Today, we’re excited to announce our first step towards dockerizing our products. Please welcome the official ClusterControl Docker image, available on Docker Registry Hub. This will allow you to evaluate ClusterControl with a couple of commands:
$ docker pull severalnines/clustercontrol
The Docker image comes with ClusterControl installed and configured with all of its components, so you can immediately use it to manage and monitor your existing databases. Supported database servers/clusters:
- Galera Cluster for MySQL
- Percona XtraDB Cluster
- MariaDB Galera Cluster
- MySQL replication
- MySQL single instance
- MongoDB/TokuMX Replica Set
- PostgreSQL single instance
![]()
As more and more people will know, Docker is based on the concept of so called application containers and is much faster or lightweight than full stack virtual machines such as VMWare or VirtualBox. It's a very nice way to isolate applications and services to run in a completely isolated environment, which a user can launch and tear down within seconds.
Having a Docker image for ClusterControl at the moment is convenient in terms of how quickly it is to get it up and running and it's 100% reproducible. Docker users can now start testing ClusterControl, since we have images that everyone can pull down and then launch the tool.
It is a start and our plan is to add better integration with the Docker API in future releases in order to transparently manage Docker containers/images within ClusterControl, e.g., to launch/manage and deploy database clusters using Docker images.
ClusterControl Docker Images
Please refer to the Docker Hub page for the latest instructions. Pick the operating system distribution images that you would like to deploy, and use the docker pull command to download the image. To pull all images:
$ docker pull severalnines/clustercontrol
You can pull the ClusterControl image that you want based on your target cluster’s operating system.
$ docker pull severalnines/clustercontrol:<ubuntu-trusty|debian-wheezy|redhat6|redhat7>
So, if you want to pull the ClusterControl image for CentOS 6/Redhat 6, just run:
$ docker pull severalnines/clustercontrol:redhat6 #or
$ docker pull severalnines/clustercontrol:centos6
** Image tagged with ‘centos6’ or ‘centos7’ aliases to redhat’s respectively.
Use the following command to run:
$ docker run -d --name clustercontrol -p 5000:80 severalnines/clustercontrol:redhat7
Once started, ClusterControl is accessible at http://<host IP address>:5000/clustercontrol. You should see the welcome page to create a default admin user. Use your email address and specify passwords for that user. By default MySQL users root and cmon will be using ‘password’ and ‘cmon’ as default password respectively. You can override this value with -e flag, as example below:
$ docker run -d --name clustercontrol -e CMON_PASSWORD=MyCM0n22 -e MYSQL_ROOT_PASSWORD=SuP3rMan -p 5000:80 severalnines/clustercontrol:debian
Optionally, you can map the HTTPS port using -p by appending the forwarding as below:
$ docker run -d --name clustercontrol -p 5000:80 -p 5443:443 severalnines/clustercontrol:redhat7
Verify the container is running by using the ps command:
$ docker ps
The Dockerfiles are available from our Github repository. You can build it manually by cloning the repository:
$ git clone https://github.com/severalnines/docker
$ cd docker/[operating system]
$ docker build -t severalnines/clustercontrol:[operating system] .
** Replace [operating system] with your choice of OS distribution; redhat6, redhat7, centos6, centos7, debian-wheezy, ubuntu-trusty.
Example Deployment
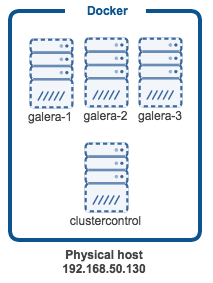
We have a physical host, 192.168.50.130 installed with Docker. We are going to create a three-node Galera cluster running on Percona XtraDB Cluster and then import it into ClusterControl, which is running in another container. This example deployment uses CentOS/Redhat based images. Following is the high-level architecture diagram:
![]()
Installing Docker
In this example, we are going to install Docker on CentOS 7, using virt-7 repository. Create the repository file:
$ vim /etc/yum.repos.d/virt-7-testing.repo
Add the following lines:
[virt7-testing]
name=virt7-testing
baseurl=http://cbs.centos.org/repos/virt7-testing/x86_64/os/
enabled=1
gpgcheck=0
Install Docker:
$ yum install -y docker
Start and enable the Docker daemon:
$ systemctl start docker
$ systemctl enable docker
Disable firewalld to avoid conflicts with Docker’s iptables rules:
$ systemctl disable firewalld
$ systemctl stop firewalld
Deploying Percona XtraDB Cluster
We are going to use a Dockerfile to build and deploy a three-node Galera / Percona XtraDB Cluster:
$ git clone https://github.com/alyu/docker
$ cd docker/percona-xtradb-5.6/centos/
$ ./build.sh
$ ./start-servers.sh 3
$ ./bootstrap-cluster.sh
** Enter root123 as the root password if prompted.
Verify the containers are up:
$ docker ps | grep galera
aedd64fa373b root/centos:pxc56 "/bin/bash /opt/init 7 minutes ago Up 7 minutes 22/tcp, 80/tcp, 443/tcp, 3306/tcp, 4444/tcp, 4567-4568/tcp galera-3
c5fc95f9912e root/centos:pxc56 "/bin/bash /opt/init 7 minutes ago Up 7 minutes 22/tcp, 80/tcp, 443/tcp, 3306/tcp, 4444/tcp, 4567-4568/tcp galera-2
7df4814686a0 root/centos:pxc56 "/bin/bash /opt/init 7 minutes ago Up 7 minutes 22/tcp, 80/tcp, 443/tcp, 3306/tcp, 4444/tcp, 4567-4568/tcp galera-1
Deploying ClusterControl
Since our Galera Cluster is deployed and running on Centos 7, we need to use the CentOS/Redhat base image for ClusterControl. Simply run the following command to pull the image:
$ docker pull severalnines/clustercontrol:centos7
Start the container as daemon and forward port 80 on the container to port 5000 on the host:
$ docker run -d --name clustercontrol -p 5000:80 severalnines/clustercontrol:centos7
Verify the ClusterControl container is up:
$ docker ps | grep clustercontrol
59134c17fe5a severalnines/clustercontrol:centos7 "/entrypoint.sh" 2 minutes ago Up 2 minutes 22/tcp, 3306/tcp, 9500/tcp, 9600/tcp, 9999/tcp, 0.0.0.0:5000->80/tcp clustercontrol
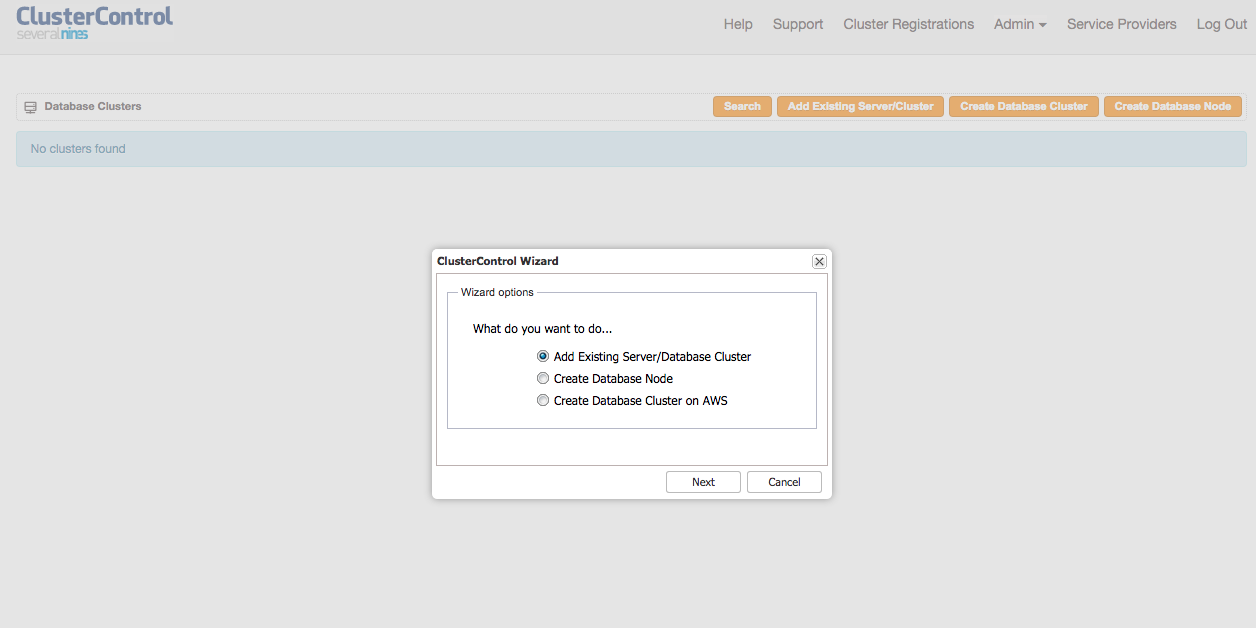
Open a browser, go to http://192.168.50.130:5000/clustercontrol and create a default admin user and password. You should see the ClusterControl landing page similar to below:
![]()
You now have ClusterControl and a Galera cluster running on 4 Docker containers.
Adding your Existing Cluster
After the database cluster is running, you can add it into ClusterControl by setting up the passwordless SSH to all managed nodes beforehand. To do this, run the following steps on ClusterControl node.
1. Enter the container console as root:
$ docker exec -it clustercontrol /bin/bash
2. Copy the SSH key to all managed database nodes:
$ ssh-copy-id 172.17.0.2
$ ssh-copy-id 172.17.0.3
$ ssh-copy-id 172.17.0.4
** The Docker images that we used has root123 setup as root password. Depending on your chosen operating system, please ensure you have the root password configured for this to work, or you can skip it by adding your SSH key file manually into the managed hosts.
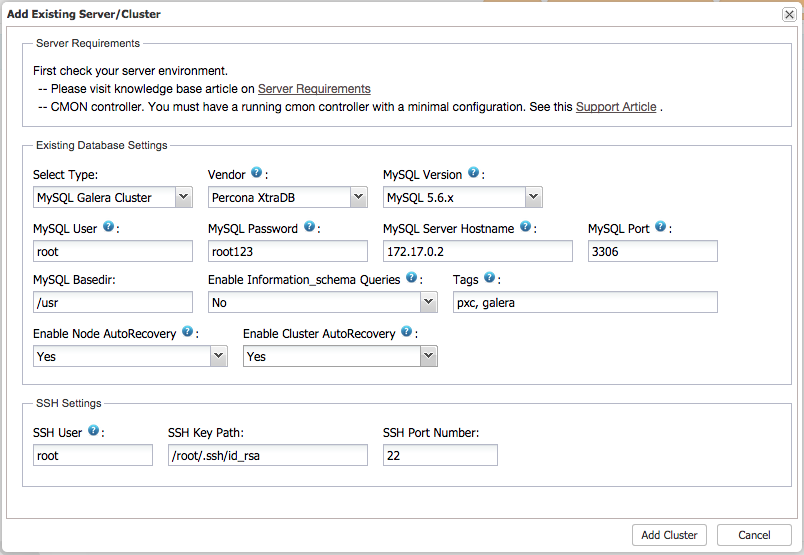
3. Start importing the cluster into ClusterControl. Open a web browser and go to Docker’s physical host IP address with the mapped port e.g, http://192.168.50.130:5000/clustercontrol and click Add Existing Cluster/Server and specify following information:
![]()
** You just need to enter ONE IP address of one of the Galera members. ClusterControl will auto discover the rest of the cluster members in the cluster and register them. Once added, you should see the Galera cluster is listed under Database Clusters list:
![]()
We are done.
What happens if a container is restarted and gets a new IP?
Note that Docker container does not use static IP, unless you explicitly configure a custom bridge which is out of the scope of this blog. This could be problematic to ClusterControl since it relies on proper IP address configuration for database grants and passwordless SSH. If the ClusterControl container restarted:
On all nodes (including ClusterControl), run following statements as root@localhost:
mysql> UPDATE mysql.user SET host = '<new IP address>' WHERE host = '<old IP address>';
mysql> FLUSH PRIVILEGES;
You also need to manually change the IP address inside /etc/cmon.cnf and/or /etc/cmon.d/cmon_<cluster ID>.cnf:
$ sed -i 's|<old IP address>|<new IP address>|g' /etc/cmon.cnf
$ sed -i 's|<old IP address>|<new IP address>|g' /etc/cmon.d/cmon_1.cnf # if exists
$ sed -i 's|<old IP address>|<new IP address>|g' /etc/cmon.d/cmon_2.cnf # if exists
** Replace <old IP address> and <new IP address> with their respective values.
Restart the cmon process to apply the changes:
$ service cmon restart
That’s it folks. The above ClusterControl + Galera Cluster setup took about 15 minutes to deploy in a container environment. How long did it take you? :-)
 Percona is glad to announce the release of Percona Server 5.6.24-72.2 on May 8, 2015. Download the latest version from the Percona web site or from the Percona Software Repositories.
Percona is glad to announce the release of Percona Server 5.6.24-72.2 on May 8, 2015. Download the latest version from the Percona web site or from the Percona Software Repositories. The MariaDB project is pleased to announce the immediate availability of
The MariaDB project is pleased to announce the immediate availability of