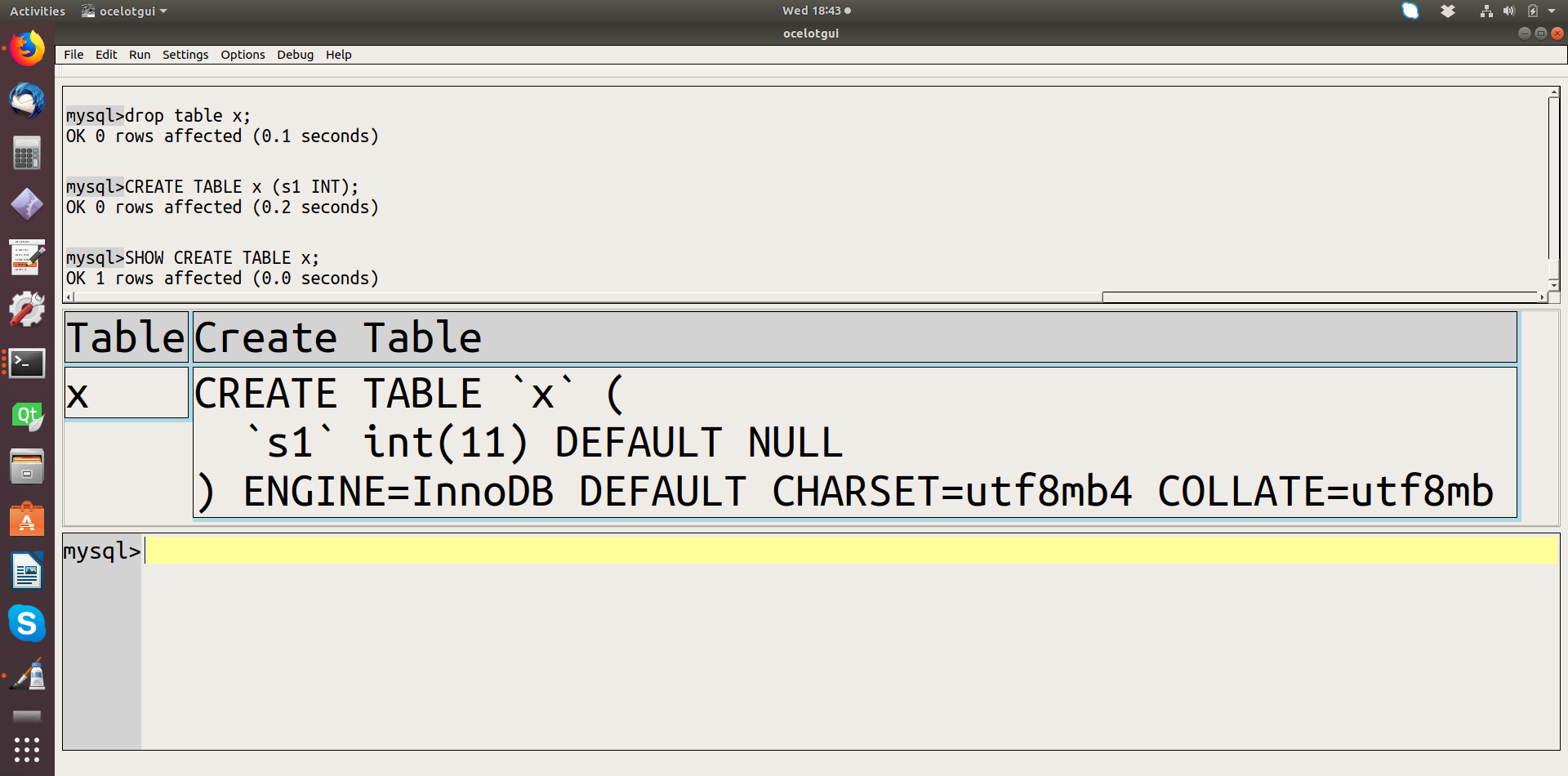
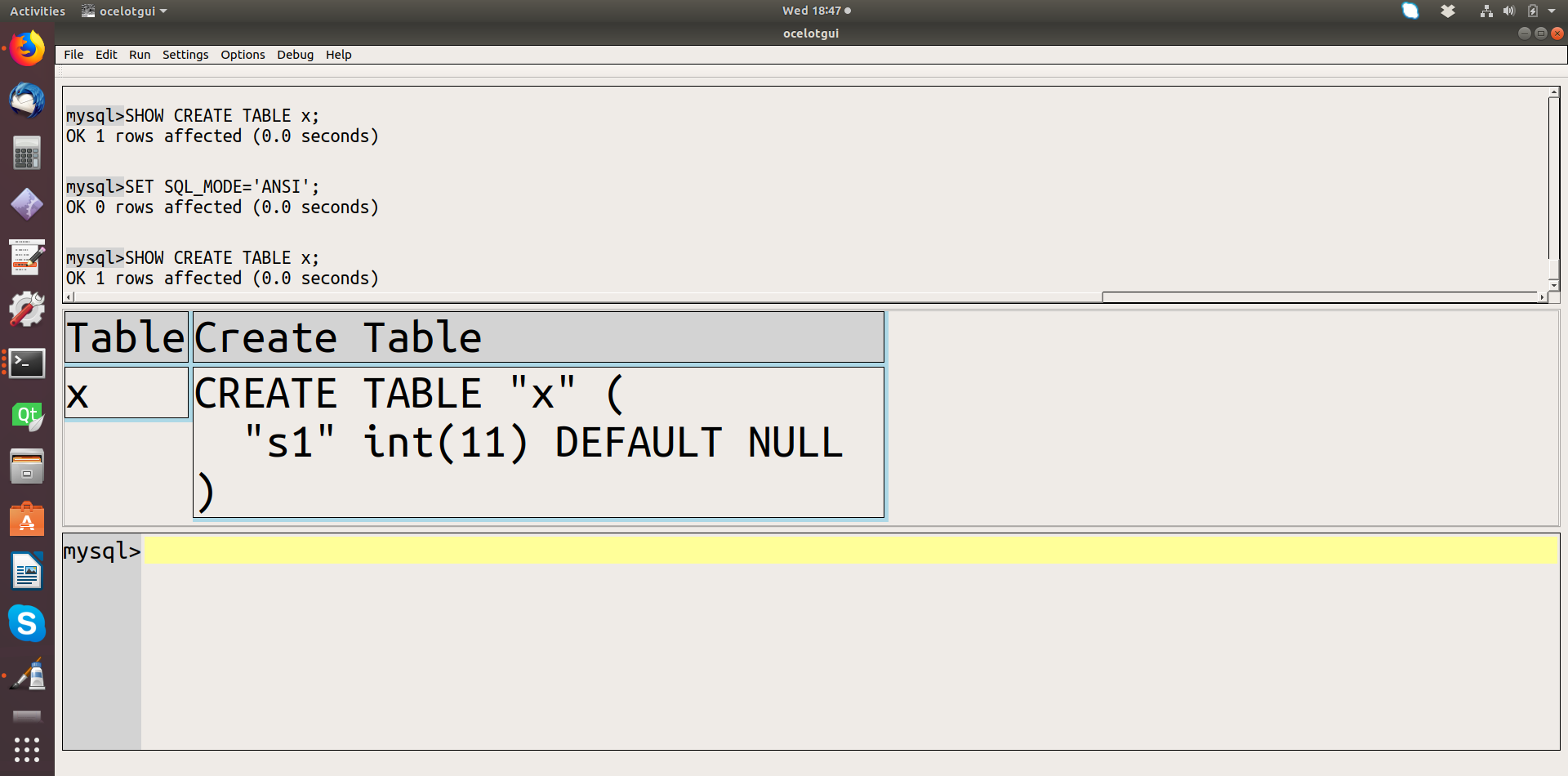
ClusterControl’s agentless approach allows sysadmins and DBAs to monitoring their databases without having to install agent software on each monitored system. Monitoring is implemented using a remote data collector that uses the SSH protocol.
But first, let’s clarify the scope and meaning of monitoring within our context here. Monitoring comes after data trending - the metrics collection and storing process - which allows the monitoring system to process the collected data to produce justification for tuning, alerting, as well as displaying trending data for reporting.
Generally, ClusterControl performs its monitoring, alerting and trending duties by using the following three ways:
- SSH - Host metrics collection (process, load balancers stats, resource usage and consumption etc) using SSH library.
- Database client - Database metrics collection (status, queries, variables, usage etc) using the respective database client library.
- Advisor - Mini programs written using ClusterControl DSL and running within ClusterControl itself, for monitoring, tuning and alerting purposes.
Some description of the above - SSH stands for Secure Shell, a secure network protocol which is used by most of the Linux-based servers for remote administration. ClusterControl Controller, or CMON, is the backend service performing automation, management, monitoring and scheduling tasks, built on top of C++.
ClusterControl DSL (Domain Specific Language) allows you to extend the functionality of your ClusterControl platform by creating Advisors, Auto Tuners, or "Mini Programs". The DSL syntax is based on JavaScript, with extensions to provide access to ClusterControl internal data structures and functions. The DSL allows you to execute SQL statements, run shell commands/programs across all your cluster hosts, and retrieve results to be processed for advisors/alerts or any other actions.
Monitoring Tools
All of the prerequisite tools will be met by the installer script or will be automatically installed by ClusterControl during the database deployment stage, or if the required file/binary/package does not exist on the target server before executing a job. Generally speaking, ClusterControl monitoring duty only requires OpenSSH server package on the monitored hosts. ClusterControl uses libssh client library to collect host metrics for the monitored hosts - CPU, memory, disk, network, IO, process, etc. OpenSSH client package is required on the ClusterControl host only for setting up passwordless SSH and debugging purposes. Other SSH implementations like Dropbear and TinySSH are not supported.
When gathering the database stats and metrics, ClusterControl Controller (CMON) connects to the database server directly via database client libraries - libmysqlclient (MySQL/MariaDB and ProxySQL), libpq (PostgreSQL) and libmongocxx (MongoDB). That is why it's crucial to setup proper privileges for ClusterControl server from database servers perspective. For MySQL-based clusters, ClusterControl requires database user "cmon" while for other databases, any username can be used for monitoring, as long as it is granted with super-user privileges. Most of the time, ClusterControl will setup the required privileges (or use the specified database user) automatically during the cluster import or cluster deployment stage.
For load balancers, ClusterControl requires the following tools:
- Maxadmin on the MariaDB MaxScale server.
- netcat and/or socat on the HAProxy server to connect to HAProxy socket file and retrieve the monitoring data.
- ProxySQL requires mysql client on the ProxySQL server.
The following diagram illustrates both host and database monitoring processes executed by ClusterControl using libssh and database client libraries:
Although monitoring threads do not need database client packages to be installed on the monitored host, it's highly recommended to have them for management purposes. For example, MySQL client package comes with mysql, mysqldump, mysqlbinlog and mysqladmin programs which will be used by ClusterControl when performing backups and point-in-time recovery.
Monitoring Methods
For host and load balancer stats collection, ClusterControl executes this task via SSH with super-user privilege. Therefore, passwordless SSH with super-user privilege is vital, to allow ClusterControl to run the necessary commands remotely with proper escalation. With this pull approach, there are a couple of advantages as compared to other mechanisms:
- Agentless - There is no need for agent to be installed, configured and maintained.
- Unifying the management and monitoring configuration - SSH can be used to pull monitoring metrics or push management jobs on the target nodes.
- Simplify the deployment - The only requirement is proper passwordless SSH setup and that's it. SSH is also very secure and encrypted.
- Centralized setup - One ClusterControl server can manage multiple servers and clusters, provided it has sufficient resources.
However, there are also drawbacks with the pull mechanism:
- The monitoring data is accurate only from ClusterControl perspective. For example, if there is a network glitch and ClusterControl loses communication to the monitored host, the sampling will be skipped until the next available cycle.
- For high granularity monitoring, there will be network overhead due to increase sampling rate where ClusterControl needs to establish more connections to every target hosts.
- ClusterControl will keep on attempting to re-establish connection to the target node, because it has no agent to do this on its behalf.
- Redundant data sampling if you have more than one ClusterControl server monitoring a cluster, since each ClusterControl server has to pull the monitoring data for itself.
For MySQL query monitoring, ClusterControl monitors the queries in two different ways:
- Queries are retrieved from PERFORMANCE_SCHEMA, by querying the schema on the database node via SSH.
- If PERFORMANCE_SCHEMA is disabled or unavailable, ClusterControl will parse the content of the Slow Query Log via SSH.
If Performance Schema is enabled, ClusterControl will use it to look for the slow queries. Otherwise, ClusterControl will parse the content of the MySQL slow query log (via slow_query_log=ON dynamic variable) based on the following flow:
- Start slow log (during MySQL runtime).
- Run it for a short period of time (a second or couple of seconds).
- Stop log.
- Parse log.
- Truncate log (new log file).
- Go to 1.
The collected queries are hashed, calculated and digested (normalize, average, count, sort) and then stored in ClusterControl CMON database. Take note that for this sampling method, there is a slight chance some queries will not be captured, especially during “stop log, parse log, truncate log” parts. You can enable Performance Schema if this is not an option.
If you are using the Slow Query log, only queries that exceed the Long Query Time will be listed here. If the data is not populated correctly and you believe that there should be something in there, it could be:
- ClusterControl did not collect enough queries to summarize and populate data. Try to lower the Long Query Time.
- You have configured Slow Query Log configuration options in the my.cnf of MySQL server, and Override Local Query is turned off. If you really want to use the value you defined inside my.cnf, probably you have to lower the long_query_time value so ClusterControl can calculate a more accurate result.
- You have another ClusterControl node pulling the Slow Query log as well (in case you have a standby ClusterControl server). Only allow one ClusterControl server to do this job.
For more details (including how to enable the PERFORMANCE_SCHEMA), see this blog post, How to use the ClusterControl Query Monitor for MySQL, MariaDB and Percona Server.
For PostgreSQL query monitoring, ClusterControl requires pg_stat_statements module, to track execution statistics of all SQL statements. It populates the pg_stat_statements views and functions when displaying the queries in the UI (under Query Monitor tab).
Intervals and Timeouts
ClusterControl Controller (cmon) is a multi-threaded process. By default, ClusterControl Controller sampling thread connects to each monitored host once and maintain persistent connection until the host drops or disconnects it when sampling host stats. It may establish more connections depending on the jobs assigned to the host, since most of the management jobs run in their own thread. For example, cluster recovery runs on the recovery thread, Advisor execution runs on a cron-thread, as well as process monitoring which runs on process collector thread.
ClusterControl monitoring thread performs the following sampling operations in the following interval:
- MySQL query/status metrics: every second
- Process collection (/proc): every 10 seconds
- Server detection: every 10 seconds
- Host metrics (/proc, /sys): every 30 seconds (configurable via host_stats_collection_interval)
- Database metrics (PostgreSQL and MongoDB only): every 30 seconds (configurable via db_stats_collection_interval)
- Database schema metrics: every 3 hours (configurable via db_schema_stats_collection_interval)
- Load balancer metrics: every 15 seconds (configurable via lb_stats_collection_interval)
The imperative scripts (Advisors) can make use of SSH and database client libraries that come with CMON with the following restrictions:
- 5 seconds of hard limit for SSH execution,
- 10 seconds of default limit for database connection, configurable via net_read_timeout, net_write_timeout, connect_timeout in CMON configuration file,
- 60 seconds of total script execution time limit before CMON ungracefully aborts it.
Advisors can be created, compiled, tested and scheduled directly from ClusterControl UI, under Manage -> Developer Studio. The following screenshot shows an example of an Advisor to extract top 10 queries from PERFORMANCE_SCHEMA:
The execution of advisors is depending if it is activated and the scheduling time in cron format:
The results of the execution are displayed under Performance -> Advisors, as shown in the following screenshot:
For more information on what Advisors being provided by default, check out our Developer Studio product page.
For short-interval monitoring data like MySQL queries and status, data are stored directly into CMON database. While for long-interval monitoring data like weekly/monthly/yearly data points are aggregated every 60 seconds and stored in memory for 10 minutes. These behaviours are not configurable due to the architecture design.
Single Console for Your Entire Database Infrastructure
Find out what else is new in ClusterControl
Parameters
There are plethora of parameters you can configure for ClusterControl to suit your monitoring and alerting policy. Most of them are configurable through ClusterControl UI -> pick a cluster -> Settings. The "Settings" tab provide many options to configure alerts, thresholds, notifications, graphs layout, database counters, query monitoring and so on. For example, warning and critical thresholds can be configured as follows:
There are also "Runtime Configuration" page, a summarized list of the active ClusterControl Controller (CMON) runtime configuration parameters:
There are more than 170 ClusterControl Controller configuration options in total and some of the advanced settings can be configured to finely tune your monitoring and alerting policy. To list out some of them:
- monitor_cpu_temperature
- swap_warning
- swap_critical
- redobuffer_warning
- redobuffer_critical
- indexmemory_warning
- indexmemory_critical
- datamemory_warning
- datamemory_critical
- tablespace_warning
- tablespace_critical
- redolog_warning
- redolog_critical
- max_replication_lag
- long_query_time
- log_queries_not_using_indexes
- query_monitor_use_local_settings
- enable_query_monitor
- enable_query_monitor_auto_purge_ps
The parameters listed in the "Runtime Configuration" page can be changed either by using the UI or CMON configuration file located at /etc/cmon.d/cmon_X.cnf, where X is the cluster ID. You can list out all of the supported configuration options for CMON by using the following command:
$ cmon --help-config
The same output is also available in the documentation page, ClusterControl Controller Configuration Options.
Final Thoughts
We hope this blog has given you a good understanding of how ClusterControl monitors your database servers and clusters agentlessly. We’ll be shortly announcing some significant new features in the next version of ClusterControl so stay tuned!










 Join Percona Chief Evangelist Colin Charles as he covers happenings, gives pointers and provides musings on the open source database community.
Join Percona Chief Evangelist Colin Charles as he covers happenings, gives pointers and provides musings on the open source database community.















 Do you need to modify the metrics collected from Linux by
Do you need to modify the metrics collected from Linux by