We recently conducted a webinar on Audit Log analysis for MySQL & MariaDB Databases. This blog will further provide a deep dive into the security & compliance surrounding databases.
Database auditing is the tracking of database resources utilization and authority, specifically, the monitoring and recording of user database actions. Auditing can be based on a variety of factors, including individual actions, such as the type of SQL statement executed, or on a combination of factors such as user name, application, time, etc. Performing regular database log analysis bolsters your internal security measures by answering questions like who changed your critical data, when it was changed, and more. Database auditing also helps you comply with increasingly demanding compliance requirements.
The purpose of this blog is to outline the importance of audit log analysis using MariaDB and Enterprise MySQL as examples.
Auditing Requirements
The requirement to track access to database servers and the data itself is not that new, but in recent years, there has been a marked need for more sophisticated tools. When auditing is enabled, each database operation on the audited database records a trail of information such as what database objects were impacted, who performed the operation and when. The comprehensive audit trail of executed database actions can be maintained over time to allow DBAs, security staff, as well as any authorized personnel, to perform in-depth analysis of access and modification patterns against data in the DBMS.
Keep in mind that auditing tracks what a particular user has done once access has been allowed. Hence, auditing occurs post-activity; it does not do anything to prohibit access. Of course, some database auditing solutions have grown to include capabilities that will identify nefarious access and shut it down before destructive actions can occur.
Audit trails produced by intrusion detection help promote data integrity by enabling the detection of security breaches. In this capacity, an audited system can serve as a deterrent against users tampering with data because it helps to identify infiltrators. Your company’s business practices and security policies may dictate being able to trace every data modification back to the initiating user. Moreover, government regulations may require your organization to analyze data access and produce regular reports, either on an ongoing basis, or on a case-by-case basis, when there is a need to identify the root cause of data integrity problems. Auditing is beneficial for all of these purposes.
Moreover, should unauthorized, malicious, or simply ill-advised operations take place, proper auditing will lead to the timely discovery of the root cause and resolution.
The General Data Protection Regulation
On April 27, 2016, the General Data Protection Regulation (GDPR) was adopted by the European Parliament and the council of the European Union that will be taking effect starting on May 25, 2018. It’s a regulation in EU law governing data protection and privacy for all individuals within the European Union. It introduces numerous security and compliance regulations to all organizations worldwide that handle, process, collect or store personal information of EU citizens. This means that organizations that work with personal data will have to elevate security measures and auditing mechanisms when handling Personal Identifiable Information (PII) of EU citizens.
Furthermore, organizations will have to ensure that only people which should have access to the personal information of EU citizens are granted access, and in case of unauthorized access, organizations must have mechanisms to detect and be alerted on any such incident in order to resolve any possible issues in an expeditious manner. Following a data breach, organizations must disclose full information on these events to their local data protection authority (DPA) and all customers concerned with the data breach in no more than 72 hours so they can respond accordingly.
Failing to comply with GDPR standard could result in heavy fines for up to 4% of the offending organization’s global revenue, or up to €20 million (whichever is greater). With this in mind, it is crucial for all affected organizations to make sure that they implement adequate log monitoring on their databases, as defined by the standard.
How Databases Implement Auditing
There is no set standard that defines how a database should implement auditing, so vendors and Database Administrators (DBAs) differ in their approach. Some employ special tables while others utilize log files. The two DBMSes that we’ll be looking at here today, MariaDB and MySQL, employ log-based auditing.
The MariaDB Audit Plugin
Prior to MariaDB 5.5.20, in order to record user access, you would have had to employ third-party database solutions. To help businesses comply with internal auditing regulations and those of various regulatory bodies, MariaDB developed the MariaDB Audit Plugin. The MariaDB Audit Plugin can be used also with MySQL, but includes some unique features that are available only for MariaDB.
In MariaDB, the Audit Plugin logs detailed information for any type of access from users to your database server and tables, including:
-
- Timestamp
- Server-Host
- User
- Client-Host
- Connection-ID
- Query-ID
- Operation
- Database
- Table
- Error-Code
Installation
Getting the Maria Audit Plugin installed, configured and the auditing activated is fairly simple. In fact, you only need a few minutes to enable auditing for your database. A restart of the Server is not needed, so you do not need to plan any downtime for the installation of the plugin. The only requirement is that you are running MariaDB or MySQL Server with version 5.5 or newer (MySQL 5.5.14, MariaDB 5.5.20).
If you installed MariaDB from its official packages, you probably already have the plugin on your system, even though it’s neither installed nor enabled by default. Look for a file called “server_audit.so” (in Linux) or “server_audit.dll” (in Windows) inside your plugins directory. The file path of the plugin library is stored in the plugin_dir system variable. To see the value of this variable and determine the file path of the plugin library, execute the following SQL statement:
SHOW GLOBAL VARIABLES LIKE 'plugin_dir';
+---------------+--------------------------+
| Variable_name | Value |
+---------------+--------------------------+
| plugin_dir | /usr/lib64/mysql/plugin/ |
+---------------+--------------------------+
If you don’t find the plugin file inside your plugins directory, download it from the MariaDB site and place it in the plugins directory manually. (In Linux, ensure that the MariaDB server can read the file by giving it 755 permissions and root user ownership.)
Next, install the plugin using the command:
INSTALL PLUGIN server_audit
SONAME 'server_audit.so';
To confirm the plugin is installed and enabled, run the query show plugins;. You should see it appear in the results list:
+-----------------------------+----------+--------------------+-----------------+---------+
| Name | Status | Type | Library | License |
+-----------------------------+----------+--------------------+-----------------+---------+
| SERVER_AUDIT | ACTIVE | AUDIT | server_audit.so | GPL |
+-----------------------------+----------+--------------------+-----------------+---------+
The MariaDB Audit Plugin comes with many variables to let you fine-tune your auditing to help you better concentrate on just those events and statements that are important to you. You can see the currently set variables with the command show global variables like "server_audit%";:
MariaDB [(none)]> SHOW GLOBAL VARIABLES LIKE "server_audit%";
+-------------------------------+-----------------------+
| Variable_name | Value |
+-------------------------------+-----------------------+
| server_audit_events | |
| server_audit_excl_users | |
| server_audit_file_path | server_audit.log |
| server_audit_file_rotate_now | OFF |
| server_audit_file_rotate_size | 1000000 |
| server_audit_file_rotations | 9 |
| server_audit_incl_users | |
| server_audit_logging | ON |
| server_audit_mode | 0 |
| server_audit_output_type | file |
| server_audit_syslog_facility | LOG_USER |
| server_audit_syslog_ident | mysql-server_auditing |
| server_audit_syslog_info | |
| server_audit_syslog_priority | LOG_INFO |
+-------------------------------+-----------------------+
These variables should be specified in the MariaDB server configuration file (e.g /etc/my.cnf.d/server.cnf) in the [server] section in order to be persistent between server restarts. For example, to have the variable server_audit_logging set to ON, add the line server_audit_logging=ON to the file:
[server]
…
server_audit_logging=OFF
…
Here is a quick rundown of some of the most important variables:
- server_audit_logging – Enables audit logging; if it’s not set to ON, audit events will not be recorded and the audit plugin will not do anything.
-
server_audit_events – Specifies the events you wish to have in the log. By default the value is empty, which means that ALL events are recorded. The options are:
- CONNECTION (users connecting and disconnecting)
- QUERY (queries and their result)
- TABLE (which tables are affected by the queries)
- server_audit_excl_users, server_audit_incl_users – These variables specify which users’ activity should be excluded from or included in the audit. server_audit_incl_users has the higher priority. By default, all users’ activity is recorded.
- server_audit_output_type – By default auditing output is sent to a file. The other option is “syslog”, meaning all entries go to the syslog facility.
- server_audit_syslog_facility, server_audit_syslog_priority – Specifies the syslog facility and the priority of the events that should go to syslog.
Understanding the Log File Entries
Once you have the audit plugin configured and running, you can examine the log file, (e.g. /var/lib/mysql/server_audit.log). There you will find all the events that have been enabled by the server_audit_logging variable. For example, CONNECTION entries will show you the user and from where connects and disconnects occur:
20140901 15:33:43,localhost.localdomain,root,localhost,5,0,CONNECT,,,0
20140901 15:45:42,localhost.localdomain,root,localhost,5,0,DISCONNECT,,,0
Here are some example TABLE and QUERY entries:
20140901 15:19:44,localhost.localdomain,root,localhost,4,133,WRITE,video_king,stores,
20140901 15:19:44,localhost.localdomain,root,localhost,4,133,QUERY, video_king,'DELETE FROM stores LIMIT 10',0
The first entry shows that there were WRITE operations on the database video_king and the table stores. The query that made the WRITE changes follows: DELETE FROM stores LIMIT 10. The order of these statements will be always the same – first the TABLE event and then the QUERY event that caused it.
A READ operation looks like this:
20140901 15:20:02,localhost.localdomain,root,localhost,4,134,READ,video_king,stores,
20140901 15:20:05,localhost.localdomain,root,localhost,4,134,QUERY,stores,'SELECT * FROM stores LIMIT 100',0
MySQL Enterprise Audit
MySQL Enterprise Edition includes MySQL Enterprise Audit, implemented using a server plugin named audit_log. MySQL Enterprise Audit uses the open MySQL Audit API to enable standard, policy-based monitoring, logging, and blocking of connection and query activity executed on specific MySQL servers. Designed to meet the Oracle audit specification, MySQL Enterprise Audit provides an out of box auditing and compliance solution for applications that are governed by both internal and external regulatory guidelines.
Installation
The plugin is included with MySQL Enterprise Audit, so you simply need to add the following to your my.cnf file to register and enable the audit plugin:
[mysqld]
plugin-load=audit_log.so (keep in mind the audit_log suffix is platform dependent, so .dll on Windows, etc.)
Alternatively, you can load the plugin at runtime:
mysql> INSTALL PLUGIN audit_log SONAME 'audit_log.so';
Auditing for a specific MySQL server can be dynamically enabled and disabled via the audit_log_policy global variable. It uses the following named values to enable or disable audit stream logging and to filter the audit events that are logged to the audit stream:
- “ALL” – enable audit stream and log all events
- “LOGINS” – enable audit stream and log only login events
- “QUERIES” – enable audit stream and log only query events
- “NONE” – disable audit stream
Another global variable, audit_log_rotate_on_size, allows you to automate the rotation and archival of audit stream log files based on size. Archived log files are renamed and appended with a datetime stamp
when a new file is opened for logging.
The MySQL audit stream is written as XML, using UFT-8 (without compression or encryption) so that it can be easily formatted for viewing using a standard XML parser. This enables you to leverage third-party tools to view the contents. You may override the default file format by setting the audit_log_format system variable at server startup. Formats include:
- Old-style XML format (audit_log_format=OLD): The original audit logging format used by default in older MySQL series.
- New-style XML format (audit_log_format=NEW): An XML format that has better compatibility with Oracle Audit Vault than old-style XML format. MySQL 5.7 uses new-style XML format by default.
- JSON format (audit_log_format=JSON)
By default, the file is named “audit.log” and resides in the server data directory. To change the name of the file, you can set the audit_log_file system variable at server startup.
MySQL Enterprise Audit was designed to be transparent at the application layer by allowing you to control the mix of log output buffering and asynchronous or synchronous disk writes to
minimize the associated overhead that comes when the audit stream is enabled. The net result is that, depending on the chosen audit stream log stream options, most application users will see little to no difference in response times when the audit stream is enabled.
Monyog MySQL Monitor
While reading the audit log file is great for a quick casual look, it’s not the most practical way to monitor database logs. Chances are you’ll be better off using the syslog option or, better still, taking advantage of tools that report on the audit log and/or syslogs. There, you can process entries to focus on certain type of events of interest.
One such tool is Monyog MySQL Monitor. Version 8.5.0 introduces audit log analysis for MySQL Enterprise and MariaDB. This feature parses the audit log maintained by the server and displays the content in clean tabular format.
Monyog accesses the audit log file, the same way it does for other MySQL log files, including the Slow Query, General Query and Error log.
Figure 1: Audit Log Options
![]()
You can select the server and the time-frame for which you want the audit log to be seen from. Then, clicking on “SHOW AUDIT LOG” fetches the contents of the log. The limit on the number of rows which can be fetched in one time-frame is 10000.
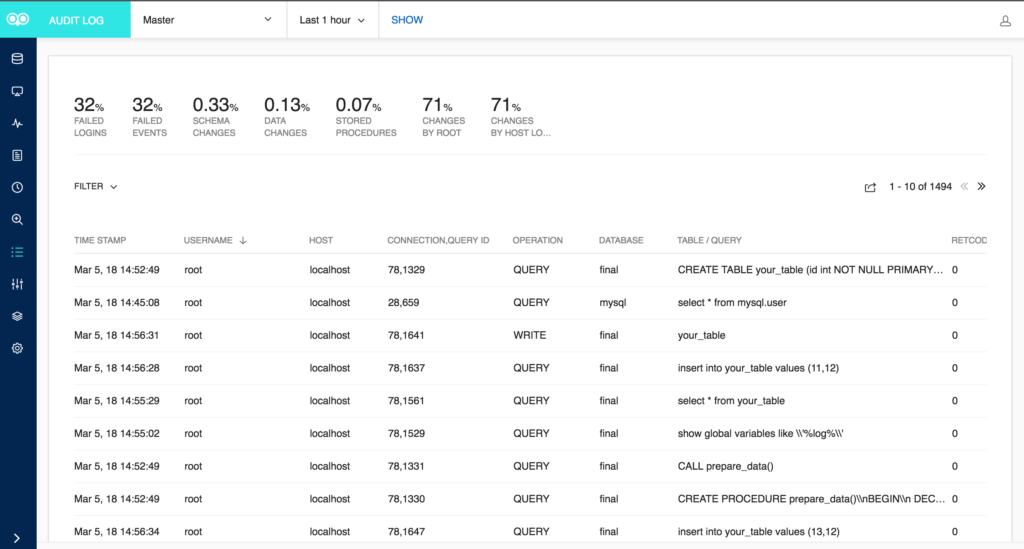
Figure 2: Audit Log Screen
![]()
The section on the top gives you quick summary of the audit log in percentage like Failed Logins, Failed Events, Schema changes, Data Changes and Stored Procedure. All these legends are clickable and shows the corresponding audit log entries on clicking. Furthermore, you can use the filter option to fetch audit log based on Username, Host, Operation, Database and Table/Query. There is also an option to export the fetched audit log content in CSV format.
Conclusion
In this blog, we outlined the importance of audit log analysis using MariaDB and Enterprise MySQL as examples.
In recent years, there has been a marked need for more sophisticated tools due to increased internal and external security and auditing policies.
A properly audited system can serve as a deterrent against users tampering with data because it helps to identify infiltrators. Once an unauthorized, malicious, or simply ill-advised operation has taken place, proper auditing will lead to the timely discovery of the root cause and resolution.
Both MariaDB and MySQL implement auditing via native plugins. These are fully configurable and may record database activities in a variety of formats. The resulting log files may be read directly or analyzed by a tool such as the Monyog MySQL Monitor. It provides a summary of Failed Logins, Failed Events, Schema changes, Data Changes and Stored Procedure, as well as fields such as Username, Host, Operation, Database and Table/Query, all within an easy-to-read tabular format.
Download a 14-day free trial of Monyog MySQL monitor. Here’s the complete video for all those who couldn’t attend the webinar.
The post Database Audit Log Monitoring for Security and Compliance appeared first on Monyog Blog.