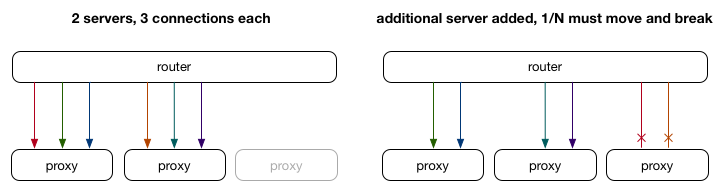
Recently one of our customers wanted us to benchmark InnoDB, TokuDB and RocksDB on Intel(R) Xeon(R) Gold 6140 CPU (with 72 CPUs), nvme SSD (7 TB) and 530 GB RAM for performance. We have used Ubuntu xenial 16.04.4, Percona Server 5.7 (included storage engines- InnoDB/XtraDB, TokuDB and RocksDB) and Sysbench 1.0.15 with custom Lua scripts for this exercise, This benchmarking exercise included bulk INSERTS, WRITES, READS and READS-WRITES. We have tried our best to capture maximum information about the hardware infrastructure and copied / shared scripts we have used for benchmarking. This is not a paid / sponsored benchmarking effort by any of the software or hardware vendors, We will remain forever an vendor neutral and independent web-scale database infrastructure operations company with core expertise in performance, scalability, high availability and database reliability engineering. This benchmarking is conducted by Shiv Iyer, You can contact him directly on shiv@minervadb.com to discuss more about this benchmarking project.
Hardware information
We have captured detailed information of the infrastructure (CPU, Diskand Memory) used for this benchmarking, This really helps anyone doing capacity planning / sizing of their database infrastructure.
CPU details (Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz with 72 CPUs)
root@blr1p01-pfm-008:/home/t-minervadb# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 72
On-line CPU(s) list: 0-71
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz
Stepping: 4
CPU MHz: 1000.000
CPU max MHz: 2301.0000
CPU min MHz: 1000.0000
BogoMIPS: 4601.52
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 25344K
NUMA node0 CPU(s): 0-17,36-53
NUMA node1 CPU(s): 18-35,54-71
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb invpcid_single intel_pt spec_ctrl retpoline kaiser tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx avx512f rdseed adx smap clflushopt clwb avx512cd xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts
Storage devices used for benchmarking (we used NVME SSD)
root@blr1p01-pfm-008:/home/t-minervadb# lsblk -io NAME,TYPE,SIZE,MOUNTPOINT,FSTYPE,MODEL
NAME TYPE SIZE MOUNTPOINT FSTYPE MODEL
sda disk 446.1G LSI2208
|-sda1 part 438.7G / ext4
`-sda2 part 7.5G [SWAP] swap
nvme0n1 disk 2.9T /mnt ext4 Micron_9200_MTFDHAL3T2TCU
nvme1n1 disk 2.9T Micron_9200_MTFDHAL3T2TCU
nvme2n1 disk 2.9T Micron_9200_MTFDHAL3T2TCU
nvme3n1 disk 2.9T Micron_9200_MTFDHAL3T2TCU
`-nvme3n1p1 part 128M
nvme4n1 disk 2.9T Micron_9200_MTFDHAL3T2TCU
`-nvme4n1p1 part 128M
nvme5n1 disk 2.9T Micron_9200_MTFDHAL3T2TCU
`-nvme5n1p1 part 128M
nvme6n1 disk 2.9T Micron_9200_MTFDHAL3T2TCU
`-nvme6n1p1 part 128M
nvme7n1 disk 2.9T Micron_9200_MTFDHAL3T2TCU
`-nvme7n1p1 part 128M
Memory
root@blr1p01-pfm-008:/home/t-minervadb# free
total used free shared buff/cache available
Mem: 527993080 33848440 480213336 18304 13931304 492519988
Swap: 7810044 0 7810044
root@blr1p01-pfm-008:/home/t-minervadb#
Benchmarking OLTP INSERT performance on TokuDB, RocksDB and InnoDB
TokuDB OLTP INSERT performance benchmarking using Sysbench
Building Database Infrastructure for benchmarking (Percona Server with TokuDB) with INSERT operations:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_insert.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD --mysql-storage-engine=tokudb prepare
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Initializing worker threads...
Creating table 'sbtest1'...
Inserting 100000000 records into 'sbtest1'
Creating a secondary index on 'sbtest1'...
“sbtest1” schema structure ( TokuDB storage engine with 100M rows)
mysql> show table status like 'sbtest1%'\G;
*************************** 1. row ***************************
Name: sbtest1
Engine: TokuDB
Version: 10
Row_format: tokudb_zlib
Rows: 100000000
Avg_row_length: 189
Data_length: 18900000000
Max_data_length: 9223372036854775807
Index_length: 860808942
Data_free: 18446744065817975570
Auto_increment: 100000001
Create_time: 2018-08-03 23:03:35
Update_time: 2018-08-03 23:23:51
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
Benchmarking TokuDB (with 100M rows) INSERT using Sysbench (oltp_insert.lua)
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_insert.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD --mysql-storage-engine=tokudb run
Monitoring the benchmarking
mysql> show full processlist\G;
*************************** 1. row ***************************
Id: 106
User: root
Host: localhost
db: test
Command: Query
Time: 0
State: update
Info: INSERT INTO sbtest1 (id, k, c, pad) VALUES (0, 49754892, '62632931051-58961919101-49940198850-21078424594-43546312816-91483171956-63147821178-73320074434-75390450161-85244468625', '72758152721-79346997448-32739052749-09956023061-33461120469')
Rows_sent: 0
Rows_examined: 0
*************************** 2. row ***************************
Id: 107
User: root
Host: localhost
db: test
Command: Query
Time: 0
State: update
Info: INSERT INTO sbtest1 (id, k, c, pad) VALUES (0, 38299901, '73492364485-17164009439-13897782190-82384134069-56725118845-05888552123-04466761496-73013947541-76946111000-82170241506', '57825848902-56599269429-55553620227-85565361679-86108748354')
Rows_sent: 0
Rows_examined: 0
*************************** 3. row ***************************
Id: 108
User: root
Host: localhost
db: test
Command: Query
Time: 0
State: closing tables
Info: INSERT INTO sbtest1 (id, k, c, pad) VALUES (0, 50461359, '82489034494-43306780333-31830745333-81619557910-15670574031-38606658735-35015531633-82686313168-29930813640-55800112343', '98734612239-15166737116-32153746057-36526618555-01917900606')
Rows_sent: 0
Rows_examined: 0
*************************** 4. row ***************************
Id: 109
User: root
Host: localhost
db: test
Command: Query
Time: 0
State: update
Info: INSERT INTO sbtest1 (id, k, c, pad) VALUES (0, 50305368, '26004165285-71866035101-19429620467-21730816230-28360163045-85578016857-31504027785-22011080750-52188150293-29047779256', '40086488864-24563838334-16649832399-35567929449-35827527600')
Rows_sent: 0
Rows_examined: 0
*************************** 98. row ***************************
Id: 203
User: root
Host: localhost
db: test
Command: Query
Time: 0
State: update
Info: INSERT INTO sbtest1 (id, k, c, pad) VALUES (0, 50008367, '08590860349-55330969614-92736003669-70093680275-08791372163-86879862146-65906035624-31616634007-39285699730-30091204027', '03546380555-08125979095-56416888610-57364610871-45465441885')
Rows_sent: 0
Rows_examined: 0
*************************** 99. row ***************************
Id: 204
User: root
Host: localhost
db: test
Command: Query
Time: 0
State: update
Info: INSERT INTO sbtest1 (id, k, c, pad) VALUES (0, 54541565, '62284574810-41408816172-84693515960-17097326417-15199773762-35816031089-51785557714-03836189148-75055812047-57404275889', '89419445215-23758954221-31182195029-89303506158-96423989766')
Rows_sent: 0
Rows_examined: 0
*************************** 100. row ***************************
Id: 205
User: root
Host: localhost
db: test
Command: Query
Time: 0
State: update
Info: INSERT INTO sbtest1 (id, k, c, pad) VALUES (0, 49961655, '04968809340-71773840704-69257717063-97968863839-17701720758-38065324563-11587467460-13905955489-57279753705-77707929689', '02758577051-41889982054-46749141829-07683639044-92209230468')
Rows_sent: 0
Rows_examined: 0
*************************** 101. row ***************************
Id: 206
User: root
Host: localhost
db: NULL
Command: Query
Time: 0
State: starting
Info: show full processlist
Rows_sent: 0
Rows_examined: 0
101 rows in set (0.00 sec)
ERROR:
No query specified
Result
When interpreting the benchmarking results, I look for transactions / queries per second (in this case, it is 10048.74 per sec.) and average latency (9.95 ms.) ,
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_insert.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD --mysql-storage-engine=tokudb run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 0
write: 18088064
other: 0
total: 18088064
transactions: 18088064 (10048.74 per sec.)
queries: 18088064 (10048.74 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 1800.0299s
total number of events: 18088064
Latency (ms):
min: 0.24
avg: 9.95
max: 210.80
95th percentile: 22.28
sum: 179905047.86
Threads fairness:
events (avg/stddev): 180880.6400/323.88
execution time (avg/stddev): 1799.0505/0.01
Benchmarking OLTP INSERT performance on RocksDB using Sysbench
Step 1 – Prepare data
sysbench oltp_insert.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD --mysql-storage-engine=rocksdb prepare
Step 2 – “sbtest1” schema structure ( RocksDB storage engine with 100M rows)
mysql> show table status like 'sbtest1'\G;
*************************** 1. row ***************************
Name: sbtest1
Engine: ROCKSDB
Version: 10
Row_format: Fixed
Rows: 100000000
Avg_row_length: 198
Data_length: 19855730417
Max_data_length: 0
Index_length: 750521287
Data_free: 0
Auto_increment: 100000001
Create_time: NULL
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.01 sec)
ERROR:
No query specified
Step3 – Benchmarking OLTP INSERT performance on RocksDB
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_insert.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD --mysql-storage-engine=rocksdb run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 0
write: 137298161
other: 0
total: 137298161
transactions: 137298161 (76275.15 per sec.)
queries: 137298161 (76275.15 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 1800.0344s
total number of events: 137298161
Latency (ms):
min: 0.29
avg: 1.31
max: 66.32
95th percentile: 1.67
sum: 179465859.14
Threads fairness:
events (avg/stddev): 1372981.6100/73.07
execution time (avg/stddev): 1794.6586/0.02
Interpreting results
Transactions / Queries (per second) – 76275.15
Average latency (ms) – 1.31
Benchmarking OLTP INSERT performance on InnoDB using Sysbench
Step 1 – prepare data for benchmarking
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_insert.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD prepare
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Initializing worker threads...
Creating table 'sbtest1'...
Inserting 100000000 records into 'sbtest1'
Creating a secondary index on 'sbtest1'...
Step 2 – “sbtest1” schema structure ( InnoDB storage engine with 100M rows)
mysql> show table status like 'sbtest1%'\G;
*************************** 1. row ***************************
Name: sbtest1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 98682155
Avg_row_length: 218
Data_length: 21611151360
Max_data_length: 0
Index_length: 0
Data_free: 3145728
Auto_increment: 100000001
Create_time: 2018-08-04 17:14:04
Update_time: 2018-08-04 17:11:01
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
Step3 – Benchmarking OLTP INSERT performance on InnoDB
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_insert.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 0
write: 42243914
other: 0
total: 42243914
transactions: 42243914 (23468.40 per sec.)
queries: 42243914 (23468.40 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 1800.0319s
total number of events: 42243914
Latency (ms):
min: 0.12
avg: 4.26
max: 1051.64
95th percentile: 21.50
sum: 179801087.85
Threads fairness:
events (avg/stddev): 422439.1400/1171.09
execution time (avg/stddev): 1798.0109/0.01
Interpreting results
Transactions / Queries (per second) – 23468.40
Average latency (ms) – 4.26
Graphical representation of OLTP INSERT performance in TokuDB, RocksDB and InnoDB:
![]()
![]()
![]()
Benchmarking OLTP READ-ONLY transactions performance on TokuDB, RocksDB and InnoDB
Benchmarking READ-ONLY OLTP transactions (100M records using oltp_read_only.lua) on TokuDB:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_only.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-storage-engine=tokudb --mysql-user=root --mysql-password=USEYOURPASSWORD prepare
Step 2- Confirm TokuDB schema is available with 100M records:
mysql> show table status like 'sbtest1%'\G;
*************************** 1. row ***************************
Name: sbtest1
Engine: TokuDB
Version: 10
Row_format: tokudb_zlib
Rows: 100000000
Avg_row_length: 189
Data_length: 18900000000
Max_data_length: 9223372036854775807
Index_length: 860426496
Data_free: 18446744065835135232
Auto_increment: 100000001
Create_time: 2018-08-05 12:53:50
Update_time: 2018-08-05 13:13:38
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
Step 3 – Benchmarking TokuDB OLTP READ-ONLY transaction performance:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_only.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-storage-engine=tokudb --mysql-user=root --mysql-password=USEYOURPASSWORD run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 231960820
write: 0
other: 33137260
total: 265098080
transactions: 16568630 (9204.59 per sec.)
queries: 265098080 (147273.50 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 1800.0348s
total number of events: 16568630
Latency (ms):
min: 1.71
avg: 10.86
max: 51.11
95th percentile: 13.22
sum: 179951191.99
Threads fairness:
events (avg/stddev): 165686.3000/481.89
execution time (avg/stddev): 1799.5119/0.01
Interpreting results
QPS (Queries per second) – 147273.50
Average latency (ms) – 10.86
Benchmarking READ-ONLY OLTP transactions on RocksDB
Step 1- Build data(100M records using oltp_read_only.lua) for benchmarking:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_only.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-storage-engine=rocksdb --mysql-user=root --mysql-password=USEYOURPASSWORD prepare
Step 2- Confirm RocksDB schema is available with 100M records:
mysql> show table status like 'sbtest%'\G;
*************************** 1. row ***************************
Name: sbtest1
Engine: ROCKSDB
Version: 10
Row_format: Fixed
Rows: 100000000
Avg_row_length: 198
Data_length: 19855730417
Max_data_length: 0
Index_length: 750521333
Data_free: 0
Auto_increment: 100000001
Create_time: NULL
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
Step 3 – Benchmarking RocksDB OLTP READ-ONLY transaction performance:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_only.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-storage-engine=rocksdb --mysql-user=root --mysql-password=USEYOURPASSWORD run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 494461100
write: 0
other: 70637300
total: 565098400
transactions: 35318650 (19621.05 per sec.)
queries: 565098400 (313936.76 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 1800.0349s
total number of events: 35318650
Latency (ms):
min: 1.80
avg: 5.09
max: 323.58
95th percentile: 7.70
sum: 179898262.01
Threads fairness:
events (avg/stddev): 353186.5000/2619.22
execution time (avg/stddev): 1798.9826/0.02
Interpreting results
QPS (Queries per second) – 313936.76
Average latency (ms) – 5.09
Benchmarking READ-ONLY OLTP transactions on InnoDB
Step 1: Build data (100M records using oltp_read_only.lua) for benchmarking:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_only.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD prepare
Step 2 – Step 2- Confirm InnoDB schema is available with 100M records:
mysql> show table status like 'sbtest1'\G;
*************************** 1. row ***************************
Name: sbtest1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 98650703
Avg_row_length: 224
Data_length: 22126002176
Max_data_length: 0
Index_length: 0
Data_free: 3145728
Auto_increment: 100000001
Create_time: 2018-08-05 17:20:48
Update_time: 2018-08-05 17:18:19
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
Step 3 – Benchmarking InnoDB OLTP READ-ONLY transaction performance:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_only.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 251061874
write: 0
other: 35865982
total: 286927856
transactions: 17932991 (9962.59 per sec.)
queries: 286927856 (159401.44 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 1800.0300s
total number of events: 17932991
Latency (ms):
min: 1.66
avg: 10.03
max: 1478.79
95th percentile: 33.12
sum: 179947481.25
Threads fairness:
events (avg/stddev): 179329.9100/1283.20
execution time (avg/stddev): 1799.4748/0.01
Interpreting results
QPS (Queries per second) – 159401.44
Average latency (ms) – 10.03
Graphical representation of OLTP READ-ONLY transactions performance in TokuDB, RocksDB and InnoDB:
![]()
![]()
![]()
Benchmarking OLTP READ-WRITE transactions performance on TokuDB, RocksDB and InnoDB
Benchmarking READ-WRITE OLTP transactions on TokuDB
Step 1: Build data (100M records using oltp_read_write.lua) for benchmarking:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_write.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-storage-engine=tokudb --mysql-user=root --mysql-password=USEYOURPASSWORD prepare
Step 2- Confirm TokuDB schema is available with 100M records:
mysql> show table status like 'sbtest1%'\G;
*************************** 1. row ***************************
Name: sbtest1
Engine: TokuDB
Version: 10
Row_format: tokudb_zlib
Rows: 100000000
Avg_row_length: 189
Data_length: 18900000000
Max_data_length: 9223372036854775807
Index_length: 860645232
Data_free: 18446744065834916496
Auto_increment: 100000001
Create_time: 2018-08-05 22:41:43
Update_time: 2018-08-05 23:01:00
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
Step3 – Benchmarking OLTP READ-WRITE performance on TokuDB:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_write.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-storage-engine=tokudb --mysql-user=root --mysql-password=USEYOURPASSWORD run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 19844342
write: 5669812
other: 2834906
total: 28349060
transactions: 1417453 (787.44 per sec.)
queries: 28349060 (15748.86 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 1800.0668s
total number of events: 1417453
Latency (ms):
min: 3.90
avg: 126.99
max: 426.41
95th percentile: 147.61
sum: 179997357.31
Threads fairness:
events (avg/stddev): 14174.5300/7.61
execution time (avg/stddev): 1799.9736/0.02
Interpreting results
QPS (Queries per second) – 15748.86
Average latency (ms) – 126.99
Benchmarking READ-WRITE OLTP transactions on RocksDB
Step 1: Build data (100M records using oltp_read_write.lua) for benchmarking:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_write.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-storage-engine=rocksdb --mysql-user=root --mysql-password=USEYOURPASSWORD prepare
Step 2- Confirm RocksDB schema is available with 100M records:
mysql> show table status like 'sbtest1%'\G;
*************************** 1. row ***************************
Name: sbtest1
Engine: ROCKSDB
Version: 10
Row_format: Fixed
Rows: 100000000
Avg_row_length: 198
Data_length: 19855694789
Max_data_length: 0
Index_length: 750521319
Data_free: 0
Auto_increment: 100000001
Create_time: NULL
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
Step3 – Benchmarking OLTP READ-WRITE performance on RocksDB:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_write.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-storage-engine=rocksdb --mysql-user=root --mysql-password=USEYOURPASSWORD run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 286818014
write: 81910410
other: 40961372
total: 409689796
transactions: 20474371 (11374.39 per sec.)
queries: 409689796 (227600.23 per sec.)
ignored errors: 12630 (7.02 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 1800.0375s
total number of events: 20474371
Latency (ms):
min: 2.50
avg: 8.79
max: 402.68
95th percentile: 12.75
sum: 179935638.52
Threads fairness:
events (avg/stddev): 204743.7100/2264.14
execution time (avg/stddev): 1799.3564/0.01
Interpreting results
QPS (Queries per second) – 227600.23
Average latency (ms) – 8.79
Benchmarking READ-WRITE OLTP transactions on InnoDB
Step 1: Build data (100M records using oltp_read_write.lua) for benchmarking:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_write.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD prepare
Step 2- Confirm InnoDB schema is available with 100M records:
mysql> show table status like 'sbtest1%'\G;
*************************** 1. row ***************************
Name: sbtest1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 100000000
Avg_row_length: 221
Data_length: 21885878272
Max_data_length: 0
Index_length: 0
Data_free: 6291456
Auto_increment: 100000001
Create_time: 2018-08-06 10:24:54
Update_time: 2018-08-06 10:31:53
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
ERROR:
No query specified
Step3 – Benchmarking OLTP READ-WRITE performance on InnoDB:
root@blr1p01-pfm-008:/usr/share/sysbench# sysbench oltp_read_write.lua --threads=100 --time=1800 --table-size=100000000 --db-driver=mysql --mysql-db=test --mysql-socket=/var/run/mysqld/mysqld.sock --mysql-user=root --mysql-password=USEYOURPASSWORD run
sysbench 1.0.15 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 100
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 67383470
write: 19251931
other: 9626043
total: 96261444
transactions: 4812938 (2673.78 per sec.)
queries: 96261444 (53477.03 per sec.)
ignored errors: 167 (0.09 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 1800.0491s
total number of events: 4812938
Latency (ms):
min: 2.28
avg: 37.40
max: 1177.78
95th percentile: 71.83
sum: 179981855.37
Threads fairness:
events (avg/stddev): 48129.3800/110.24
execution time (avg/stddev): 1799.8186/0.00
Interpreting results
QPS (Queries per second) – 53477.03
Average latency (ms) – 37.40
Graphical representation of OLTP READ-WRITE transactions performance in TokuDB, RocksDB and InnoDB:
![]()
![]()
![]()
Conclusion
The results of benchmarking concluded RocksDB the most ideal candidate for SSD based storage infrastructure compared to InnoDB and TokuDB, The most compelling reasons for using RocksDB on SSD are storage efficiency, compression and much smaller write amplification compared to InnoDB or TokuDB.
The post Comparing TokuDB, RocksDB and InnoDB Performance on Intel(R) Xeon(R) Gold 6140 CPU appeared first on MySQL Consulting, Support and Remote DBA Services.














 Please join Percona’s Architect, Tibi Köröcz as he presents
Please join Percona’s Architect, Tibi Köröcz as he presents 
 In this blog post, we talk about how to run applications across multiple clouds (i.e. AWS, Google Cloud, Microsoft Azure) using
In this blog post, we talk about how to run applications across multiple clouds (i.e. AWS, Google Cloud, Microsoft Azure) using 







 PMM (
PMM (















 Join Percona Chief Evangelist Colin Charles as he covers happenings, gives pointers and provides musings on the open source database community.
Join Percona Chief Evangelist Colin Charles as he covers happenings, gives pointers and provides musings on the open source database community.