![Percona XtraDB Cluster on Raspberry PI 3]()
![Percona XtraDB Cluster on Raspberry PI 3]() In a previous post, I showed you how to compile Percona Mysql 5.7 on Raspberry PI 3. Now, I’ll show you how to compile and run the latest version of Percona XtraDB Cluster 5.7.26.
In a previous post, I showed you how to compile Percona Mysql 5.7 on Raspberry PI 3. Now, I’ll show you how to compile and run the latest version of Percona XtraDB Cluster 5.7.26.
We will need at least 3 RaspberryPi 3 boards, and I recommend you use an external SSD drive to compile and use as MySQL’s “datadir” to avoid the stalls associated with the microSD card, which will cause PXC to run slow.
In this post, we are going to run many OS commands and configure PXC. I recommend having minimal knowledge about PXC and Linux commands.
How to install CentOS
Download the centos image from this link http://mirror.ufro.cl/centos-altarch/7.6.1810/isos/armhfp/CentOS-Userland-7-armv7hl-RaspberryPI-Minimal-1810-sda.raw.xz
I’m using this open source software https://www.balena.io/etcher/ to flash/burn the microSD card because it is very simple and works fine. I recommend using a 16GB card or larger.
If the previous process finished ok, take out the microSD card and put it into the raspberry and boot it. Wait until the boot process finishes and log in with this user and password
user: root
password: centos
By default, the root partition is very small and you need to expand it. Run the next command, this process is fast.
/usr/bin/rootfs-expand
Finally, to finish the installation process it is necessary to install many packages to compile PXC and percona-xtrabackup,
yum install -y cmake wget automake bzr gcc make telnet gcc-c++ vim libcurl-devel readline-devel ncurses-devel screen zlib-devel bison locate libaio libaio-devel autoconf socat libtool libgcrypt-devel libev-devel vim-common check-devel openssl-devel boost-devel glib2-devel
Repeat all the previous steps over all those 3 dbnodes because some libs are needed to start mysql and to work with percona-xtrabackup.
How to compile PXC + Galera + Xtrabackup
I am using an external SSD disk because it’s faster than the microSD which I mounted on /mnt directory, so we will use this partition to download, compile, and create the datadir.
For the latest PXC version, download and decompress it using the following commands:
cd /mnt
wget https://www.percona.com/downloads/Percona-XtraDB-Cluster-57/Percona-XtraDB-Cluster-5.7.26-31.37/source/tarball/Percona-XtraDB-Cluster-5.7.26-31.37.tar.gz
tar zxf Percona-XtraDB-Cluster-5.7.26-31.37.tar.gz
cd Percona-XtraDB-Cluster-5.7.26-31.37
RaspberryPi3’s are not x86_64 architecture; it uses an ARMv7 which forces us to compile PXC from scratch. For me, this process took 6-ish hours. I recommend running the next commands in a screen session.
screen -SDRL compile_pxc
cmake -DINSTALL_LAYOUT=STANDALONE -DCMAKE_INSTALL_PREFIX=/mnt/pxc5726 -DDOWNLOAD_BOOST=ON -DWITH_BOOST=/mnt/sda1/my_boost -DWITH_WSREP=1 .
make
make install
Create a new OS user to be used by the mysql process.
useradd --no-create-home mysql
Now to continue it is necessary to create the datadir directory. I recommend to use the SSD disk attached and set the mysql permissions to the directory:
mkdir /mnt/pxc5726/data/
chown mysql.mysql /mnt/pxc5726/data/
Configure my.cnf with the minimal params to start mysql.
vim /etc/my.cnf
[client]
socket=/mnt/pxc5726/data/mysql.sock
[mysqld]
datadir = /mnt/pxc5726/data
binlog-format = row
log_bin = /mnt/pxc5726/data/binlog
innodb_buffer_pool_size = 128M
socket=/mnt/pxc5726/data/mysql.sock
symbolic-links=0
wsrep_provider=/mnt/pxc5726/libgalera_smm.so
wsrep_on=ON
wsrep_cluster_name="pxc-cluster"
wsrep_cluster_address="gcomm://192.168.88.134"
wsrep_node_name="pxc1"
wsrep_node_address=192.168.88.134
wsrep_debug=1
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth=sstuser:passw0rd
pxc_strict_mode=ENFORCING
[mysqld_safe]
log-error=/mnt/pxc5726/data/mysqld.log
pid-file=/mnt/pxc5726/data/mysqld.pid
So far we’ve only compiled PXC. Before we can start the mysql process, we also need to compile the Galera library, as, without this library, mysql will start as a standalone db-node and will not have any “cluster” capabilities.
To build libgalera_smm.so you need to install scons.
Download using the next command:
cd /mnt
wget http://prdownloads.sourceforge.net/scons/scons-3.1.0.tar.gz
tar zxf scons-3.1.0.tar.gz
cd scons-3.1.0
python setup.py install
Now we will proceed to compile libgalera. The source code for this library exists in the Percona-XtraDB-Cluster-57 directory download:
cd /mnt/Percona-XtraDB-Cluster-5.7.26-31.37/percona-xtradb-cluster-galera
scons -j4 libgalera_smm.so debug=3 psi=1 BOOSTINCLUDE=/mnt/my_boost/boost_1_59_0/boost BOOST_LIBS=/mnt/my_boost/boost_1_59_0/libs
If the compile process finishes ok, it will create a new file like this:
/mnt/Percona-XtraDB-Cluster-5.7.26-31.37/percona-xtradb-cluster-galera/libgalera_smm.so
I recommend copying libgalera_smm.so to the installed PXC directory to avoid deleting, in that case, remove the source directory.
cp /mnt/Percona-XtraDB-Cluster-5.7.26-31.37/percona-xtradb-cluster-galera/libgalera_smm.so /mnt/pxc5726
Also, this is useful because after installing and compiling all the packages we can create a compressed file and copy to the rest of the db-nodes to avoid having to compile these packages again.
The last step is to download and compile percona-xtrabackup. I used the latest version:
screen -SDRL compile_xtrabackup
cd /mnt
wget https://www.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.15/source/tarball/percona-xtrabackup-2.4.15.tar.gz
tar zxf percona-xtrabackup-2.4.15.tar.gz
cd percona-xtrabackup-2.4.15
cmake -DBUILD_CONFIG=xtrabackup_release -DWITH_MAN_PAGES=OFF -DCMAKE_INSTALL_PREFIX=/mnt/xtrabackup .
make
make install
If all the previous steps were successful, we will add those binary directories in the PATH variable:
vim /etc/profile.d/percona.sh
export PATH=$PATH:/mnt/xtrabackup/bin:/mnt/pxc5726/bin
Save and exit and run the “export” command manually to set it in the active session:
export PATH=$PATH:/mnt/xtrabackup/bin:/mnt/pxc5726/bin
Well, so far we have PXC, Galera-lib, and percona-xtrabackup compiled for the ARMv7 architecture, which is all that is needed to work with PXC, so now we can start playing.
We will call the first host where we compiled “pxc1”. We will proceed to set the hostname:
$ vim /etc/hostname
pxc1
$ hostname pxc1
$ exit
It is necessary to connect again to ssh to refresh the hostname and you will see something like this:
$ ssh ip
[root@pxc1 ~]#
Now we are ready to open the ports needed by PXC; xtrabackup, galera, and mysql.
$ firewall-cmd --permanent --add-port=3306/tcp
$ firewall-cmd --permanent --add-port=4567/tcp
$ firewall-cmd --permanent --add-port=4444/tcp
$ firewall-cmd --reload
$ firewall-cmd --list-ports
22/tcp 3306/tcp 4567/tcp 4444/tcp
Repeat the above procedures to set the hostname and open ports in the other db nodes.
Finally, to start the first node you’ll need to initialize the system databases and then launch the mysql process with the –wsrep-new-cluster option. This will bootstrap the cluster so that it starts with 1 node. Run the following from the command-line:
$ mysqld --initialize-insecure --user=mysql --basedir=/mnt/pxc5726 --datadir=/mnt/pxc5726/data
$ mysqld_safe --defaults-file=/etc/my.cnf --user=mysql --wsrep-new-cluster &
Check the mysql error log to see any errors:
$ tailf /mnt/pxc5726/data/mysqld.log
...
2019-09-08T23:23:17.415991Z 0 [Note] /mnt/pxc5726/bin/mysqld: ready for connections.
...
Create the new mysql user, and this will be used for xtrabackup to sync another db node on IST or SST process.
$ mysql
CREATE USER 'sstuser'@'localhost' IDENTIFIED BY 'passw0rd';
GRANT PROCESS, RELOAD, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'sstuser'@'localhost';
FLUSH PRIVILEGES;
Lastly, I recommend checking if the galera library was loaded successfully:
$ mysql
show global status where Variable_name='wsrep_provider_name'
or Variable_name='wsrep_provider_name'
or Variable_name='wsrep_provider_vendor'
or Variable_name='wsrep_local_state'
or Variable_name='wsrep_local_state_comment'
or Variable_name='wsrep_cluster_size'
or Variable_name='wsrep_cluster_status'
or Variable_name='wsrep_connected'
or Variable_name='wsrep_ready'
or Variable_name='wsrep_evs_state'
or Variable_name like 'wsrep_flow_control%';
You will see something like this:
+----------------------------------+-----------------------------------+
| Variable_name | Value |
+----------------------------------+-----------------------------------+
| wsrep_flow_control_paused_ns | 0 |
| wsrep_flow_control_paused | 0.000000 |
| wsrep_flow_control_sent | 0 |
| wsrep_flow_control_recv | 0 |
| wsrep_flow_control_interval | [ 100, 100 ] |
| wsrep_flow_control_interval_low | 100 |
| wsrep_flow_control_interval_high | 100 |
| wsrep_flow_control_status | OFF |
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
| wsrep_evs_state | OPERATIONAL |
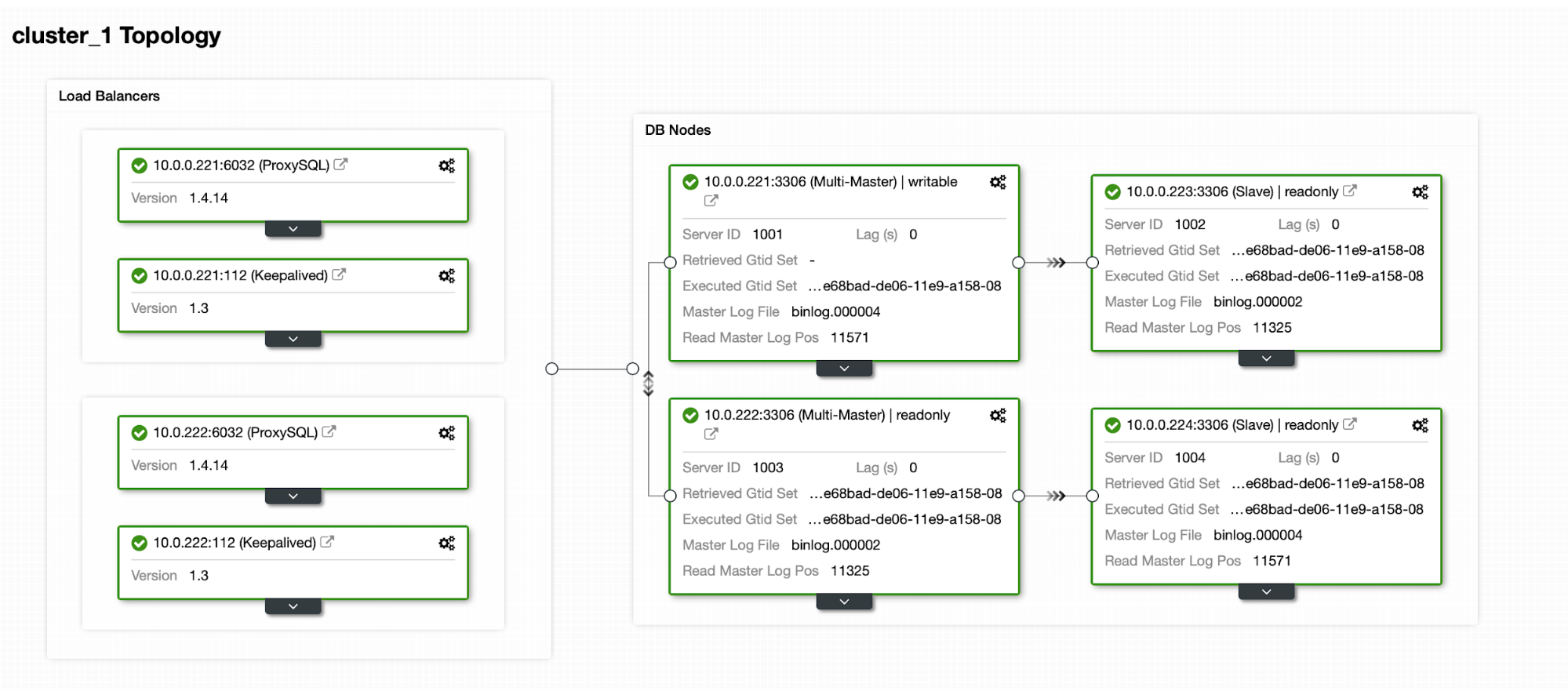
| wsrep_cluster_size | 1 | <----
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy <info@codership.com> |
| wsrep_ready | ON |
+----------------------------------+-----------------------------------+
As you can see this is the first node and the cluster size is 1.
How to copy the previous compiled source code to the rest of the db nodes
You don’t need to compile again over all the rest of the db nodes, just compress PXC and Xtrabackup directories and copy to the rest of the db nodes, nothing else.
In the first step, we compiled and installed on the next directories:
/mnt/pxc5726
/mnt/xtrabackup
We’re going to proceed to compress both directories and copy to the other servers (pxc2 and pxc3)
$ cd /mnt
$ tar czf pxc5726.tgz pxc5726
$ tar czf xtrabackup.tgz xtrabackup
Let’s copy to each db node:
$ cd /mnt
$ scp pxc5726.tgz xtrabackup.tgz IP_PXC2:/mnt
Now connect to each db node and start decompressing, configure my.cnf, other stuff, and start mysql.
$ ssh IP_PXC2
$ cd /mnt
$ tar zxf pxc5726.tgz
$ tar zxf xtrabackup.tgz
From here we are going to repeat several steps that we did previously.
Connect to IP_PXC2.
$ ssh IP_PXC2
Add the next directories in the PATH variable:
vim /etc/profile.d/percona.sh
export PATH=$PATH:/mnt/xtrabackup/bin:/mnt/pxc5726/bin
Save and exit and run the “export” command manually to set it in the active session:
export PATH=$PATH:/mnt/xtrabackup/bin:/mnt/pxc5726/bin
Create a new OS user to be used by mysql process:
useradd --no-create-home mysql
Now to continue it’s necessary to create the datadir directory. I recommend using the SSD disk attached and set the mysql permissions to the directory.
mkdir /mnt/pxc5726/data/
chown mysql.mysql /mnt/pxc5726/data/
Configure my.cnf with the minimal params to start mysql.
vim /etc/my.cnf
[client]
socket=/mnt/pxc5726/data/mysql.sock
[mysqld]
datadir = /mnt/pxc5726/data
binlog-format = row
log_bin = /mnt/pxc5726/data/binlog
innodb_buffer_pool_size = 128M
socket=/mnt/pxc5726/data/mysql.sock
symbolic-links=0
wsrep_provider=/mnt/pxc5726/libgalera_smm.so
wsrep_on=ON
wsrep_cluster_name="pxc-cluster"
wsrep_cluster_address="gcomm://IP_PXC1,IP_PXC2"
wsrep_node_name="pxc2"
wsrep_node_address=IP_PXC2
wsrep_debug=1
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth=sstuser:passw0rd
pxc_strict_mode=ENFORCING
[mysqld_safe]
log-error=/mnt/pxc5726/data/mysqld.log
pid-file=/mnt/pxc5726/data/mysqld.pid
Now we need to start the second db node. This time you don’t need to add “–wsrep-new-cluster” param (from the second and next nodes it’s not needed), just start mysql and run the next command:
$ mysqld_safe --defaults-file=/etc/my.cnf --user=mysql &
Check the mysql error log to see any error:
$ tailf /mnt/pxc5726/data/mysqld.log
...
2019-09-08T23:53:17.415991Z 0 [Note] /mnt/pxc5726/bin/mysqld: ready for connections.
...
Check if the galera library was loaded successfully:
$ mysql
show global status where Variable_name='wsrep_provider_name'
or Variable_name='wsrep_provider_name'
or Variable_name='wsrep_provider_vendor'
or Variable_name='wsrep_local_state'
or Variable_name='wsrep_local_state_comment'
or Variable_name='wsrep_cluster_size'
or Variable_name='wsrep_cluster_status'
or Variable_name='wsrep_connected'
or Variable_name='wsrep_ready'
or Variable_name='wsrep_evs_state'
or Variable_name like 'wsrep_flow_control%';
You will see something like this:
+----------------------------------+-----------------------------------+
| Variable_name | Value |
+----------------------------------+-----------------------------------+
| wsrep_flow_control_paused_ns | 0 |
| wsrep_flow_control_paused | 0.000000 |
| wsrep_flow_control_sent | 0 |
| wsrep_flow_control_recv | 0 |
| wsrep_flow_control_interval | [ 100, 100 ] |
| wsrep_flow_control_interval_low | 100 |
| wsrep_flow_control_interval_high | 100 |
| wsrep_flow_control_status | OFF |
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
| wsrep_evs_state | OPERATIONAL |
| wsrep_cluster_size | 2 | <---
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy <info@codership.com> |
| wsrep_ready | ON |
+----------------------------------+-----------------------------------+
Excellent, we have the second node up, now is it’s part of the cluster and the cluster size is 2.
Repeat the previous steps to configure IP_PXC3 and nexts.
Summary
We are ready to start playing and doing a lot of tests. I recommend running sysbench to test how many transactions this environment supports, kill some nodes to test SST and IST, and I recommend using pt-online-schema-change and check this blog “How to Perform Compatible Schema Changes in Percona XtraDB Cluster” to learn how this tool works in PXC.
I hope you enjoyed this guide, and if you want to compile other PXC 5.7.X versions, please go ahead, the steps will be very similar.




 My first talk is a tutorial Testing like a boss: Deploy and Test Complex Topologies With a Single Command, scheduled at
My first talk is a tutorial Testing like a boss: Deploy and Test Complex Topologies With a Single Command, scheduled at 





 In a previous post, I showed you
In a previous post, I showed you 














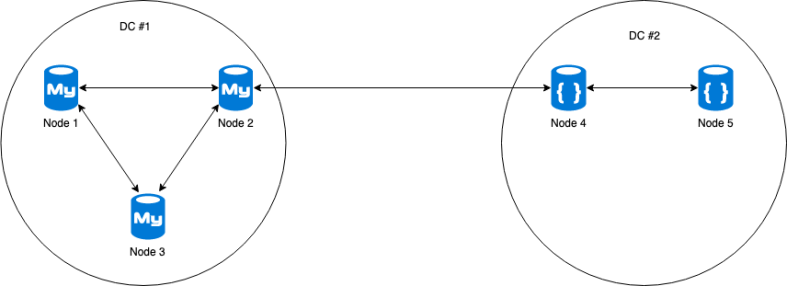
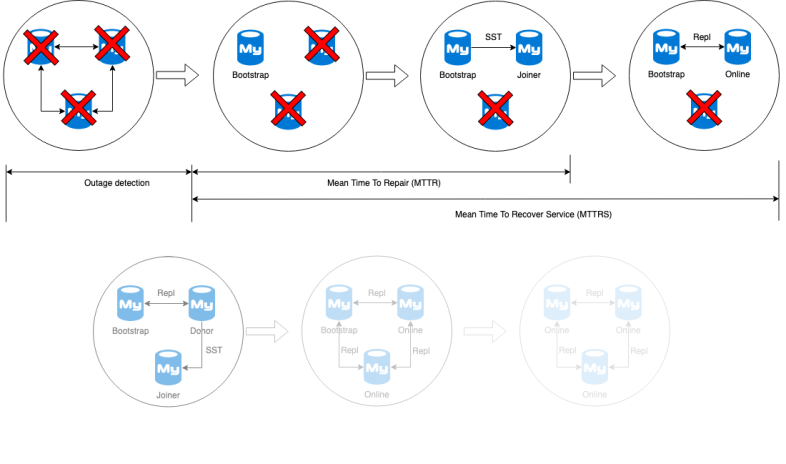
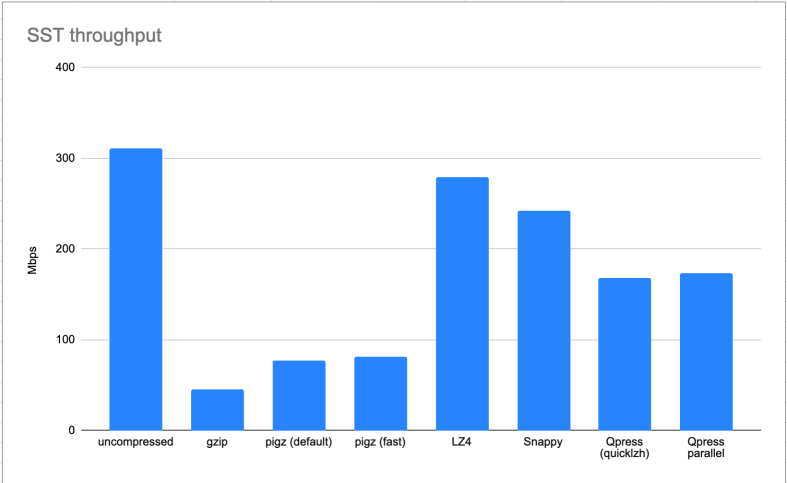


 Multiplexing Background
Multiplexing Background