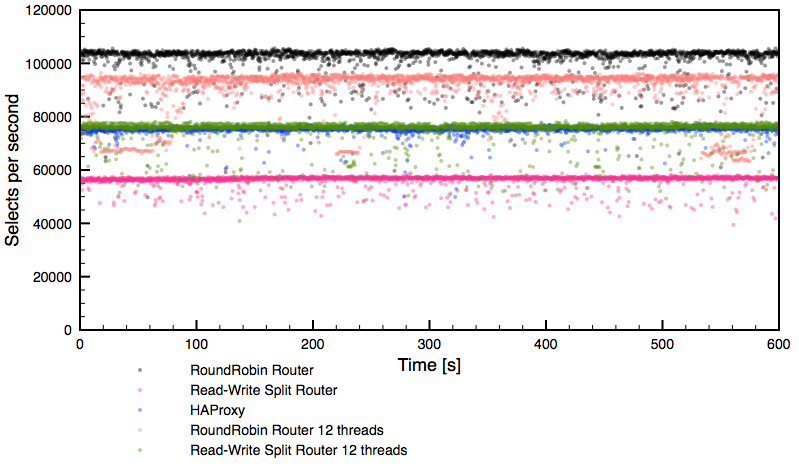
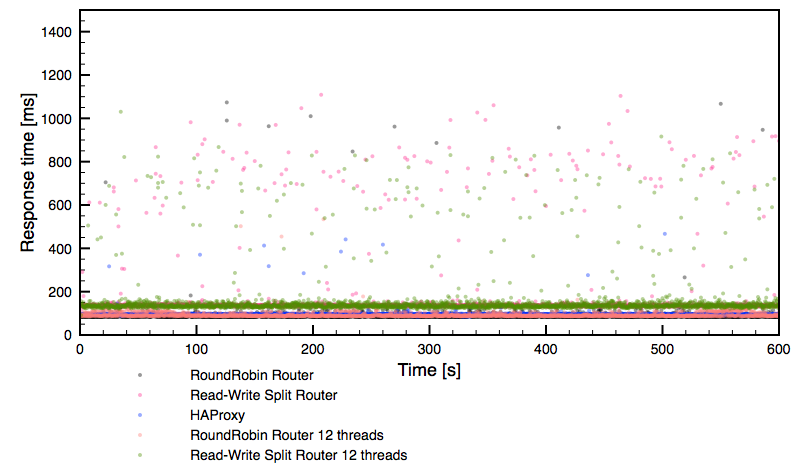
 MySQL sharding is one of the most used and surely the most abused MySQL scaling technology. My April 2 Dzone article, “
MySQL sharding is one of the most used and surely the most abused MySQL scaling technology. My April 2 Dzone article, “






