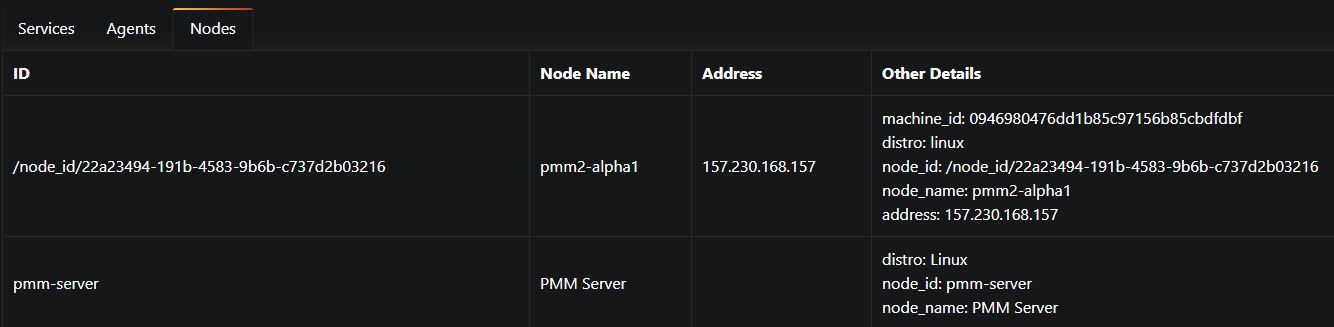
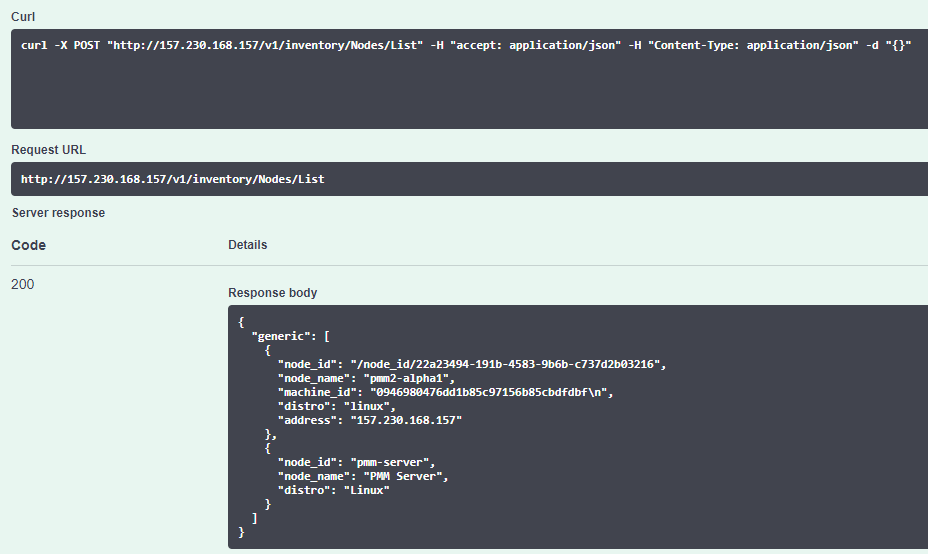
Series Introduction
Back in 2016 I decided to write a blog series on InnoDB in hopes that it would help give a good description of the high level mechanics of the storage engine. The main motivating factor at that time was that I knew there was a lot of information out there about InnoDB, but a lot of it was ambiguous or even contradictory and I wanted to help make things a bit clearer if I could.
Now there’s a new storage engine that’s rising in popularity that I feel needs similar attention. Specifically MyRocks, the log-structured merge-driven RocksDB engine in MySQL. Given the amount of discussion in the community about MyRocks, I’m sure most of you already have some degree of familiarity, or at the very least have heard the name.
Now we’ve arrived at a point where this is no longer just a Facebook integration project and major players in the community like Maria and Percona have their own implemented solutions that come packaged with their respective binaries. Things even went a bit further in December of 2018 when Percona announced that TokuDB would be deprecated encouraged its users to explore MyRocks. This is when I decided we needed to take this engine a little more seriously, dig in, see how it works and what it has to offer.
Unlike InnoDB I found that the problem was not an overabundance of ambiguous information, but instead only small amounts of information that was scattered between various wikis, blog posts, and presentation slides. This initially made researching difficult, but as I came to know the engine better things got clearer and clearer. My hope is to take what I’ve learned and pass it along to you in a way that can help you gain the familiarity and confidence you need to explore this technology.
Much like my InnoDB series, I’m drafting this by presenting system variables in an order where the topics discussed for one variable lead to the next, and then to the next, and so on. Though I have to note here that my series on InnoDB was largely based on production experience, whereas this blog series is based on research and lab testing. I feel confident in the definitions that I’ve provided, but the recommendations are based more on theory than anything else.
With this in mind I would like to offer the same disclaimer I provided for my InnoDB series.
“….I should note that while tuning recommendations are provided, this objective of this blog post series is NOT meant to be a tuning primer, but instead to explore the mechanics that each variable interacts with…”
Let’s get started!!
Rows vs. Key-Value
The first thing that needs to be clarified when we talk about MyRocks is that it’s a storage engine that converts your MySQL requests into requests for the RocksDB engine that come packaged with the installation. Unlike MySQL, RocksDB is not a relational database and instead is a key-value store. When you enter column-based records into MyRocks, a process transparently converts them into key-value records.
The key of the record is a combination of an internal index id and the primary key as defined by your create table statement, if available. You can read more about this starting on slide 46 of this tutorial presentation. The value holds any record metadata plus the non-primary key columns. Just keep this in mind as we continue through the blog series as there will be several usages of the term ‘key’ which can mean either the primary key value of the table or the key component of the RocksDB key-value backend.
You can read more about the key-value format of MyRocks / RocksDB by checking the MyRocks record format page on the Facebook MyRocks Wiki.
Column Families
Data that is converted by MyRocks from row format to key-value format is stored in column families. A column family in RocksDB is like a table for an engine like InnoDB or MYISAM. The usage of column families in MyRocks from the perspective of MySQL is almost completely transparent. You will still query tables in MySQL and on the back end your requests will be converted to use column families, much like how row-level data and key-value data are converted transparently.
When you create a table in MyRocks, you will specify what column family the table belongs to. If the table has any secondary indexes you can specify what column families those indexes belong to. Keep in mind that a table and its secondary indexes don’t need to be in the same column family, and in contrast, you can have multiple tables and indexes in the same column family.
You create a column family by using the create table statement and noting the name of the column family as part of a comment for the primary key like in the example below where we create a table t1 and place it in the column family cf_t1.
CREATE TABLE `t1` (
`c1` int(10) unsigned NOT NULL AUTO_INCREMENT,
`c2` char(255) NOT NULL,
PRIMARY KEY (`c1`) COMMENT 'cf_t1'
) ENGINE=ROCKSDB DEFAULT CHARSET=latin1
If we wanted to we could create another table and place it in the cf_t1 column family by using the same comment.
In the case that we do not provide a comment in the create table statement, the table and its secondary indexes will call be created in the ‘default’ column family, which is automatically created when MyRocks is installed.
Each column family is going to have its own resources, data files, memory caches, etc. Creating multiple column families will help reduce the chances of resource contention found with putting everything in a single column family. There is no solid recommendation as to how many column families you should use, but per Yoshinori Matsunobu MyRocks Introduction Slides (slide 52 to be specific), you should aim to create no more than 20.
You can find more information about column families and how to create them on the Getting Started with MyRocks page in the facebook MyRocks wiki.
System Variables vs. Column Family Options
Now that we know a little bit about column families, we should address how configuration works for MyRocks. This whole blog series looks at mechanics from the variable / option perspective, so knowing how to configure those variables and options would be handy!
MyRocks still uses system variables, but it can also be configured using column family options. Earlier I pointed out that column families have their own resources. You can configure options for these resources for each column family independently if you like.
You can see the column family option settings by looking at the information_schema.ROCKSDB_CF_OPTIONS table. It will show you each column family, the option type, and the option value. You’re going to want to be aware of the fact that there is a difference between system variables, which more often than not designate global level settings for MyRocks, and column family options, which are more specific to each column family.
To make things even more confusing, you should know that sometimes column family options are set by system variables, but more often than not they’re set using the variable rocksdb_default_cf_options, which allows you to pass in a list of settings and subsettings that would be the default option for each column family. A good example of this can be found in Mark Callaghan’s blog post on default values for MyRocks.
If you change the default option for column families using the variable rocksdb_default_cf_options and restart MySQL, all column families will take on the new settings immediately.
Rocksdb_default_cf_options is used to set default column family options, but you can further specify options for each column family using rocksdb_override_cf_options. You can see an example of using overrides in Alexey Maykov’s presentation on MyRocks Internals slide 24.
The important takeaway here is that you configure MyRocks using both system variables and column family options. Below we’re going to start talking about these variables, settings, and the associated mechanic. If I’m referring to a column family option the heading will be prefixed with ‘CF_OPTION’, if I’m referring to a system variable there will be no prefix.
In-Memory Data Writes
Ok, now we know about row format, column families, and how to configure MyRocks. Now we can start digging into the details of how MyRocks works.
New data or data changes occurring in MyRocks first get written to a memory space called a “memtable”. Each column family will have its own memtable. As the data gets written into memory, a log of the changes gets written to a write-ahead log. In the case that a crash occurs between the time the data is written into the memtable and the time that memtable data gets flushed to disk, the write-ahead log can be used to replay the data changes that occurred so that MyRocks can recover and pick up right where it left off.
For those of you that are familiar with InnoDB, this is going to sound a lot like how data initially gets written in the buffer pool along with data changes being entered into the InnoDB redo logs. This is a very common method of ensuring data durability as a part of achieving ACID compliance.
![]()
Memtables have a size limit, which by default is 64Mb. Once the memtable fills up it’s converted to what’s called an “immutable memtable”. Immutable means that the data in that memtable can no longer be changed. In order to continue handling data write requests, a new memtable, now called the “active memtable”, is created to handle new write requests while the immutable memtable is rotated out so its data can be written to disk.
![]()
Variables and CF_OPTIONS
Let’s take a more detailed look at the mechanics associated with column families and memtables as well as the variables that are associated with them.
Rocksdb_no_create_column_family
A mentioned above, you create column families using comments in the create table statement. You may want to include a safety measure in your system to ensure that new column families aren’t created, in order to keep your column family count under control.
The variable rocksdb_no_create_column_family allows you to prevent the creation of new column families via use of comments. If the variable is enabled and if you attempt to create a new column family using this method, you will get an error.
Default: OFF
I can see how someone may want to protect their system to ensure that no unexpected column families are created, but one important factor to consider is that this variable is not dynamic, meaning if you were to enable it you would need to restart MySQL in order to create a new column family and I think that is enough to justify leaving this variable disabled.
CF_OPTION write_buffer_size
As mentioned earlier, data initially gets written into MyRocks column families using memtables. There is one active memtable for each column family in MyRocks.
The column family option write_buffer_size designates how large the memtable will be.
Default: 67108864 (64Mb)
CF_OPTION min_write_buffer_number_to_merge
Once an active memtable is full, it will be converted into an immutable memtable so it can then be read and flushed to disk. However, this can be extended so that you can have multiple immutable memtables collected prior to a flush. This is controlled by the column family option min_write_buffer_number_to_merge. The value of this option will designate how many immutable memtables to create before starting the flushing process.
For example, if you have this value set to 2, as you write data into the active memtable and it fills, it will become immutable and a new memtable will take its place, but flushing won’t occur. Writes will continue and eventually, the new active memtable will fill, be converted to immutable, and replaced. You now have 2 immutable tables and at this point, the call to flush will occur.
I should note that I do believe the definition for this column family option is accurate; however, during my testing, I found that regardless of what I set this option to, I was never able to create more than one immutable memtable. I have created a bug with Percona to raise this issue with them.
Default: 1
I would be inclined to leave this variable at its default value. If you increase it, you will decrease the number of times data is flushed to disk, but each flush will be larger, and as a result, creating larger bursts of disk activity. If your immutable memtables aren’t finished flushing and your active memtable fills to capacity, then writes will stop until the flush can complete.
Rocksdb_db_write_buffer_size
All column families will have their own active and immutable memtables, meaning the amount of memory used by writes would be equal to the number of active memory tables and immutable memory tables multiplied by the number of column families you have. If you’re not paying attention to your configuration and add a lot of column families, this may use more memory than you anticipated and could potentially lead to OOMs. However, you can protect yourself from this by using the rocksdb_db_write_buffer_size variable. In order to prevent excessive memory use, this variable will put a cap on the total amount of memory that should be used across all active memtables. This will have no impact on immutable memtables.
For example, if you have two column families with active memtables at 64Mb each, but have this variable set to 32Mb, MyRocks will attempt to rotate active memtables to immutable before the 32Mb cap is hit. However, if you expand this to a greater value such as 128Mb, then no restrictions will apply as the two 64Mb tables can only use 128Mb.
Again, it’s important to note that this has no impact on the amount of memory used by immutable memtables. So consider the example of having two column families with a 64Mb write_buffer_size and a min_write_buffer_number_to_merge value of 1. If you have the rocksdb_db_write_buffer_size set to 64Mb, it’s possible to have one column family with a full active memtable and a full immutable memtable, as well as having a full immutable memtable, meaning you have 192Mb of memory used.
I would say that the best way to approach this is that the maximum memory capacity used by the write buffers across all column families would be this value plus the maximum potential of all immutable memtables across all column families.
One thing I would like to note is that if you check the documentation for this variable at the time of this writing it states that this is the write buffer size per column family. However, in my testing, I showed that this setting is more of a global scope. As such, I wrote this blog post to reflect what my testing showed given that I believe what I have provided is the proper definition. I’ve opened a bug report with Percona to report this.
Default: 0
The default of 0 indicates that there is no upper limit for how much memory can be used by active memtables in the MyRocks instance.
I personally do not prefer having unrestricted caches as I’ve seen enough out of memory kills of MySQL to be wary. You’ll need to consider how many column families you wish to create, and how tolerant you are of the number of flushes being performed. Also, keep in mind that while memtables will be used for reads, it’s not anywhere near as important as the block cache (handled caching for reads will be covered in a later post). You won’t want to give memtables a majority share of physical memory like you would for something like the InnoDB Buffer Pool, for those of you who are familiar.
Rocksdb_allow_concurrent_memtable_write
Enabling this variable will allow multiple threads to write to the same memtable concurrently. If this is not enabled, then multiple threads will have to write to the memtable in a sequential fashion.
It should be noted that this is only available for the memtable factory ‘SkipList’. RocksDB allows for memtables to be stored in different formats and these are called “factories”. If you’re familiar with InnoDB you can think of this kind of like a row format. You can find information about the different memtable factories and their different features on this page in the Facebook RocksDB Github Wiki, but I believe that going deep into the details on this particular topic may be premature given that, as far as I’m aware, SkipList is the only memtable factory supported by MyRocks for now.
While it’s possible that you may see performance increases in some use cases by enabling this feature, as seen in this blog post by Mark Callaghan, it does come at the cost of losing in-place updates and filter deletes, meaning some DML statements that update or delete data may be impacted by enabling this feature.
Also, if you are going to enable this feature, you will also need to enable the rocksdb_enable_write_thread_adaptive_yield variable, which is the next variable covered in this blog post.
Default: OFF
As noted above, enabling this feature may increase write-only workload, but at the cost of modifying data after insert. I would recommend testing this with appropriate performance benchmarks prior to implementation in production.
Rocksdb_enable_write_thread_adaptive_yield
By default writes are not grouped, regardless of whether or not you are writing to a single column family or multiple column families. When you enable this variable you allow grouping to occur as mutexes for writing to memtables will occur on a timed basis instead of occurring as part of each transaction commit.
Default: OFF
Per the comments in RocksDB options.h file, enabling this may allow for additional throughput for concurrent workloads, but there is very little documentation out there to suggest what the negative impact of enabling this variable may be. It’s recommended to test this thoroughly before enabling in production.
Rocksdb_max_total_wal_size
As data is written into the memtables, it is also written into the write-ahead log. The purpose of the write-ahead log is to store information about committed data changes in order to ensure that the changes can be recovered in case of a crash. For those of you that have a familiarity with InnoDB, this plays the same role as the InnoDB redo log files.
The write-ahead log file can be found in the rocksdb data directory (default: /var/lib/mysql/.rocksdb) with the file extension of ‘.log’.
Regardless of whether or not your writes are going to one column family or several, all writes will go to the same write-ahead log. In the case that the memtable is flushed to disk, a new write-ahead log will be created at that time. However, you can also limit the size of write-ahead log files on disk by using this variable. Keep in mind that if you limit the size of disk consumption that can be used by write-ahead log files, once that limit is hit it will force a memtable flush. For example, if you have this variable set to 10Mb, once the 10Mb limit is reached it will force all memtables to flush to disk so that a new write-ahead log file can be created.
Default: 0
The default value indicates that the write-ahead log size should be chosen dynamically by MyRocks. Based on my testing it appears that this will effectively place very little limit on the log files. Generally speaking, you can expect that the amount of space consumed on disk would be the maximum amount of space of all of your column family’s active memtables, or rocksdb_db_write_buffer_size, whichever is smaller.
For example, if you have no limit on rocksdb_db_write_buffer_size and you have 3 column families at their default setting of 64Mb, you can expect that you’ll have at least 192Mb of write-ahead logs on disk.
Based on my testing, my recommendation would be to leave this variable at the default, mainly because you will want to keep disk flushes to a minimum and setting a hard limit for write-ahead logging may result in more flushing than if it were left to its original value. However, I think a good exception would be if you plan to use a lot of column families and if you want to make sure the space consumed by write-ahead logs doesn’t get out of control.
Rocksdb_wal_dir
You have the option of storing the write-ahead log files within the data directory for MyRocks, or you if you like you can specify a different directory using the system variable rocksdb_wal_dir.
Default: NULL (place in data directory)
It’s been common in the past for database admins to separate random I/O and sequential I/O patterns by placing them on different storage devices or platforms. This is becoming less common as SSDs and similar technologies are becoming the database storage of choice, but if you’re still using spinning media, you may want to consider putting your write-ahead logs on a disk that is dedicated for the sequential I/O pattern typically found with log writing.
Rocksdb_flush_log_at_trx_commit
When a transaction is committed, you would want to sync it to the write-ahead log before returning a commit confirmation to the client in order to ensure that the transaction is ACID-compliant. If this did not occur, you wouldn’t have the assurance that the transaction that was recently committed would actually be able to be recovered from the write-ahead log in the case of a crash.
The variable rocksdb_flush_log_at_trx_commit controls this activity, allowing you to relax the requirements to sync transaction data to the log as part of the commit process and increase performance at the cost of ACID compliance. For those of you who are familiar with InnoDB, this variable is similar to innodb_flush_log_at_trx_commit.
Per the documentation, the following options are available to you with this variable.
1 – Write data to the write-ahead log and sync the data to disk as part of the transaction commit process.
2 – Write the data to the write-ahead log at commit and sync to disk once per second.
0 – Write the data to the write-ahead log at commit but do not sync to disk.
The interesting part about value 0 is that it doesn’t specify under what specific conditions the write-ahead log would be synced to disk. Upon further testing, I found that options 0 and 2 behaved identically and have opened a bug with Percona to address this problem.
Default: 1
I would recommend leaving this at its default value unless you can live with the risk of potentially losing data in the case of a crash.
Rocksdb_write_disable_wal
There are times when you may want to disable write-ahead logging. This can increase write performance overall as transactions don’t have to wait for confirmation that log data has been written prior to commit, which is good for bulk loading your database, or even restoring from a logical backup. The fact that this can be configured dynamically for an individual MySQL session also makes this variable worth considering. However, you have to be careful as data written into a memtable is not guaranteed to be flushed to disk until it has become immutable and subsequently flushed. Until that point, any data written to the memtable with this option enabled would be lost in a crash.
Default: OFF
I think it’s pretty clear that leaving this at the default of ‘OFF’ is best. If you were to disable write-ahead logging, you would want to do so dynamically, and only within a specific MySQL session.
Rocksdb_wal_ttl_seconds
Once a new write-ahead log file is created under one of the previously noted conditions, old versions of the write-ahead log file should be kept in the archive directory of the MyRocks data directory. For example, with my default configuration values this directory is located in /var/lib/mysql/.rocksdb/archive.
Per the documentation, this variable is supposed to control how long archived files should be kept. With a value of ‘0’ it should not delete any archived files. However, in my testing, I discovered that the behavior of write-ahead log archiving was different than what the documentation describes. Instead, if you have a value of 0, there is no write-ahead log archiving at all. Write-ahead log archiving only happened in my lab once this variable was set to a non-zero value. I have created a bug with Percona to address this.
Default: 0
Given that write-ahead logs are there to serve a purpose of ensuring data durability in a crash, I don’t think it’s very beneficial to hold onto old write-ahead log files. As such, I would be inclined to leave this at zero, or perhaps keep this at a very low value in order to ensure that you aren’t consuming a lot of disk space for old write-ahead logs.
Rocksdb_wal_recovery_mode
The whole point of the write-ahead log is to be able to recover from a crash with committed data still intact. This is the ‘durable’ component of ACID compliance. However, MySQL could crash in the middle of an entry addition, or other corruption could occur. This variable allows you to configure how MyRocks should handle that type of an issue during crash recovery.
Permitted values are as follows.
0 – If a corrupted WAL entry is detected as the last entry in the WAL, truncate the entry and start up normally; otherwise, refuse to start.
1 – If a corrupted WAL entry is detected, fail to start. This is the most conservative recovery mode.
2 – If a corrupted WAL entry is detected in the middle of the WAL, truncate all of WAL entries after that (even though there may be uncorrupted entries) and then start up normally. For replication slaves, this option is fine, since the slave instance can recover any lost data from the master without breaking consistency. For replication masters, this option may end up losing data if you do not run failover. For example, if the master crashed and was restarted (by mysqld_safe, or auto restart after OS reboot) with this mode and it silently truncated several WAL entries, the master would lose some data which may be present on one or more slaves.
3 – If a corrupted WAL entry is detected in the middle of the WAL, skip the WAL entry and continue to apply as many healthy WAL entries as possible. This is the most dangerous recovery option and it is not generally recommended.
Default: 1
I believe that the most conservative crash recovery method should be used until you are forced to select another option. In the case that you attempt to start MySQL and MyRocks provides an error in regard to log corruption, use the data that you’ve collected from the error log and select the next least conservative value.
In my opinion, if Option 3 ever need to be used, you should start the system, do a logical dump of the database using something like mysqldump, stop MySQL, clear out your data directory, and reload from the dump that you created.
Associated Metrics
Here are some of the metrics you should pay attention to when it comes to initial data writing.
You can find the following information using system status variables
-
-
Rocksdb_rows_deleted: The number of rows that have been deleted from tables using the MyRocks storage engine since the last MySQL restart.
-
Rocksdb_rows_inserted: The number of rows that have been inserted into tables using the MyRocks storage engine since the last MySQL restart.
-
Rocksdb_rows_updated: The number of rows that have been updated in tables using the MyRocks storage engine since the last MySQL restart.
-
Rocksdb_bytes_written: The number of bytes written into MyRocks tables including updates and deletes since the last MySQL restart.
-
Rocksdb_memtable_total: The total amount of memory currently being consumed by memtables in bytes.
-
Rocksdb_stall_memtable_limit_slowdowns: The number of slowdowns that have occurred due to MyRocks getting close to the maximum number of allowed memtables since the last MySQL restart.
- Rocksdb_stall_memtable_limit_stops: The number of write stalls that have occurred due to MyRocks hitting the maximum number of allowed memtables since the last MySQL restart.
-
Rocksdb_stall_total_slowdowns: The total number of write slowdowns that have occurred in the MyRocks engine since the last MySQL restart.
-
Rocksdb_stall_total_stops: The total number of write stalls that have occurred in the MyRocks engine since the last MySQL restart.
-
Rocksdb_wal_bytes: The number of bytes written to the write-ahead log since the last MySQL restart.
- Rocksdb_wal_synced: The number of times that a write-ahead log has been synced to disk since the last MySQL restart.
In the information_schema.ROCKSDB_CFSTATS table you can find the following information about each column family.
-
CUR_SIZE_ALL_MEM_TABLES: The current size of all memtables, including active and immutable, per column family.
-
CUR_SIZE_ACTIVE_MEM_TABLE: The current size of all active memtables per column family.
-
NUM_ENTRIES_ACTIVE_MEM_TABLE: The number of record changes in the active memtable per column family.
-
NUM_ENTRIES_IMM_MEM_TABLES: The number of record changes in the immutable memtable(s) per column family.
-
NUM_IMMUTABLE_MEM_TABLE: The current number of immutable memtables for each column family.
Conclusion
In this post, we explained column families, the differences between server variables and column family options, how data gets written into memory space, the associated logging, and different conditions that designate when that data will be flushed to disk.
Stay tuned for the next post where we will discuss the mechanics surrounding the flush from immutable memtable to disk.
A big thank you goes out to my internal fact checker, Sandeep Varupula, as well as George Lorch of Percona for acting as an additional external technical reviewer!













 We’re pleased to share the replay of our webinar “
We’re pleased to share the replay of our webinar “









 Who’d benefit most from the presentation?
Who’d benefit most from the presentation?