This guide is meant to help set up a MariaDB AX cluster using TARBALL tar.gz binary image instead of RPM files with a non-root account on CentOS 7 machines. But we still need to install some dependencies using root and yum repository manager.
By the end of this, we will have a 2 User Modules (UM), 3 Performance Module (PM) node cluster running on local storage.
Summary
Download the latest tarball binaries for MariaDB AX.
The following is the summary of tasks to be performed:
- VMs OS prerequisites setup
- We will be using CentOS 7, it should be identical for Red Hat Enterprise Linux as well.
- Create MariaDB ColumnStore owner account and a group as
mcsadmand set its password. - Setup the /etc/hosts file on all the nodes with IP - HostName mapping for easier access.
- Download the ColumnStore TARBALL and extract it under /home/mcsadm.
- Generate ssh key on PM1 using
mcsadmuser and copy the key to all the nodes. - Generate ssh key on UM1 and copy the public key to UM1 and UM2.
- This is used for UM1 to UM2 data replication.
- Generate ssh key on UM2 and copy the public key to UM2 and UM1.
- This is used for UM2 to UM1 data replication.
- Server preparation
- Using the
rootuser- Install the ColumnStore dependencies on all nodes using
yum - setup
umaskon all nodes - setup
sudoaccess on all nodes formcsadmuser - setup
ulimiton all nodes formcsadmuser
- Install the ColumnStore dependencies on all nodes using
- Using the
- Test the setup using the ClusterTest tool using
mcsadmuser
Preparing the VM OS
There are a few important things that are required before we start the installations.
Note: the following steps must be performed and validated on all the VMs
Disable SELinux
For this we will edit the SELinux configuration, in the file /etc/selinux/config, make sure to change SELINUX=disabled and it should look like this:
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
After saving and exiting, we will need to reboot the VM to take permanent effect. Check if the SELinux has actually been disabled, use either of the two commands (sestatus/getenforce) to confirm:
[root@localhost ~] sestatus
SELinux status: disabled
[root@localhost ~] getenforce
Disabled
Disable firewalld
Firewalld is a standard service that is disabled using the command systemctl on the RHEL 7 / CentOS 7. Disable it on all the nodes and check its status using the systemctl status firewalld:
[root@localhost ~] systemctl stop firewalld
[root@localhost ~] systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@localhost ~] systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
Change localedef
Execute the following on all the nodes to make sure proper character set across the cluster.
[root@localhost ~] localedef -i en_US -f UTF-8 en_US.UTF-8
Performance optimization considerations
Following are some of the network-related optimizations that we can do, please also consult with your network/OS administrators for other optimizations that might be beneficial.
GbE NIC settings:
Modify /etc/rc.d/rc.local to include the following:
/sbin/ifconfig eth0 txqueuelen 10000
Modify /etc/sysctl.conf for the following:
# increase TCP max buffer size
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
# increase Linux autotuning TCP buffer limits
# min, default, and max number of bytes to use
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
# don't cache ssthresh from previous connection
net.ipv4.tcp_no_metrics_save = 1
# recommended to increase this for 1000 BT or higher
net.core.netdev_max_backlog = 2500
# for 10 GigE, use this
net.core.netdev_max_backlog = 30000
NOTE: Make sure there is only 1 setting of net.core.netdev_max_backlog in the /etc/sysctl.conf file.
Cache memory settings
To optimize Linux to cache directories and inodes the vm.vfs_cache_pressure can be set to a lower value than 100 to attempt to retain caches for inode and directory structures. This will help improve read performance. A value of 10 is suggested. The following commands must all be run as the root user or with sudo.
To check the current value:
cat /proc/sys/vm/vfs_cache_pressure
Add the following to /etc/sysctl.conf to make the cache changes permanent.
vm.vfs_cache_pressure = 10
Create mcsadm account
Now we are ready to create the MariaDB ColumnStore owner account mcsadm which will be used for the installation of the tarball.
The mcsadm user and group are required to be created on all the nodes. sudo privilege to the mcsadm user is also mandatory, this requirement of sudo access is being removed in future releases of ColumnStore.
Following this, all steps will be done using mcsadm user with the help of sudo unless specified differently.
Remember to set mcsadm user's password as it will be required later on for key exchange.
[root@localhost ~] groupadd mcsadm
[root@localhost ~] useradd -g mcsadm mcsadm
[root@localhost ~] passwd mcsadm
Changing password for user mcsadm.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
Setup /etc/hosts file
Add the following to the file /etc/hosts on all the nodes. This will ensure all nodes are accessible by their respective hostnames.
192.168.56.104 UM1
192.168.56.105 UM2
192.168.56.106 PM1
192.168.56.107 PM2
192.168.56.108 PM3
Download
In this case, we are going to download the tar file directly from the server, but feel free to download it externally and transfer to the server using your favorite secure file transfer tools.
[mcsadm@pm1 ~]$ wget https://downloads.mariadb.com/MariaDB/mariadb-columnstore/latest/centos/x86_64/7/mariadb-columnstore-1.1.5-1-centos7.x86_64.bin.tar.gz
--2018-06-30 14:02:50-- https://downloads.mariadb.com/MariaDB/mariadb-columnstore/latest/centos/x86_64/7/mariadb-columnstore-1.1.5-1-centos7.x86_64.bin.tar.gz
Resolving downloads.mariadb.com (downloads.mariadb.com)... 51.255.94.155, 2001:41d0:1004:249b::
Connecting to downloads.mariadb.com (downloads.mariadb.com)|51.255.94.155|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 489245964 (467M) [application/octet-stream]
Saving to: ‘mariadb-columnstore-1.1.5-1-centos7.x86_64.bin.tar.gz’
100%[================================================================>] 489,245,964 5.54MB/s in 2m 16s
2018-06-30 14:05:13 (3.44 MB/s) - ‘mariadb-columnstore-1.1.5-1-centos7.x86_64.bin.tar.gz’ saved [489245964/489245964]
[mcsadm@pm1 ~]$ ls -rlt
total 477780
-rw-rw-r-- 1 mcsadm mcsadm 489245964 Jun 15 16:45 mariadb-columnstore-1.1.5-1-centos7.x86_64.bin.tar.gz
[mcsadm@pm1 downloads]$ tar -zxf mariadb-columnstore-1.1.5-1-centos7.x86_64.bin.tar.gz
[mcsadm@pm1 ~]$ ls -rlt
total 0
drwxr-xr-x 3 mcsadm mcsadm 25 Jun 11 19:29 mariadb
-rw-rw-r-- 1 mcsadm mcsadm 489245964 Jun 15 16:45 mariadb-columnstore-1.1.5-1-centos7.x86_64.bin.tar.gz
[mcsadm@pm1 ~]$ pwd
/home/mcsadm
Generating SSH Keys
Once the tarball is downloaded and extracted under /home/mcsadm folder, generate the Key on PM1 node using ssh-keygen and then copy it to all the nodes using ssh-copyid -i
[mcsadm@pm1 ~]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/mcsadm/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/mcsadm/.ssh/id_rsa.
Your public key has been saved in /home/mcsadm/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:IcAWtetlQw8vHS3QwAgS4vphvY22HdCJaCHYqRHa1ab mcsadm@um1
The key's randomart image is:
+---[RSA 2048]----+
|. . o..-.+ .=. |
|o= + .B.+ +o *. |
|= B .+.-. .+B.o |
| * X o o E.+o- |
| * + o S . |
| -+ o == . E |
| E o o--B |
| - + . |
| o . |
+----[SHA256]-----+
[mcsadm@pm1 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub pm1
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/mcsadm/.ssh/id_rsa.pub"
The authenticity of host 'pm1 (192.168.56.106)' can't be established.
ECDSA key fingerprint is SHA256:Jle/edRpKz9ysV8xp1K9TlIGvbg8Sb1p+GbDob3Id0g.
ECDSA key fingerprint is MD5:a1:ce:9d:58:80:c6:ed:5a:95:7b:33:82:68:cb:0f:40.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
mcsadm@pm1's password: ******
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'pm1'"
and check to make sure that only the key(s) you wanted were added.
[mcsadm@pm1 ~]$ ssh pm1
Last login: Sat Jun 30 13:37:50 2018
[mcsadm@pm1 ~]$ exit
logout
Connection to pm1 closed.
[mcsadm@pm1 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub pm2
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/mcsadm/.ssh/id_rsa.pub"
The authenticity of host 'pm2 (192.168.56.107)' can't be established.
ECDSA key fingerprint is SHA256:Jle/edRpKz9ysV8xp1K9TlIGvbg8Sb1p+GbDob3Id0g.
ECDSA key fingerprint is MD5:a1:ce:9d:58:80:c6:ed:5a:95:7b:33:82:68:cb:0f:40.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
mcsadm@pm2's password: ******
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'pm2'"
and check to make sure that only the key(s) you wanted were added.
[mcsadm@pm1 ~]$ ssh pm2
[mcsadm@pm2 ~]$ exit
logout
Connection to pm2 closed.
[mcsadm@pm1 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub pm3
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/mcsadm/.ssh/id_rsa.pub"
The authenticity of host 'pm3 (192.168.56.108)' can't be established.
ECDSA key fingerprint is SHA256:Jle/edRpKz9ysV8xp1K9TlIGvbg8Sb1p+GbDob3Id0g.
ECDSA key fingerprint is MD5:a1:ce:9d:58:80:c6:ed:5a:95:7b:33:82:68:cb:0f:40.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
mcsadm@pm3's password: ******
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'pm3'"
and check to make sure that only the key(s) you wanted were added.
[mcsadm@pm1 ~]$ ssh pm3
[mcsadm@pm3 ~]$ exit
logout
Connection to pm3 closed.
[mcsadm@pm1 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub um1
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/mcsadm/.ssh/id_rsa.pub"
The authenticity of host 'um1 (192.168.56.104)' can't be established.
ECDSA key fingerprint is SHA256:Jle/edRpKz9ysV8xp1K9TlIGvbg8Sb1p+GbDob3Id0g.
ECDSA key fingerprint is MD5:a1:ce:9d:58:80:c6:ed:5a:95:7b:33:82:68:cb:0f:40.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
mcsadm@um1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'um1'"
and check to make sure that only the key(s) you wanted were added.
[mcsadm@pm1 ~]$ ssh um1
[mcsadm@um1 ~]$ exit
logout
Connection to um1 closed.
[mcsadm@pm1 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub um2
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/mcsadm/.ssh/id_rsa.pub"
The authenticity of host 'um2 (192.168.56.105)' can't be established.
ECDSA key fingerprint is SHA256:Jle/edRpKz9ysV8xp1K9TlIGvbg8Sb1p+GbDob3Id0g.
ECDSA key fingerprint is MD5:a1:ce:9d:58:80:c6:ed:5a:95:7b:33:82:68:cb:0f:40.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
mcsadm@um2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'um2'"
and check to make sure that only the key(s) you wanted were added.
[mcsadm@pm1 ~]$ ssh um2
[mcsadm@um2 ~]$ exit
logout
Connection to um2 closed.
[mcsadm@pm1 ~]$
Key Exchange between UM1 and UM2
Generate an SSH key on UM1 and copy in both UM1 and UM2, similarly generate another SSH key on UM2 and copy it to UM2 and UM1 respectively.
UM1:
[mcsadm@um1 ~]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/mcsadm/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/mcsadm/.ssh/id_rsa.
Your public key has been saved in /home/mcsadm/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:IcXWteJlQw8vHK3YwAgS4vphvY2bHdCJaCHYqRHa1ro mcsadm@um1
The key's randomart image is:
+---[RSA 2048]----+
|. . o..o.+ .=. |
|o= + . .+ +o *. |
|= B . ... .+B.o |
| * = o o o.+oo |
|o * + o S . |
| + o = |
| E o o |
| + . |
| o . |
+----[SHA256]-----+
[mcsadm@um1 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub um1
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/mcsadm/.ssh/id_rsa.pub"
The authenticity of host 'um1 (192.168.56.104)' can't be established.
ECDSA key fingerprint is SHA256:Jle/edRpKz9ysV8xp1K9TlIGvbg8Sb1p+GbDob3Id0g.
ECDSA key fingerprint is MD5:a1:ce:9d:58:80:c6:ed:5a:95:7b:33:82:68:cb:0f:40.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
mcsadm@um1's password:
Permission denied, please try again.
mcsadm@um1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'um1'"
and check to make sure that only the key(s) you wanted were added.
[mcsadm@um1 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub um2
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/mcsadm/.ssh/id_rsa.pub"
The authenticity of host 'um2 (192.168.56.105)' can't be established.
ECDSA key fingerprint is SHA256:Jle/edRpKz9ysV8xp1K9TlIGvbg8Sb1p+GbDob3Id0g.
ECDSA key fingerprint is MD5:a1:ce:9d:58:80:c6:ed:5a:95:7b:33:82:68:cb:0f:40.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
mcsadm@um2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'um2'"
and check to make sure that only the key(s) you wanted were added.
[mcsadm@um1 ~]$ ssh um2
[mcsadm@um2 ~]$ exit
logout
Connection to um2 closed.
[mcsadm@um1 ~]$
UM2:
[mcsadm@um2 ~]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/mcsadm/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/mcsadm/.ssh/id_rsa.
Your public key has been saved in /home/mcsadm/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:VSiUVyGkQQYcQE/WxeNP6wiWIWtNOfpSqzdEG/uImA8 mcsadm@um2
The key's randomart image is:
+---[RSA 2048]----+
| .oo=*==+o+. |
| +..+o=o |
| . .=.. |
| . B.. . |
| BSB o . |
| + X o |
| E+ * = o |
| o.o * o . |
| .o+ . |
+----[SHA256]-----+
[mcsadm@um2 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub um2
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/mcsadm/.ssh/id_rsa.pub"
The authenticity of host 'um2 (192.168.56.105)' can't be established.
ECDSA key fingerprint is SHA256:Jle/edRpKz9ysV8xp1K9TlIGvbg8Sb1p+GbDob3Id0g.
ECDSA key fingerprint is MD5:a1:ce:9d:58:80:c6:ed:5a:95:7b:33:82:68:cb:0f:40.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
mcsadm@um2's password:
Permission denied, please try again.
mcsadm@um2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'um2'"
and check to make sure that only the key(s) you wanted were added.
[mcsadm@um2 ~]$ ssh-copy-id -i ~/.ssh/id_rsa.pub um1
/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/mcsadm/.ssh/id_rsa.pub"
The authenticity of host 'um1 (192.168.56.104)' can't be established.
ECDSA key fingerprint is SHA256:Jle/edRpKz9ysV8xp1K9TlIGvbg8Sb1p+GbDob3Id0g.
ECDSA key fingerprint is MD5:a1:ce:9d:58:80:c6:ed:5a:95:7b:33:82:68:cb:0f:40.
Are you sure you want to continue connecting (yes/no)? yes
/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
mcsadm@um1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'um1'"
and check to make sure that only the key(s) you wanted were added.
Install Dependencies and Configurations
Using user root, install all the required packages, set umask, sudo privileges and ulimit for mcsadm user. All these are required by ColumnStore on all the nodes.
[root@pm1 local] yum -y install boost expect perl perl-DBI openssl zlib file sudo libaio rsync snappy net-tools perl-DBD-MySQL
[root@pm1 local] echo "umask 022" >> /etc/profile
[root@pm1 local] echo "mcsadm ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
[root@pm1 local] echo "@mcsadm hard nofile 65536" >> /etc/security/limits.conf
[root@pm1 local] echo "@mcsadm soft nofile 65536" >> /etc/security/limits.conf
Cluster test
Once the dependencies have been set up along with ssh key exchange, execute the Columnstore cluster tester tool from PM1 node using mcsadm user.
[mcsadm@pm1 ~]$ ./mariadb/columnstore/bin/columnstoreClusterTester.sh
*** This is the MariaDB Columnstore Cluster System Test Tool ***
** Validate local OS is supported
Local Node OS System Name : CentOS Linux 7 (Core)
** Run Non-root User directory permissions check on Local Node
Local Node permission test on /tmp : Passed
Local Node permission test on /dev/shm : Passed
** Run MariaDB Console Password check
Passed, no problems detected with a MariaDB password being set without an associated /root/.my.cnf
** Run MariaDB ColumnStore Dependent Package Check
Local Node - Passed, all dependency packages are installed
Failed, Local Node package mariadb-libs is installed, please un-install
Failure occurred, do you want to continue? (y,n) > y
*** Finished Validation of the Cluster, Failures occurred. Check for Error/Failed test results ***
[mcsadm@pm1 ~]$ rpm -qa | grep mariadb
mariadb-libs-5.5.56-2.el7.x86_64
[mcsadm@pm1 ~]$
The above shows a failed cluster test as the default MariaDB libraries that are provided within the Linux distribution are already installed, we need to uninstall these for a clean ColumnStore Installation.
Remove the MariaDB 5.5 libraries and execute the cluster test one more time.
[mcsadm@pm1 ~]$ sudo rpm -e --nodeps mariadb-libs-5.5.56-2.el7.x86_64
[mcsadm@pm1 ~]$ ./mariadb/columnstore/bin/columnstoreClusterTester.sh
*** This is the MariaDB Columnstore Cluster System Test Tool ***
** Validate local OS is supported
Local Node OS System Name : CentOS Linux 7 (Core)
** Run Non-root User directory permissions check on Local Node
Local Node permission test on /tmp : Passed
Local Node permission test on /dev/shm : Passed
** Run MariaDB Console Password check
Passed, no problems detected with a MariaDB password being set without an associated /root/.my.cnf
** Run MariaDB ColumnStore Dependent Package Check
Local Node - Passed, all dependency packages are installed
Local Node - Passed, all packages that should not be installed aren't installed
*** Finished Validation of the Cluster, all Tests Passed ***
[mcsadm@pm1 ~]$
All the tests are cleared, now its time to configure ColumnStore for a 2 UM and 3 PM nodes.
Post Install
Once the cluster test tool is successful, execute post-install and follow the instruction for a distributed install, the user inputs are as follows:
- Select the type of Data Storage [1=internal, 2=external] () > 1
- Internal means local disk
-
Enter number of User Modules [1,1024] () > 2
-
Since we are doing a 2UM Nodes setup
-
-
Enter Nic Interface #1 Host Name () > um1
-
Enter "um1" here based on the /etc/hosts file setup
-
-
Enter Nic Interface #1 IP Address of um1 (192.168.56.104) >
-
Just press enter to accept the IP already identified by the setup
-
-
Enter Nic Interface #2 Host Name (unassigned) >
-
Press Enter without any value here as we are only configuring 1 network interface per node
-
-
The above 3 will repeat depending on the number of UM nodes specified
-
Enter number of Performance Modules [1,1024] () > 3
-
Since we are doing a 3 PM nodes
-
-
Enter Nic Interface #1 Host Name () > pm1
-
Enter "pm1" here based on the /etc/hosts setup
-
-
Enter Nic Interface #1 IP Address of pm1 (192.168.56.106) >
-
Just press enter to accept the IP already identified by the setup
-
-
Enter Nic Interface #2 Host Name (unassigned) >
-
Press Enter without any value here as we are only configuring 1 network interface per node
-
-
The above three will be repeated depending on the number of PM nodes specified
[mcsadm@pm1 ~]$ ./mariadb/columnstore/bin/post-install --installdir=$HOME/mariadb/columnstore
The next steps are:
If installing on a pm1 node:
export COLUMNSTORE_INSTALL_DIR=/home/mcsadm/mariadb/columnstore
export LD_LIBRARY_PATH=/home/mcsadm/mariadb/columnstore/lib:/home/mcsadm/mariadb/columnstore/mysql/lib/mysql:/home/mcsadm/mariadb/columnstore/lib:/home/mcsadm/mariadb/columnstore/mysql/lib:/home/mcsadm/mariadb/columnstore/lib:/home/mcsadm/mariadb/columnstore/mysql/lib:/home/mcsadm/mariadb/columnstore/lib:/home/mcsadm/mariadb/columnstore/mysql/lib
/home/mcsadm/mariadb/columnstore/bin/postConfigure -i /home/mcsadm/mariadb/columnstore
If installing on a non-pm1 using the non-distributed option:
export COLUMNSTORE_INSTALL_DIR=/home/mcsadm/mariadb/columnstore
export LD_LIBRARY_PATH=/home/mcsadm/mariadb/columnstore/lib:/home/mcsadm/mariadb/columnstore/mysql/lib/mysql:/home/mcsadm/mariadb/columnstore/lib:/home/mcsadm/mariadb/columnstore/mysql/lib:/home/mcsadm/mariadb/columnstore/lib:/home/mcsadm/mariadb/columnstore/mysql/lib:/home/mcsadm/mariadb/columnstore/lib:/home/mcsadm/mariadb/columnstore/mysql/lib
/home/mcsadm/mariadb/columnstore/bin/columnstore start
Copy the above export scripts in the ~/.bashrc script for PM1 node install Make sure the tar.gz file is under /home/mcsadm/ home folder before executing postConfigure.
[mcsadm@pm1 ~]$ /home/mcsadm/mariadb/bin/postConfigure -i /home/mcsadm/mariadb/columnstore
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool should only be run on the Parent OAM Module
which is a Performance Module, preferred Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) > 2
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 1
Seperate Server Installation will be performed.
NOTE: Local Query Feature allows the ability to query data from a single Performance
Module. Check MariaDB ColumnStore Admin Guide for additional information.
Enable Local Query feature? [y,n] (n) > n
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature is Enabled, do you want to leave enabled? [y,n] (y) > y
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) > 1
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 70%
Setting 'TotalUmMemory' to 50%
===== Setup the Module Configuration =====
----- User Module Configuration -----
Enter number of User Modules [1,1024] (2) > 2
*** User Module #1 Configuration ***
Enter Nic Interface #1 Host Name (um1) > um1
Enter Nic Interface #1 IP Address of um1 (192.168.56.104) >
Enter Nic Interface #2 Host Name (unassigned) >
*** User Module #2 Configuration ***
Enter Nic Interface #1 Host Name (um2) > um2
Enter Nic Interface #1 IP Address of um2 (192.168.56.105) >
Enter Nic Interface #2 Host Name (unassigned) >
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (3) > 3
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (pm1) > pm1
Enter Nic Interface #1 IP Address of pm1 (192.168.56.106) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) > 1
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (pm2) > pm2
Enter Nic Interface #1 IP Address of pm2 (192.168.56.107) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' (2) > 2
*** Performance Module #3 Configuration ***
Enter Nic Interface #1 Host Name (pm3) > pm3
Enter Nic Interface #1 IP Address of pm3 (192.168.56.108) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm3' (3) > 3
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using a Binary package
located in the /home/mcsadm directory.
Next step is to enter the password to access the other Servers.
This is either your password or you can default to using a ssh key
If using a password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
----- Performing Install on 'um1 / um1' -----
Install log file is located here: /tmp/um1_binary_install.log
----- Performing Install on 'um2 / um2' -----
Install log file is located here: /tmp/um2_binary_install.log
----- Performing Install on 'pm2 / pm2' -----
Install log file is located here: /tmp/pm2_binary_install.log
----- Performing Install on 'pm3 / pm3' -----
Install log file is located here: /tmp/pm3_binary_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait ...................... DONE
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /home/mcsadm/mariadb/columnstore/bin/columnstoreAlias
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[mcsadm@pm1 ~]$
The above indicates a successful installation of MariaDB AX and ColumnStore.
In case of any errors, the log files for all the nodes are located under PM 1's /tmp folder with node-specific file names.
Test ColumnStore by using mcsmysql from UM1 node
[mcsadm@um1 ~]$ mcsmysql
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 40
Server version: 10.2.15-MariaDB-log Columnstore 1.1.5-1
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> show databases;
+---------------------+
| Database |
+---------------------+
| calpontsys |
| columnstore_info |
| infinidb_querystats |
| infinidb_vtable |
| information_schema |
| mysql |
| performance_schema |
| test |
+---------------------+
8 rows in set (0.00 sec)
MariaDB [(none)]> create database testdb;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> use testdb;
Database changed
MariaDB [testdb]> show tables;
Empty set (0.00 sec)
MariaDB [testdb]> create table tab(id int, name varchar(100));
Query OK, 0 rows affected (0.01 sec)
MariaDB [testdb]> show create table tab\G
*************************** 1. row ***************************
Table: tab
Create Table: CREATE TABLE `tab` (
`id` int(11) DEFAULT NULL,
`name` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
MariaDB [testdb]> create table tab_cs(id int, name varchar(100)) engine=columnstore;
Query OK, 0 rows affected (0.39 sec)
MariaDB [testdb]> show create table tab_cs\G
*************************** 1. row ***************************
Table: tab_cs
Create Table: CREATE TABLE `tab_cs` (
`id` int(11) DEFAULT NULL,
`name` varchar(100) DEFAULT NULL
) ENGINE=Columnstore DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
MariaDB [testdb]> insert into tab_cs select rand()*10000, column_name from information_schema.columns;
Query OK, 1921 rows affected (1.70 sec)
Records: 1921 Duplicates: 0 Warnings: 0
MariaDB [testdb]> select count(*) from tab_cs;
+----------+
| count(*) |
+----------+
| 1921 |
+----------+
1 row in set (0.08 sec)
MariaDB [testdb]>
This concludes a successful MariaDB AX distributed tarball install.
Conclusion
MariaDB ColumnStore is a powerful distributed analytical storage engine available as part of MariaDB AX along with MariaDB MaxScale. Installation using a tarball is quite an easy task.
Summary:
- Create a new user/group mcsadm
- Download and untar the tarball tar.gz file under /home/mcsadm
- Perform SSH Key Exchange between PM1 and all nodes
- Perform SSH Key Exchange between UM1 and UM2 and vice versa
- Perform a Cluster Test to ensure no problems
- Execute Post Install
- Execute Post Configure
References
- MariaDB ColumnStore
- Getting Ready to Install ColumnStore 1.1.x
- Installation Guide 1.1.x
- ColumnStore Docker Setup
This blog is about setting up a MariaDB AX Cluster with 2 UM and 3 PM nodes on a CentOS 7 Cluster. We will be using a tarball binary image non-root installation.



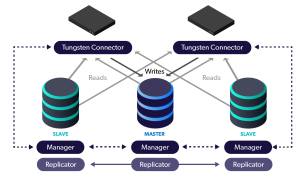 In this blog post, we demonstrate how to convert a single standalone cluster into a Composite Primary/DR topology running in two data centers.
In this blog post, we demonstrate how to convert a single standalone cluster into a Composite Primary/DR topology running in two data centers.







 In this post, I provide an illustration of how to use Pentaho Data Integration (PDI) tool to set up external dictionaries in MySQL to support ClickHouse. Although I use MySQL in this example, you can use any PDI supported source.
In this post, I provide an illustration of how to use Pentaho Data Integration (PDI) tool to set up external dictionaries in MySQL to support ClickHouse. Although I use MySQL in this example, you can use any PDI supported source.












 In this article we will discuss using the Active/Passive model to scale reads worldwide.
In this article we will discuss using the Active/Passive model to scale reads worldwide.