Please join Autodesk’s Senior Database Engineer, Vineet Khanna, and Percona’s Sr. MySQL DBA, Tate McDaniel as they present Migrating to Aurora and Monitoring with PMM on Thursday, August 9th, 2018, at 10:00 AM PDT (UTC-7) / 1:00 PM EDT (UTC-4).
Amazon Web Services (AWS) Aurora is one of the most popular cloud-based RDBMS solutions. The main reason for Aurora’s success is because it’s based on InnoDB storage engine.
In this session, we will talk about how you can efficiently plan for migration to Aurora using Terraform and Percona products and solutions. We will share our Terraform code for launching AWS Aurora clusters, look at tricks for checking data consistency, verify migration paths and effectively monitor the environment using PMM.
The topics in this session include:
Why AWS Aurora? What is the future of AWS Aurora?
Build Aurora Infrastructure
Using Terraform (Without Data)
Restore Using Terraform & Percona XtraBackup (Using AWS S3 Bucket)
Verify data consistency
Aurora migration
1:1 migration
Many:1 migration using Percona Server multi-source replication
Vineet Khanna, Senior Database Engineer at Autodesk, has 10+ years of experience as a MySQL DBA. His main professional interests are managing complex database environments, improving database performance, architecting High Availability solutions for MySQL. He has handled database environments of organizations like Chegg, Zendesk, Adobe.
Tate Mcdaniel, Sr. MySQL DBA
Tate joined Percona in June 2017 as a Remote MySQL DBA. He holds a Bachelors degree in Information Systems and Decision Strategies from LSU. He has 10+ years of experience working with MySQL and operations management. His great love is application query tuning. In his off time, he races sailboats, travels the Caribbean by sailboat, and
drives all over in an RV.
Recently, I wrote a blog post showing how to enforce SELinux with Percona XtraDB Cluster (PXC). The Linux distributions derived from RedHat use SELinux. There is another major mandatory discretionary access control (DAC) system, AppArmor. Ubuntu, for example, installs AppArmor by default. If you are concerned by computer security and use PXC on Ubuntu, you should enforce AppArmor. This post will guide you through the steps of creating a profile for PXC and enabling it. If you don’t want to waste time, you can just grab my profile, it seems to work fine. Adapt it to your environment if you are using non-standard paths. Look at the section “Copy the profile” for how to install it. For the brave, let’s go!
Install the tools
In order to do anything with AppArmor, we need to install the tools. On Ubuntu 18.04, I did:
apt install apparmor-utils
The apparmor-utils package provides the tools we need to generate a skeleton profile and parse the system logs.
Create a skeleton profile
AppArmor is fairly different from SELinux. Instead of attaching security tags to resources, you specify what a given binary can access, and how, in a text file. Also, processes can inherit permissions from their parent. We will only create a profile for the mysqld_safe script and it will cover the mysqld process and the SST scripts as they are executed under it. You create the skeleton profile like this:
root@BlogApparmor2:~# aa-autodep /usr/bin/mysqld_safe
Writing updated profile for /usr/bin/mysqld_safe.
On Ubuntu 18.04, there seems to be a bug. I reported it and apparently I am not the only one with the issue. If you get a “KeyError” error with the above command, try:
script does not behave well, security wise. The Percona developers have released a fixed version but it may not be available yet in a packaged form. In the meantime, you can download it from github.
Start iterating
My initial thought was to put the profile in complain mode, generate activity and parse the logs with aa-logprof to get entries to add to the profile. Likely there is something I am doing wrong but in complain mode, aa-logprof detects nothing. In order to get something I had to enforce the profile with:
See the next section for how to run aa-logprof. Once that sequence worked well, I tried SST (joiner/donor) roles and IST.
Parse the logs with aa-logprof
Now, the interesting part begins, parsing the logs. Simply begin the process with:
root@BlogApparmor2:~# aa-logprof
and answer the questions. Be careful, I made many mistakes before I got it right, remember I am more a DBA than a Sysadmin. For example, you’ll get questions like:
AppArmor asks you how it should provide read access to the
/etc/hosts.allow
file. If you answer right away with “A”, it will add
#include <abstractions/lxc/container-base>
to the profile. With all the dependencies pulled by the lxc-related includes, you basically end up allowing nearly everything. You must first press “3” to get:
For such a question, my answer is “I” for inherit. After a while, you’ll get through all the questions and you’ll be asked to save the profile:
The following local profiles were changed. Would you like to save them?
[1 - /usr/bin/mysqld_safe]
(S)ave Changes / Save Selec(t)ed Profile / [(V)iew Changes] / View Changes b/w (C)lean profiles / Abo(r)t
Writing updated profile for /usr/bin/mysqld_safe.
Revise the profile
Do not hesitate to edit the profile if you see, for example, many similar file entries which could be replaced by a “*” or “**”. If you manually modify the profile, you need to parse it to load your changes:
You can always verify if the profile is enforced with:
root@BlogApparmor3:/etc/apparmor.d# aa-status
apparmor module is loaded.
42 profiles are loaded.
20 profiles are in enforce mode.
/sbin/dhclient
...
/usr/bin/mysqld_safe
...
man_groff
Once enforced, I strongly advise to monitor the log files on a regular basis to see if anything has been overlooked. Similarly if you encounter a strange and unexpected behavior with PXC. Have the habit of checking the logs, it might save a lot of frustrating work.
Conclusion
As we have just seen, enabling AppArmor with PXC is not a difficult task, it just requires some patience. AppArmor is an essential component of a layered security approach. It achieves similar goals as the other well known DAC framework, SELinux. With the rising security concerns and the storage of sensitive data in databases, there are compelling reasons to enforce a DAC framework. I hope these two posts will help DBAs and Sysadmins to configure and enable DAC for PXC.
Watch the relay of this webinar and learn how Bluefin Payment Systems provides 24/7/365 operation and application availability for their PayConex payment gateway and Decryptx decryption-as-a-service, essential to point-of-sale (POS) solutions in retail, mobile, call centers and kiosks.
We discuss why Bluefin uses Continuent Clustering, and how Bluefin runs two co-located data centers with multimaster replication between each cluster in each data center, with full failover within the cluster and between clusters, handling 350 million records each month.
MySQL has since version 5.7 had support for progress information for some queries. As promised in my previous post, I will here discuss how you can use that to get progress information for ALTER TABLE on InnoDB tables.
Background and Setup
Progress information is implemented through the Performance Schema using the stage events. In version 8.0.12 there are currently seven stages that can provide this information for ALTER TABLE statements on InnoDB tables. In MySQL 8, it is easy to list the stages capable of reporting progress information by using the setup_instruments Performance Schema table:
This also shows how the setup_instruments table in MySQL 8 has some additional information about the instruments such as properties and documentation (not included in the output). Adding this information is still work in progress.
MySQL 5.7 does not provide as easy a way to obtain the instruments providing progress information. Instead you need to consult the reference manual. However, the principle in using the feature is the same.
As you can see, all of the instruments are enabled and timed by default. What is not enabled by default, however, is the consumer that can make the information available:
mysql> SELECT NAME, ENABLED,
sys.ps_is_consumer_enabled(NAME) AS EnabledWithHierarchy
FROM performance_schema.setup_consumers
WHERE NAME = 'events_stages_current';
+-----------------------+---------+----------------------+
| NAME | ENABLED | EnabledWithHierarchy |
+-----------------------+---------+----------------------+
| events_stages_current | NO | NO |
+-----------------------+---------+----------------------+
1 row in set (0.01 sec)
Since the consumers form a hierarchical system, the sys schema function ps_is_consumer_enabled() is used to show whether the consumer is enabled taking the whole hierarchy into consideration.
In order to use the progress information, you need to enable the events_stages_current consumer. This is the consumer that is responsible for keeping the performance_schema.events_stages_current table up to date, i.e. record the current (or latest if there is no current stage) for each thread. With the default Performance Schema settings, the rest of the hierarchy is enabled. To enable event_stages_current and verify it will be consuming instruments, you can use the following queries:
mysql> UPDATE performance_schema.setup_consumers
SET ENABLED = 'YES'
WHERE NAME = 'events_stages_current';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT NAME, ENABLED,
sys.ps_is_consumer_enabled(NAME) AS EnabledWithHierarchy
FROM performance_schema.setup_consumers
WHERE NAME = 'events_stages_current';
+-----------------------+---------+----------------------+
| NAME | ENABLED | EnabledWithHierarchy |
+-----------------------+---------+----------------------+
| events_stages_current | YES | YES |
+-----------------------+---------+----------------------+
1 row in set (0.00 sec)
That is it. Now you can monitor the progress of the queries that uses the stages with progress information.
Note: The more parts of the Performance Schema that is enabled and the more fine grained monitoring, the more overhead. Stages are not the worst with respect to overhead; nevertheless it is recommended you keep an eye on the affect of enabling the events_stages_current consumer.
Monitoring Progress
The base for monitoring the progress information is the performance_schema.events_stages_current table. There are two columns of interest for this discussion:
WORK_COMPLETED: The amount of work that is reported to have been completed.
WORK_ESTIMATED: The estimated amount of work that needs to be done.
For InnoDB ALTER TABLE the estimated amount of work is for the entire operation. That said, the estimate may be revised during the process, so it may happen that the if you calculate the percentage it decreases as time goes. However, in general the percentage (100% * WORK_COMPLETED/WORK_ESTIMATED) will increase steadily until the operation completes at 100%.
To learn more about how the progress information works, the following pages in the manual are recommended:
For the example, the salaries table in the employees sample database will be used. The table is sufficiently large that it will be possible to query the progress while adding a column using the INPLACE algorithm. As discussed in MySQL 8.0.12: Instant ALTER TABLE, it is possible to add a column instantly, but for the purpose of this example, the INPLACE algorithm illustrates the progress information feature better. The query that will be executed is:
ALTER TABLE salaries ADD COLUMN new_col int NOT NULL DEFAULT 0, ALGORITHM=INPLACE;
The performance_schema.events_stages_current table can be joined with the performance_schema.events_statements_current to show the query and progress. For example:
mysql> SELECT stmt.THREAD_ID, stmt.SQL_TEXT, stage.EVENT_NAME AS State,
stage.WORK_COMPLETED, stage.WORK_ESTIMATED,
ROUND(100*stage.WORK_COMPLETED/stage.WORK_ESTIMATED, 2) AS CompletedPct
FROM performance_schema.events_statements_current stmt
INNER JOIN performance_schema.events_stages_current stage
ON stage.THREAD_ID = stmt.THREAD_ID
AND stage.NESTING_EVENT_ID = stmt.EVENT_ID\G
*************************** 1. row ***************************
THREAD_ID: 63857
SQL_TEXT: ALTER TABLE salaries ADD COLUMN new_col int NOT NULL DEFAULT 0, ALGORITHM=INPLACE
State: stage/innodb/alter table (read PK and internal sort)
WORK_COMPLETED: 8906
WORK_ESTIMATED: 27351
CompletedPct: 32.56
1 row in set (0.00 sec)
There is another way though. Instead of using the performance_schema.events_stages_current table directly, an easier way is to use the sys.session view. This is an advanced process list that includes much more information than the usual SHOW PROCESSLIST statement including progress information. The performance of sys.session has been improved with more than an order of magnitude in MySQL 8 by the addition of indexes to the Performance Schema tables making it highly useful.
Querying the sys.session view for sessions showing progress information while the ALTER TABLE is in progress returns an output similar to the following example:
mysql> SET @sys.statement_truncate_len = 85;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT thd_id, conn_id, db, command, state, current_statement,
statement_latency, progress, current_memory, program_name
FROM sys.session
WHERE progress IS NOT NULL\G
*************************** 1. row ***************************
thd_id: 63857
conn_id: 63818
db: employees
command: Query
state: alter table (merge sort)
current_statement: ALTER TABLE salaries ADD COLUMN new_col int NOT NULL DEFAULT 0, ALGORITHM=INPLACE
statement_latency: 4.22 s
progress: 49.39
current_memory: 464.27 KiB
program_name: MySQLWorkbench
1 row in set (0.06 sec)
In the example, the @sys.statement_truncate_len user variable is set to 85. By default the sys schema ensures the current statement is at most 64 characters long. In order to avoid truncation in this case, the truncate length is increased to 85.
The example output shows that the progress is at around 49%. It is important to note that is an estimate and not an exact number. The ALTER TABLE is performing a merge sort at the time, and the query has been running for 4.22 seconds.
A couple of other interesting columns are included. It can be seen the connection is using 464KiB at the time. In MySQL 8 memory instrumentation is enabled by default (in MySQL 5.7 you need to enable it yourself). Additionally, the name of the program executing the query is MySQLWorkbench, that is the query originates from MySQL Workbench.
So, next time you plan a large ALTER TABLE operation, consider enabling the events_stages_current consumer, so you can follow the progress.
Join Percona Chief Evangelist Colin Charles as he covers happenings, gives pointers and provides musings on the open source database community.
The call for submitting a talk to Percona Live Europe 2018 is closing today, and while there may be a short extension, have you already got your talk submitted? I suggest doing so ASAP!
I’m sure many of you have heard of cryptocurrencies, the blockchain, and so on. But how many of you realiize that Coinbase, an application that handles cryptocurrency trades, matching book orders, and more, is powered by MongoDB? With the hype and growth in interest in late 2017, Coinbase has had to scale. They gave an excellent talk at MongoDB World, titled MongoDB & Crypto Mania (the video is worth a watch), and they’ve also written a blog post, How we’re scaling our platform for spikes in customer demand. They even went driver hacking (the Ruby driver for MongoDB)!
PingCap and TiDB have been to many Percona Live events to present, and recently hired Morgan Tocker. Morgan has migrated his blog from MySQL to TiDB. Read more about his experience in, This blog, now Powered by WordPress + TiDB. Reminds me of the early days of Galera Cluster and showing how Drupal could be powered by it!
Releases
pgModeler – a PostgreSQL database modeler, which is easy to use, multi-platform thanks to being written in Qt, with dynamic code generation. What’s the open source MySQL or MongoDB equivalent?
Sys Schema MySQL 5.7+ – blogger from Wipro, focusing on an introduction to the sys schema on MySQL (note: still not available in the MariaDB Server fork).
Prometheus Graduates in the CNCF, so is considered a mature project. Criteria for graduation is such that “projects must demonstrate thriving adoption, a documented, structured governance process, and a strong commitment to community sustainability and inclusivity.” Percona benefits from Prometheus in Percona Monitoring & Management (PMM), so we should celebrate this milestone!
A while ago in this column, we linked to Shlomi Noach’s excellent post on MySQL High Availability at GitHub. We were also introduced to GitHub Load Balancer (GLB), which they ran on top of HAProxy. However back then, GLB wasn’t open; now you can get GLB Director: GLB: GitHub’s open source load balancer. The project describes GLB Director as: “… a Layer 4 load balancer which scales a single IP address across a large number of physical machines while attempting to minimise connection disruption during any change in servers. GLB Director does not replace services like haproxy and nginx, but rather is a layer in front of these services (or any TCP service) that allows them to scale across multiple physical machines without requiring each machine to have unique IP addresses.”
This year again, the MySQL Team is eager to participate in the Oracle Open World conference. This is a great opportunity for our engineers and the entire MySQL Team to highlight what we’ve done, and also what we are working on. Another reason to be excited this year is our new participation to Code One, the Oracle developer focused conference. Oracle Code One will include a full track dedicated to MySQL.
This is very good news for everybody attending, from DBAs to developers, as we will offer even more great content ! This year, in both events, we will highlight how NoSQL+SQL=MySQL.
Our MySQL Engineers will deliver fantastic sessions about the new NoSQL capabilities and also about many new features we have released during the year. Many of those features were included in MySQL 8.0 such as MySQL Document Store (NoSQL) and MySQL InnoDB Cluster ! We will also show what’s new for MySQL in the Oracle Cloud with analytics improvements, Store Procedures in different languages using GraalVM, and more !
In addition to our expert sessions, we will offer tutorials and Hands-on-Labs !
Many of the leading companies will be participating in our events to share how they use MySQL, their tips, techniques and their success story.
Here are few examples of what you will learn from these Web-leaders:
How to get consistency with MySQL in the Cloud by Facebook
How Twitter gave up their own fork to migrate back to our standard MySQL
How Booking.com is using MySQL
How GitHub is handling schema changes
How Slack is sharding MySQL using Vitess
How Square is using JSON and MySQL, and the lessons they learned
How Square scales MySQL
How Square-Enix from Japan deals with there scaling challenges and plan to migrate to 8.0
How Uber manages and changes its datastream
How Alibaba is using MySQL with Raft
… and much more !
Don’t miss these big events ! (registration is required for both conferences)
MySQL load balancers becomes a trend setters in Market for High availability and Scalability. They offer variety of solutions for database. What can be the best load balancer ? It varies from case to case. This presentation was made at Mydbops meetup on 04-08-2018 covers the basics of load balancers with their advantages/ disadvantages and use cases.
In my recent blog posts I presented lists of bugs, fixed and not yet fixed, as usual. Working on these lists side tracked me from the main topic of this summer - problems in Oracle's way of handling MySQL. Time to get back on track!
Among things Oracle could do better for MySQL I mentioned QA:
"Oracle's internal QA efforts still seem to be somewhat limited. We get regression bugs, ASAN failures, debug assertions, crashes, test failures etc in the official releases, and Oracle MySQL still relies a lot on QA by MySQL Community (while not highlighting this fact that much in public)."
I have to explain these in details, as it's common perception for years already that Oracle improved MySQL QA a lot and invests enormously in it, and famous MySQL experts were impressed even 5 years ago:
"Lets take a number we did get the QA team now has 400 person-years of experience on it. Lets say the QA team was 10 people before, and now it is tripled to 30 people. That means the average QA person has over 13 years experience in QA, which is about a year longer than my entire post-college IT career."
I was in the conference hall during that famous keynote, and QA related statements in it sounded mostly funny for me. Now, 5 years later, let me try to explain why just adding people and person-years of experience may not work that well. I'll try to present some examples and lists of bugs, as usual, to prove my points.
Emirates Air Line in London lets you see nice views of London, and it costed a lot, but hardly it's the most efficient public transport system between the North Greenwich Peninsula and Royal Victoria Dock one could imagine.
We still get all kinds of regression bugs reported by MySQL Community for every release, even MySQL 8.0.12. Here is the short list of random recent examples:
Bug #90209 - "Performance regression with > 15K tables in MySQL 8.0 (with general tablespaces)".
Bug #91878 - "Wrong results with optimizer_switch='derived_merge=OFF';".
Bug #91377 - "Can't Initialize MySQl if internal_tmp_disk_storage_engine is set to MYISAM".
Bug #90100 - "Year type column have index, query value more than 2156 , the result is wrong".
Bug #91927 - "8.0.12 no longer builds with Mac brew-installed ICU".
It means that Oracle's MySQL QA may NOT do enough/proper regression testing. We sometimes can not say this for sure, as Oracle hides some test cases. So, we, users of MySQL, just may not know what was the intention of some recent change (tests should show it even if the fine manual may not be clear enough - a topic for my next post).
We still get valid test failure bugs found by MySQL Community members. Some recent examples follows:
Bug #90633 - "innodb_fts.ngram_1 test fails (runs too long probably)".
Bug #90631 - "perfschema.statement_digest_query_sample test fails sporadically".
Bug #89431 - "innodb_undo.truncate_recover MTR test failing with a server error log warning". It's fixed, but only in MySQL 8.0.13.
Bug #91175 - "rpl_semi_sync_group_commit_deadlock.test is not simulating flush error ".
Bug #91022 - "audit_null.audit_plugin_bugs test always failing".
Bug #86110 - "A number of MTR test cases fail when run on a server with no PERFSCHEMA".
For me it means that Oracle's MySQL QA either do not care to run regression tests suite properly, in enough combination of platforms, options and build types, or they do not analyze the failures they get properly (and release when needed, not when all tests pass on all platforms). This is somewhat scary.
We still get crashing bugs in GA releases. It's hard to notice them as they are got hidden fast or as soon as they get public attention, but they do exist, and the last example, Bug #91928, is discussed here.
It seems some tools that helps to discover code problems may not be used properly/regularly in Oracle. I had a separate post "On Bugs Detected by ASan", where you can find some examples. Lucky we are that Percona engineers test ASan builds of MySQL 5.7 and 8.0 regularly, for years, and contribute back public bug reports.
Oracle's MySQL QA engineers do not write much about their work in public recently. I can find some posts here and there from 2013 and 2014, but very few in recent years. One may say that's because QA engineers are working hard and have no time for blogging (unlike lazy annoying individual like me), but that's not entirely true. There is at least one Oracle engineer who does a lot of QA and makes a lot of information about his work public - Shane Bester - who is brave enough and cares enough to report MySQL bugs in public. Ironically, I doubt he has any formal relation to any of QA teams in Oracle!
A lot of real MySQL QA is still done by MySQL Community, while these efforts are not that much acknowledged recently (you usually get your name mentioned in the official release notes if you submitted a patch, but the fact that you helped Oracle by finding a real bug their QA missed is NOT advertised any more since last Morgan's "Community Release Notes" published 2 years ago). Moreover, only MySQL Community tries to make QA job popular and educate users about proper tools and approaches (Percona and Roel Van de Paar personally are famous for this).
To summarize, for me it seems that real MySQL QA is largely still performed by MySQL Community and in public, while the impact of hidden and maybe huge Oracle's investments in QA is way less clear and visible. Oracle's MySQL QA investments look like those into the Emirates Air Line cable car in London to me - the result is nice to have, but it's the most expensive cable system ever built with a limited efficiency for community as a public transport.
The goal of this article is to evaluate and highlight the main similarities and differences between the MySQL Server Database and the MariaDB Server Database. We’ll look into performance aspects, security, main features, and list all aspects which need to be considered before choosing the right database for your requirements.
Who is using MySQL and MariaDB?
Both MySQL and MariaDB publish a respectful list of customers who are using their database as their core data infrastructure.
For MySQL, we can see names such as Facebook, Github, YouTube, Twitter, PayPal, Nokia, Spotify, Netflix and more.
For MariaDB, we can see names such as Redhat, DBS, Suse, Ubuntu, 1&1, Ingenico and more.
Comparing features – MySQL vs MariaDB
Many new and exciting features like Windows Functions, Roles or Common Table Expressions (CTE) are probably worth mentioning, but won’t be mentioned in this article. We’re all about comparing the two database engines, so, therefore, we’ll only discuss features which are available only in one of them, to allow you, our readers, to determine the engine that works better for you.
Let’s look into several features which are available only in one of the databases, exclusively:
JSON datatype – Starting version 5.7, MySQL supports a native JSON data type defined by RFC 7159 that enables efficient access to data in JSON (JavaScript Object Notation) documents.
MariaDB decided not to implement this enhancement as they claim it’s not part of the SQL standard. Instead, to support replication from MySQL, they only defined an alias for JSON, which is actually a LONGTEXT column. MariaDB claims there is no significant performance difference between the two, but no benchmarks were done recently to support that claim.
It’s worth noting that both MySQL and MariaDB offer different JSON related functions which allow easier access, parsing and retrieval of JSON data.
Default authentication – In MySQL 8.0, caching_sha2_password is the default authentication plugin rather than mysql_native_password. This enhancement should improve security by using the SHA-256 algorithm.
MySQL Shell – MySQL Shell is an advanced command-line client and code editor for MySQL. In addition to SQL, MySQL Shell also offers scripting capabilities for JavaScript and Python. You won’t be able to access MariaDB servers using mysqlsh, as MariaDB doesn’t support the MySQL X protocol.
Encryption – MySQL encrypts redo/undo logs (when configured to do so), while it doesn’t encrypt temporary tablespace or binary logs. MariaDB, on the other hand, supports binary log encryption and temporary table encryption.
Key Management – MariaDB offers an AWS key management plugin out of the box. MySQL also provides several plugins for key management, but they’re only available in the Enterprise edition.
Sys schema – MySQL 8.0 includes the sys schema, a set of objects that helps database administrators and software engineers interpret data collected by the Performance Schema. Sys schema objects can be used for optimization and diagnosis use cases. MariaDB doesn’t have this enhancement included.
Validate_password – The validate_password plugin’s goal is to test passwords and improve security. MySQL has this plugin enabled by default, while MariaDB doesn’t.
Super read-only – MySQL enhances the read_only capabilities by providing the super read-only mode. If the read_only system variable is enabled, the server permits client updates only from users who have the SUPER privilege. If the super_read_only system variable is also enabled, the server prohibits client updates even from users who have SUPER. See the description of the read_only.
Invisible Columns – This feature, which is available on MariaDB, while not on MySQL, allows creating columns which aren’t listed in the results of a SELECT * statement, nor do they need to be assigned a value in an INSERT statement when their name isn’t mentioned in the statement.
Threadpool – MariaDB supports connection thread pools, which are most effective in situations where queries are relatively short and the load is CPU bound (OLTP workloads). On MySQL’s community edition, the number of threads is static, which limits the flexibility in this situations. The enterprise plan of MySQL includes the threadpool capabilities.
Performance
Over the years, many performance benchmark tests were executed on both MySQL and MariaDB engines. We don’t believe there is one answer to the question “which is faster, MySQL or MariaDB”. It very much depends on the use case, the queries, the number of users and connections, and many other factors that are needed to be considered.
If you must though, these are the most recent benchmark tests we found which might provide some indication to which one performs better. Please note that each of these tests was executed on a specific pair of database+engine (for example, MySQL + InnoDB), so the only conclusion is relevant to that specific pair.
Both databases provide the ability to replicate data from one server to another. The main difference we saw here is that most MariaDB versions will allow you to replicate to them, from MySQL databases, which means you can easily migrate MySQL databases to MariaDB. The other way around isn’t that easy, as most MySQL versions won’t allow replication from MariaDB servers.
Also, it’s worth noting that MySQL GTID is different than MariaDB GTID, so once you replicate data from MySQL to MariaDB, the GTID data will be adjusted accordingly.
Few examples to the differences between the replication configurations:
The default binlog format in MySQL is row based. In MariaDB, the default binlog format is mixed.
Log_bin_compress – This feature determines whether or not the binary log can be compressed. This enhancement is unique to MariaDB and therefore isn’t supported by MySQL.
Incompatibilities between MySQL and MariaDB
MariaDB’s documentation lists hundreds of incompatibilities between MySQL and MariaDB databases, in different versions. The main conclusion from this documentation is that you can’t rely on an easy migration from one database type to another.
Most database administrators hoped that MariaDB will be kept as a branch of MySQL, so it will be very easy to migrate between the two. For the last few versions, that’s not the case anymore. For a long time now, MariaDB is actually a fork of MySQL, which means you need to put some thought when you migrate from one to another.
Storage engines
MariaDB supports more storage engines than MySQL. Said that, it’s not a matter of which database supports more storage engines, but rather which database supports the right storage engine for your requirements.
Supported storage engines on MySQL – InnoDB, MyISAM, Memory, CSV, Archive, Blackhole, Merge, Federated, Example.
Deployed on Linux distributions by default
On some Linux distributions, when you install the MySQL database, you might end up actually installing the MariaDB database, as it’s the default in many Linux distributions (though not in all).
MariaDB will be installed by default on latest Red Hat Enterprise/CentOS/Fedora/Debian distributions. On the other hand, MySQL is still the default on other popular distributions such as Ubuntu.
Availability on cloud platforms
MariaDB is available as a service on Amazon Web Services (AWS), Microsoft Azure and Rackspace Cloud.
MySQL is available on all three platforms mentioned above, while also available on Google Cloud’s platform, as a managed service.
Therefore, if you are using GCP and would like your cloud provider to manage the service for you, you might have to consider using MySQL, unless you would like to install and manage MariaDB instances on your own.
Licensing
MariaDB Server is licensed as GPLv2, while MySQL has two licensing options – GPLv2 (for Community edition) and Enterprise.
The main difference between the two licenses for MySQL is the available features and support. While you receive the full-featured package when using MariaDB, that’s not the case with MySQL. The community edition doesn’t include features like the Threadpool, which can have a significant impact on the database and query performance.
Release-rate and updates
Usually, MariaDB has more frequent releases then MySQL. This reality has its pros and cons though. On the upside, features and bug fixes are released more frequently. On the other side, managing those MariaDB servers requires more updates to keep them up to do date at all times.
Technical Support
The MySQL support team, which includes both MySQL developers and support engineers, offer 24/7 support for customers. Oracle offers several support packages, including Extended support, Sustaining support and Premier support, depending on the customer’s requirements. MariaDB’s support team includes support engineers which are familiar and are experts with both MariaDB and MySQL databases (as many of the features were originally written by MySQL’s team). They offer enterprise support for production systems, with 24/7 availability.
Ongoing Development
For MySQL, the exclusive developer is Oracle’s MySQL team. On the other hand, MariaDB’s development process is open for a public vote and mailing lists discussions. In addition, anyone can submit patches to MariaDB, which will be considered to be added to the main repository. Therefore, in a way, MariaDB is developed by the community, while MySQL is developed primarily by Oracle.
SQL Query Optimization
Whether you choose MySQL or MariaDB as your database vendor, you’ll probably end up struggling with some slow queries slowing down your application.
Well, we can’t make the decision for you. What we can do, is ask you the right questions to guide you to a decision:
Did you test your product’s performance with both databases? Which one performed better on average, and why?
Are you planning to use a feature which is exclusively available in one of these databases?
Are you aiming to use one of the database engines which is supported exclusively in one of these databases?
How important is it for you to be able to have an impact on the development process of the database you’re using? How important is it for you to have the community vote for the next changes?
Are you going to pay for enterprise versions or use the community version? Does the community version have enough features to meet your requirements?
Does your OS support the chosen database by default? How easy will it be for you to deploy it?
Which cloud provider are you using? Do they offer a managed service which includes the database you’ve chosen?
Are you planning to migrate from one database type to another in the future? If so, did you think about the implications in terms of incompatibilities and replication?
Once you answer these questions, you probably already have a good idea about which database is the right choice for you.
MySQL replication has evolved a lot in 5.6 ,5.7 and 8.0. This presentation focus on the changes made in parallel replication. It covers MySQL 8.0. It was presented at Mydbops database meetup on 04-08-2016 in Bangalore.
In this post we will see a case study of a Galera Cluster migration to AWS Aurora and quick solution to the replication issue. A friend received an error in a Master-Master replication as follows: Could not execute Write_rows event on table _database._table; Duplicate entry '65eJ8RmzASppBuQD2Iz73AAy8gPKIEmP-2018-08-03 08:30:03' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; […]
When you write programs that uses a database backend, it is necessary to use a connector/API to submit the queries and retrieve the result. If you are writing Python programs that used MySQL, you can use MySQL Connector/Python – the connector developered by Oracle Corporation.
Now there is a new book dedicated to the usage of the connector: MySQL Connector/Python Revealed, which is published by Apress. It is available in a softcover edition as well as an eBook (PDF, ePub, Mobi).
The book is divided into four parts spanning from the installation to error handling and troubleshooting. The four parts are:
Part I: Getting Ready
This part consists of a single chapter that helps you to get up and running. The chapter includes an introduction to MySQL Connector/Python and getting the connector and MySQL Server installed.
Part II: The Legacy APIs
The legacy APIs include the connector module that implements PEP249 (the Python Database API). The discussion of the mysql.connector module spans four chapters. In addition to query execution, the use of connection pools and the failover feature is covered. Finally, there is also a discussion about the C Extension.
Part III – The X DevAPI
One of the big new features in MySQL 8 is the MySQL Document Store including the X DevAPI. It allows you to use MySQL through the NoSQL API as well as by executing SQL queries. The NoSQL API includes support both for working with MySQL as a document store where the data is stored in JSON documents and with SQL tables. Part III includes three chapters that are dedicated to the X DevAPI.
Part IV – Error Handling and Troubleshooting The final part of book goes through the two important topics of error handling and troubleshooting including several examples of how common errors and how to resolve them.
With the book comes 66 code examples that are available for download from Apress’ GitHub repository. See the book’s homepage for instructions.
MySQL Connector/Python is available from several sources including online bookshops. The following table shows some of the places, where you can buy the book. (The table if current as of 13 August 2018; changes to the available formats may happen in the future.)
You would think if you want to change the setting for existing installation you can just stop the container with
docker stop
and when you want to start, passing new environment variable with
docker start
Unfortunately, this is not going to work as
docker start
does not support changing environment variables, at least not at the time of writing. I assume the idea is to keep container immutable and if you want container with different properties—like environment variables—you should run a new container instead. Here’s how.
Stop and Rename the old container, just in case you want to go back
Do not miss this step! When you destroy and recreate the container, all the updates you have done through PMM Web interface will be lost. What’s more, the software version will be reset to the one in the Docker image. Running an old PMM version with a data volume modified by a new PMM version may cause unpredictable results. This could include data loss.
Run the container with the new settings, for example changing METRICS_RESOLUTION
In this talk, we will learn about the Amazon Migration Tool. The talk will cover the possibilities, potential pitfalls prior to migrating and a high-level overview of its functionalities.
A while ago we released our FromDual Backup and Recovery Manager (brman) 2.0.0 for MariaDB and MySQL. So what are the new cool features of this new release?
First of all brman 2.0.0 is compatible with MariaDB 10.3 and MySQL 8.0:
shell> bman --target=brman:secret@127.0.0.1:3318 --type=full --mode=logical --policy=daily
Reading configuration from /etc/mysql/my.cnf
Reading configuration from /home/mysql/.my.cnf
No bman configuration file.
Command line: /home/mysql/product/brman-2.0.0/bin/bman.php --target=brman:******@127.0.0.1:3318 --type=full --mode=logical --policy=daily
Options from command line
target = brman:******@127.0.0.1:3318
type = full
mode = logical
policy = daily
Resulting options
config =
target = brman:******@127.0.0.1:3318
type = full
mode = logical
policy = daily
log = ./bman.log
backupdir = /home/mysql/bck
catalog-name = brman_catalog
Logging to ./bman.log
Backupdir is /home/mysql/bck
Hostname is chef
Version is 2.0.0 (catalog v0.2.0)
Start backup at 2018-08-13_11-57-31
Binary logging is disabled.
Schema to backup: mysql, foodmart, world, test
schema_name engine cnt data_bytes index_bytes table_rows
foodmart 0 0 0 0
mysql CSV 2 0 0 4
mysql InnoDB 4 65536 49152 17
mysql MyISAM 25 515327 133120 2052
test InnoDB 3 49152 0 0
world 0 0 0 0
/home/mysql/product/mariadb-10.3/bin/mysqldump --user=brman --host=127.0.0.1 --port=3318 --all-databases --quick --single-transaction --flush-logs --triggers --routines --hex-blob --events
to Destination: /home/mysql/bck/daily/bck_full_2018-08-13_11-57-31.sql
Backup size is 488835
Backup does NOT contain any binary log information.
Do MD5 checksum of uncompressed file /home/mysql/bck/daily/bck_full_2018-08-13_11-57-31.sql
md5sum --binary /home/mysql/bck/daily/bck_full_2018-08-13_11-57-31.sql
md5 = 31cab19021e01c12db5fe49165a3df93
/usr/bin/pigz -6 /home/mysql/bck/daily/bck_full_2018-08-13_11-57-31.sql
End backup at 2018-08-13 11:57:31 (rc=0)
Next brman also support mariabackup now:
shell> bman --target=brman:secret@127.0.0.1:3318 --type=full --mode=physical --policy=daily
...
Start backup at 2018-08-13_12-02-18
Backup with tool mariabackup version 10.3.7 (from path /home/mysql/product/mariadb-10.3/bin/mariabackup).
Schema to backup: mysql, foodmart, world, test
schema_name engine cnt data_bytes index_bytes table_rows
foodmart 0 0 0 0
mysql CSV 2 0 0 4
mysql InnoDB 4 65536 49152 17
mysql MyISAM 25 515327 133120 2052
test InnoDB 3 49152 0 0
world 0 0 0 0
Binary logging is disabled.
/home/mysql/product/mariadb-10.3/bin/mariabackup --defaults-file=/tmp/bck_full_2018-08-13_12-02-18.cnf --user=brman --host=127.0.0.1 --port=3318 --no-timestamp --backup --target-dir=/home/mysql/bck/daily/bck_full_2018-08-13_12-02-18
180813 12:02:19 Connecting to MySQL server host: 127.0.0.1, user: brman, password: set, port: 3318, socket: not set
Using server version 10.3.7-MariaDB
/home/mysql/product/mariadb-10.3/bin/mariabackup based on MariaDB server 10.3.7-MariaDB Linux (x86_64)
mariabackup: uses posix_fadvise().
mariabackup: cd to /home/mysql/database/mariadb-103/data/
mariabackup: open files limit requested 0, set to 1024
mariabackup: using the following InnoDB configuration:
mariabackup: innodb_data_home_dir =
mariabackup: innodb_data_file_path = ibdata1:12M:autoextend
mariabackup: innodb_log_group_home_dir = ./
2018-08-13 12:02:19 0 [Note] InnoDB: Number of pools: 1
mariabackup: Generating a list of tablespaces
2018-08-13 12:02:19 0 [Warning] InnoDB: Allocated tablespace ID 59 for mysql/transaction_registry, old maximum was 0
180813 12:02:19 >> log scanned up to (15975835)
180813 12:02:19 [01] Copying ibdata1 to /home/mysql/bck/daily/bck_full_2018-08-13_12-02-18/ibdata1
180813 12:02:19 [01] ...done
...
Then brman 2.0.0 supports seamlessly all three physical backup methods (mariabackup, xtrabackup, mysqlbackup) in their newest release.
On a customer request we have added the option --pass-through to pass additional specific options through to the final back-end application (mysqldump, mariabackup, xtrabackup, mysqlbackup):
As an example the customer wanted to pass through the option --ignore-table to mysqldump:
shell> bman --target=brman:secret@127.0.0.1:3318 --type=schema --mode=logical --policy=daily --schema=+world --pass-through="--ignore-table=world.CountryLanguage"
...
Start backup at 2018-08-13_12-11-40
Schema to backup: world
schema_name engine cnt data_bytes index_bytes table_rows
world InnoDB 3 655360 0 5411
Binary logging is disabled.
/home/mysql/product/mariadb-10.3/bin/mysqldump --user=brman --host=127.0.0.1 --port=3318 --quick --single-transaction --flush-logs --triggers --routines --hex-blob --databases 'world' --events --ignore-table=world.CountryLanguage
to Destination: /home/mysql/bck/daily/bck_schema_2018-08-13_12-11-40.sql
Backup size is 217054
Backup does NOT contain any binary log information.
Do MD5 checksum of uncompressed file /home/mysql/bck/daily/bck_schema_2018-08-13_12-11-40.sql
md5sum --binary /home/mysql/bck/daily/bck_schema_2018-08-13_12-11-40.sql
md5 = f07e319c36ee7bb1e662008c4c66a35a
/usr/bin/pigz -6 /home/mysql/bck/daily/bck_schema_2018-08-13_12-11-40.sql
End backup at 2018-08-13 12:11:40 (rc=0)
In the field it is sometimes wanted to not purge the binary logs during a binlog backup. So we added the option --no-purge to not purge binary logs during binlog backup. It looked like this before:
shell> bman --target=brman:secret@127.0.0.1:3326 --type=binlog --policy=binlog
...
Start backup at 2018-08-13_12-16-48
Binlog Index file is: /home/mysql/database/mysql-80/data/binlog.index
Getting lock: /home/mysql/product/brman-2.0.0/lck/binlog-logical-binlog.lock
Releasing lock: /home/mysql/product/brman-2.0.0/lck/binlog-logical-binlog.lock
FLUSH /*!50503 BINARY */ LOGS
Copy /home/mysql/database/mysql-80/data/binlog.000006 to /home/mysql/bck/binlog/bck_binlog.000006
Binary log binlog.000006 begin datetime is: 2018-08-13 12:14:14 and end datetime is: 2018-08-13 12:14:30
Do MD5 checksum of /home/mysql/bck/binlog/bck_binlog.000006
md5sum --binary /home/mysql/bck/binlog/bck_binlog.000006
md5 = a7ae2a271a6c90b0bb53c562c87f6f7a
/usr/bin/pigz -6 /home/mysql/bck/binlog/bck_binlog.000006
PURGE BINARY LOGS TO 'binlog.000007'
Copy /home/mysql/database/mysql-80/data/binlog.000007 to /home/mysql/bck/binlog/bck_binlog.000007
Binary log binlog.000007 begin datetime is: 2018-08-13 12:14:30 and end datetime is: 2018-08-13 12:14:31
Do MD5 checksum of /home/mysql/bck/binlog/bck_binlog.000007
md5sum --binary /home/mysql/bck/binlog/bck_binlog.000007
md5 = 5b592e597241694944d70849d7a05f53
/usr/bin/pigz -6 /home/mysql/bck/binlog/bck_binlog.000007
PURGE BINARY LOGS TO 'binlog.000008'
...
and like this after:
shell> bman --target=brman:secret@127.0.0.1:3326 --type=binlog --policy=binlog --no-purge
...
Start backup at 2018-08-13_12-18-52
Binlog Index file is: /home/mysql/database/mysql-80/data/binlog.index
Getting lock: /home/mysql/product/brman-2.0.0/lck/binlog-logical-binlog.lock
Releasing lock: /home/mysql/product/brman-2.0.0/lck/binlog-logical-binlog.lock
FLUSH /*!50503 BINARY */ LOGS
Copy /home/mysql/database/mysql-80/data/binlog.000015 to /home/mysql/bck/binlog/bck_binlog.000015
Binary log binlog.000015 begin datetime is: 2018-08-13 12:16:48 and end datetime is: 2018-08-13 12:18:41
Do MD5 checksum of /home/mysql/bck/binlog/bck_binlog.000015
md5sum --binary /home/mysql/bck/binlog/bck_binlog.000015
md5 = 1f9a79c3ad081993b4006c58bf1d6bee
/usr/bin/pigz -6 /home/mysql/bck/binlog/bck_binlog.000015
Copy /home/mysql/database/mysql-80/data/binlog.000016 to /home/mysql/bck/binlog/bck_binlog.000016
Binary log binlog.000016 begin datetime is: 2018-08-13 12:18:41 and end datetime is: 2018-08-13 12:18:42
Do MD5 checksum of /home/mysql/bck/binlog/bck_binlog.000016
md5sum --binary /home/mysql/bck/binlog/bck_binlog.000016
md5 = ef1613e99bbfa78f75daa5ba543e3213
/usr/bin/pigz -6 /home/mysql/bck/binlog/bck_binlog.000016
...
To make the logical backup (mysqldump) slightly faster we added the --quick option. This is done automatically and you cannot influence this behaviour.
Some of our customers use brman in combination with MyEnv and they want to have an overview of used software. So we made the version output of brman MyEnv compliant:
mysql@chef:~ [mariadb-103, 3318]> V
The following FromDual Toolbox Packages are installed:
------------------------------------------------------------------------
MyEnv: 2.0.0
BRman: 2.0.0
OpsCenter: 0.4.0
Fpmmm: 1.0.1
Nagios plug-ins: 1.0.1
O/S: Linux / Ubuntu
Binaries: mysql-5.7
mysql-8.0
mariadb-10.2
mariadb-10.3
------------------------------------------------------------------------
mysql@chef:~ [mariadb-103, 3318]>
In MySQL 5.7 general tablespaces were introduced. The utility mysqldump is not aware of general tablespaces and does not dump this information. This leads to errors during restore. FromDual brman checks for general tablespaces and writes them to the backup log so you can later extract this information at least from there. We consider this as a bug in mysqldump. MariaDB up to 10.3 has not implemented this feature yet so it is not affected of this problem.
FromDual brman backups are quite complex and can run quite some long time thus timestamps are logged so we can find out where the time is spent or where the bottlenecks are:
...
At 2018-08-13 12:27:17 do MD5 checksum of uncompressed file /home/mysql/bck/daily/bck_full_2018-08-13_12-27-16/ib_logfile0
md5sum --binary /home/mysql/bck/daily/bck_full_2018-08-13_12-27-16/ib_logfile0
md5 = d41d8cd98f00b204e9800998ecf8427e
At 2018-08-13 12:27:17 compress file /home/mysql/bck/daily/bck_full_2018-08-13_12-27-16/ib_logfile0
/usr/bin/pigz -6 /home/mysql/bck/daily/bck_full_2018-08-13_12-27-16/ib_logfile0
At 2018-08-13 12:27:18 do MD5 checksum of uncompressed file /home/mysql/bck/daily/bck_full_2018-08-13_12-27-16/ibdata1
md5sum --binary /home/mysql/bck/daily/bck_full_2018-08-13_12-27-16/ibdata1
md5 = 097ab6d70eefb6e8735837166cd4ba54
At 2018-08-13 12:27:18 compress file /home/mysql/bck/daily/bck_full_2018-08-13_12-27-16/ibdata1
/usr/bin/pigz -6 /home/mysql/bck/daily/bck_full_2018-08-13_12-27-16/ibdata1
At 2018-08-13 12:27:19 do MD5 checksum of uncompressed file /home/mysql/bck/daily/bck_full_2018-08-13_12-27-16/xtrabackup_binlog_pos_innodb
...
A general FromDual policy is to not use the MariaDB/MySQL root user for anything except direct DBA interventions. So backup should be done with its own user. FromDual suggest brman as a username and the utility complains with a warning if root is used:
shell> bman --target=root@127.0.0.1:3318 --type=full --policy=daily
...
Start backup at 2018-08-13_12-30-29
WARNING: You should NOT use the root user for backup. Please create another user as follows:
CREATE USER 'brman'@'127.0.0.1' IDENTIFIED BY 'S3cret123';
GRANT ALL ON *.* TO 'brman'@'127.0.0.1';
If you want to be more restrictive you can grant privileges as follows:
GRANT SELECT, LOCK TABLES, RELOAD, PROCESS, TRIGGER, SUPER, REPLICATION CLIENT, SHOW VIEW, EVENT ON *.* TO 'brman'@'127.0.0.1';
Additionally for MySQL Enterprise Backup (MEB):
GRANT CREATE, INSERT, DROP, UPDATE ON mysql.backup_progress TO 'brman'@'127.0.0.1';
GRANT CREATE, INSERT, SELECT, DROP, UPDATE ON mysql.backup_history TO 'brman'@'127.0.0.1';
GRANT FILE ON *.* TO 'brman'@'127.0.0.1';
GRANT CREATE, INSERT, DROP, UPDATE ON mysql.backup_sbt_history TO 'brman'@'127.0.0.1';
Additionally for MariaBackup / XtraBackup:
GRANT INSERT, SELECT ON PERCONA_SCHEMA.xtrabackup_history TO 'brman'@'127.0.0.1';
...
Some customers have implemented a monitoring solution. FromDual brman can report backup return code, backup run time and backup size to the FromDual Performance Monitor for MariaDB and MySQL (fpmmm/Zabbix) now:
Some customers run their databases on shared hosting systems or in cloud solutions where they do not have all the needed database privileges. For those users FromDual brman is much less intrusive now and allows backups on those restricted systems as well:
#
# /home/shinguz/etc/brman.conf
#
policy = daily
target = shinguz_brman:secret@localhost
type = schema
per-schema = on
schema = -shinguz_shinguz
log = /home/shinguz/log/bman_backup.log
backupdir = /home/shinguz/bck
shell> /home/shinguz/brman/bin/bman --config=/home/shinguz/etc/brman.conf 1>/dev/null
...
WARNING: Binary logging is enabled but you are lacking REPLICATION CLIENT privilege. I cannot get Master Log File and Pos!
WARNING: I cannot check for GENERAL tablespaces. I lack the PROCESS privilege. This backup might not restore in case of presence of GENERAL tablespaces.
...
Details: Check for binary logging is made less intrusive. If RELOAD privilege is missing --master-data and/or --flush-logs options are omitted. Schema backup does not require SHOW DATABASES privilege any more.
Some customers want to push theire backups directly to an other server during backup (not pull from somewhere else). For those customers the new option --archivedestination was introduced which replaces the less powerfull option --archivedir which is deprecated. So archiving with rsync, scp and sftp is possible now (NFS mounts was possible before already):
shell> bman --target=brman:secret@127.0.0.1:3318 --type=full --policy=daily --archivedestination=sftp://oli@backup.fromdual.com:22/home/oli/bck/production/daily/
...
/home/mysql/product/mysql-5.7.21/bin/mysqldump --user=root --host=127.0.0.1 --port=33006 --master-data=2 --quick --single-transaction --triggers --routines --hex-blob --events 'tellmatic'
to Destination: /home/mysql/backup/daily/bck_schema_tellmatic_2018-08-13_11-41-26.sql
Backup size is 602021072
Binlog file is mysql-bin.019336 and position is 287833
Do MD5 checksum of uncompressed file /home/mysql/backup/daily/bck_schema_tellmatic_2018-08-13_11-41-26.sql
md5sum --binary /home/mysql/backup/daily/bck_schema_tellmatic_2018-08-13_11-41-26.sql
md5 = 06e1a0acd5da8acf19433b192259c1e1
/usr/bin/pigz -6 /home/mysql/backup/daily/bck_schema_tellmatic_2018-08-13_11-41-26.sql
Archiving /home/mysql/backup/daily/bck_schema_tellmatic_2018-08-13_11-41-26.sql.gz to sftp://oli@backup.example.com:/home/oli/bck/production/daily/
echo 'put "/home/mysql/backup/daily/bck_schema_tellmatic_2018-08-13_11-41-26.sql.gz"' | sftp -b - -oPort=22 oli@backup.fromdual.com:/home/oli/bck/production/daily/
End backup at 2018-08-13 11:42:19 (rc=0)
This may be a “duh” post for some, but I had to post this because I didn’t find the answer in typical places like stackoverflow when I had the issue. I recently worked on a project to expand database capacity by deploying new MySQL installations with memory, config, and disk space tweaks by backup/restore, replication topology change and, and failover. I did not notice that the old servers had “explicit_defaults_for_timestamp=OFF”. After restoring a binary backup and starting the replication thread on the new systems I got this error in the replication thread (column name in error corresponds to examples further down).
ERROR 1048 (23000): Column 'ts' cannot be null
Below, I will provide a synopsis to show statements that caused the error and why a simple global variable change fixed the issue. First, a sample table definition.
CREATE TABLE `time_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`comment` varchar(32) NOT NULL,
`ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=latin1
Notice, the timestamp has a default of current_timestamp. Next, a statement that works fine.
mysql> insert into time_test (comment) values ('this is statement 1');
“id” and “ts” columns are omitted to allow MySQL to generate both the ID and the timestamp value.
Next – a statement that does not work, similar to the one I encountered in my replication thread.
mysql> insert into time_test (comment,ts) values ('this is statement 2',NULL);
ERROR 1048 (23000): Column 'ts' cannot be null
With MySQL and many other databases, even though we have the “DEFAULT CURRENT_TIMESTAMP” on our timestamp column, explicitly supplying NULL in the INSERT statement is “non-standard” syntax. Standard syntax would be to omit the column in the column spec and VALUES (e.g. query 1). We get the error because of the default value of explicit_defaults_for_timestamp. From the MySQL manual, “This system variable determines whether the server enables certain nonstandard behaviors for default values and NULL-value handling in TIMESTAMP columns. By default, explicit_defaults_for_timestamp is enabled, which disables the nonstandard behaviors.”
I was working with an application with deprecated SQL syntax. In fact, this syntax may be legal on some modern databases; just not by default on MySQL. If a reader knows of databases where this is legal, please feel free to comment.
The fix for this is as simple as it gets, which is probably why there are not more posts about this.
mysql> set global explicit_defaults_for_timestamp='OFF';
Query OK, 0 rows affected (0.00 sec)
Because this is a global variable, one must log out and log back into the CLI. After reconnecting:
mysql> insert into time_test (comment,ts) values ('this is statement 2',NULL);
Query OK, 1 row affected (0.01 sec)
mysql> select * from time_test;
+----+---------------------+---------------------+
| id | comment | ts |
+----+---------------------+---------------------+
| 1 | this is statement 1 | 2018-08-14 02:51:21 |
| 2 | this is statement 2 | 2018-08-14 02:52:20 |
+----+---------------------+---------------------+
2 rows in set (0.00 sec)
In my case, as soon as the global variable was set, I was able to start my replication thread back up. Thanks for reading my reference post.
MySQL 8.0 introduced a new feature that allows you to persist configuration changes from inside MySQL. Previously you could execute SET GLOBAL to change the configuration at runtime, but you needed to update your MySQL configuration file in order to persist the change. In MySQL 8.0 you can skip the second step. This blog discuss how this works and how to backup and restore the configuration.
Using SET PERSIST to set a variable and the persisted_variables table in the Performance Schema to get a list of persisted variables.
Persisting Variables
You persist changes with either the SET PERSIST or SET PERSIST_ONLY statement. The different is that SET PERSIST_ONLY only updates the configuration whereas SET PERSIST essentially combines SET GLOBAL and SET PERSIST_ONLY.
Note: Some variables such as innodb_buffer_pool_instances can only use PERSIST_ONLY, i.e. it requires a restart to make the changes take effect. Still others, such as datadir can currently not be persisted.
mysqld-auto.cnf and variables_info
The persisted variables are stored in the file mysqld-auto.cnf located in the data directory using the JSON format. It includes more information than just the persisted value. It also includes information such as who made the change and when. An example file is:
Notice that the source for join_buffer_size is DYNAMIC whereas the two other variables have the source set to PERSISTED. Why? After all they all three existed in the mysqld-auto.cnf file. DYNAMIC means that the variable was changes since the last restart either using SET GLOBAL or SET PERSIST. Another thing to be aware of is that variables changed with SET PERSIST_ONLY will not show up in variables_info until after the next restart. I will soon get back to show a way to get the variables that have been persisted in one way or another.
Backup and Restore
As a simple way to back up the configuration is simply copy the mysqld-auto.cnf file to a safe location. Similarly, you can restore the configuration by copying it back.
However, what if you want most of the configuration but not everything or you want to edit some of the values? In that case you need another way of exporting the configuration as you should not manually edit mysqld-auto.cnf.
Warning: Do not edit the mysqld-auto.cnf file manually. It should only be changed with SET PERSIST and SET PERSIST_ONLY. If there are any errors in the file, MySQL will refuse to start.
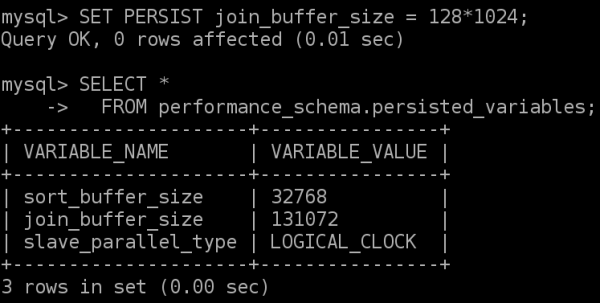
Fortunately as it turns out, it is easy to export all persisted variables. The table performance_schema.persisted_variables includes all variables that has either been read from mysqld-auto.cnf or has been changed with SET PERSIST or SET PERSIST_ONLY since the last restart. The table include the persisted values. For example:
Note: On Microsoft Windows ensure everything is on one line and the backslashes are removed.
Now the file config.sql contains an export of the persisted variables:
shell$ cat config.sql
SET PERSIST_ONLY sort_buffer_size = 32768;
SET PERSIST_ONLY join_buffer_size = 131072;
SET PERSIST_ONLY slave_parallel_type = 'LOGICAL_CLOCK';
This example creates SET PERSIST_ONLY statement as those will work with all persistable variables. When you replay the SET statements, it will require a restart of MySQL for the changes to take effect. If you want to use SET PERSIST where possible, then you need to take into consideration whether the variable support SET PERSIST. A list of variables that require SET PERSIST_ONLY are included at the end.
As promised, I will conclude with a list of persistable variables that only supports SET PERSIST_ONLY. As of MySQL 8.0.12 without any plugins installed, the variables are:
This article is inspired by Percona blog post comparing MySQL 8.0 and Percona Server 5.7 on IO-bound
workload with Intel Optane storage. There are several claims made by Vadim based on a single test case, which is simply unfair. So, I'll try to clarify this all based on more test results and more
tech details..
But before we start, some intro :
InnoDB Parallel Flushing -- was introduced with MySQL 5.7 (as a single-thread flushing could no more follow), and implemented as dedicated parallel threads
(cleaners) which are involved in background once per second to do LRU-driven flushing first (in case there is no more or too low amount of free pages) and then REDO-driven flushing (to flush the
oldest dirty pages and allow more free space in REDO). The amount of cleaners was intentionally made configurable as there were many worries that these threads will use too much CPU ;-)) -- but at
least configuring their number equal to number of your Buffer Pool (BP) Instances was resulting in nearly the same as if you have dedicated cleaner-per-BP-instance.
Multi-threaded LRU Flusher -- was introduced in Percona Server 5.7, implementing dedicated LRU cleaners (one thread per BP instance) independently running in background. The real valid
point in this approach is to keep LRU cleaners independent to so called "detected activity" in InnoDB (which was historically always buggy), so whatever happens, every LRU cleaner remains active to
deliver free pages according the demand. While in MySQL 5.7 the same was expected to be covered by involving "free page event" (not what I'd prefer, but this is also historical to InnoDB). However,
on any IO-bounded workload I've tested with MySQL 5.7 and 8.0 by configuring 16 BP instances with 16 page cleaners and with LRU depth setting matching the required free page rate -- I've never
observed lower TPS comparing to Percona..
Single Page Flushing -- historically, in InnoDB when a user thread was not able to get a free page for its data, it was involving a "single page flush" itself, expecting to get a free page
sooner -- the motivation behind such an approach was "better to try to do something than just do nothing". And this was blamed so often.. -- while, again, it's largely exaggerated, because the only
real problem here is coming due a historical "limited space" for single page flush in DoubleWrite Buffer, and that's all. To be honest, making this option configurable could allow anyone to evaluate
it very easily and decide to keep it ON or not by his own results ;-))
DoubleWrite Buffer -- probably one of the biggest historical PITA in InnoDB.. -- the feature is implemented to guarantee page "atomic writes" (e.g. to avoid partially written pages, each
page is written first to DoubleWrite (DBLWR) place, and only then to its real place in data file). It was still "good enough" while storage was very slow, but quickly became a bottleneck on faster
storage. However, such a bottleneck you could not observe on every workload.. -- despite you have to write your data twice, but as long as your storage is able to follow and you don't have waits on
IO writes (e.g. not on REDO space nor on free pages) -- your overall TPS will still not be impacted ;-)) The impact is generally becomes visible since 64 concurrent users (really *concurrent*, e.g.
doing things on the same time). Anyway, we addressed this issue yet for MySQL 5.7, but our fix arrived after GA date, so it was not delivered with 5.7 -- on the same time Percona delivered their
"Parallel DoubleWrite", solving the problem for Percona Server 5.7 -- lucky guys, kudos for timing ! ;-))
Now, why we did NOT put all these points on the first priority for MySQL 8.0 release ?
there is one main thing changes since MySQL 8.0 -- for the first time in MySQL history we decided to move to "continuous release" model !
which means that we may still deliver new changes with every update ;-))
(e.g. if the same was possible with 5.7, the fix for DBLWR would be already here)
however, we should be also "realistic" as we cannot address fundamental changes in updates..
so, if any fundamental changes should be delivered, they should be made before GA deadline
and the most critical from such planned changes was our new REDO log
implementation !
(we can address DBLWR and other changes later, but redesigning REDO is much more complex story ;-))
so, yes, we're aware about all the real issues we have, and we know how to fix them -- and it's only a question of time now..
So far, now let's see what of the listed issues are real problems and how much each one is impacting ;-))
x2 Optane drives used together as a single RAID-0 volume via MDM
same OL7.4, EXT4
Sysbench 50M x 8-tables data volume (same as I used before, and then Vadim)
Similar my.conf but with few changes :
trx_commit=1 (flush REDO on every COMMIT as before)
PFS=on (Performance Schema)
checksums=on (crc32)
doublewrite=off/on (to validate the impact)
binlog=off/on & sync_binlog=1 (to validate the impact as well)
Test scenarios :
Concurrent users : 32, 64, 128
Buffer Pool : 128GB / 32GB
Workload : Sysbench OLTP_RW 50Mx8tab (100GB)
Config variations :
1) base config + dblwr=0 + binlog=0
2) base config + dblwr=1 + binlog=0
3) base config + dblwr=0 + binlog=1
4) base config + dblwr=1 + binlog=1
where base config : trx_commit=1 + PFS=on + checksums=on
NOTE : I did not build for all the following test results "user friendly" charts -- all the graphs are representing real TPS (Commit/sec) stats collected during the tests, and matching 3 load
levels : 32, 64, and 128 concurrent users.
128GB BUFFER POOL
So far, let's start first with Buffer Pool =128GB :
with Buffer Pool (BP) of 128GB we keep the whole dataset "cached" (so, no IO reads)
NOTE : PFS=on and checksums=on -- while TPS is mostly the same as in the previous test
on the same data volume (where both PFS & checksums were OFF), they are not impacting here
as well from the previous test you can see that even if the data are fully cached in BP, there is still an impact due used storage -- the result on Intel SSD was way lower than on Intel Optane
so, in the current test result you can see that MySQL 8.0 also getting better benefit from a faster storage comparing to Percona Server, even if the given test is mostly about REDO related
improvements ;-))
MySQL Connector/NET 6.10.8 is the fifth GA release with .NET Core
now supporting various connection-string options and MySQL 8.0 server
features.
To download MySQL Connector/NET 6.10.8 GA, see the “Generally Available
(GA) Releases” tab at http://dev.mysql.com/downloads/connector/net/
Changes in Connector/NET 6.10.8 (2018-08-14, General Availability)
Functionality Added or Changed
* Optimistic locking for database-generated fields was
improved with the inclusion of the [ConcurrencyCheck,
DatabaseGenerated(DatabaseGeneratedOption.Computed)]
attribute. Thanks to Tony Ohagan for the patch. (Bug
#28095165, Bug #91064)
* All recent additions to .NET Core 2.0 now are compatible
with the Connector/NET 6.10 implementation.
* With the inclusion of the Functions.Like extended method,
scalar-function mapping, and table-splitting
capabilities, Entity Framework Core 2.0 is fully
supported.
Bugs Fixed
* EF Core: An invalid syntax error was generated when a new
property (defined as numeric, has a default value, and is
not a primary key) was added to an entity that already
contained a primary-key column with the AUTO_INCREMENT
attribute. This fix validates that the entity property
(column) is a primary key first before adding the
attribute. (Bug #28293927)
* EF Core: The implementation of some methods required to
scaffold an existing database were incomplete. (Bug
#27898343, Bug #90368)
* The Entity Framework Core implementation did not render
accented characters correctly on bases with different
UTF-8 encoding. Thanks to Kleber kleberksms for the
patch. (Bug #27818822, Bug #90316)
* The Microsoft.EntityFrameworkCore assembly (with EF Core
2.0) was not loaded and the absence generated an error
when the application project was built with any version
of .NET Framework. This fix ensures the following
support:
+ EF Core 1.1 with .NET Framework 4.5.2 only
+ EF Core 2.0 with .NET Framework 4.6.1 or later
(Bug #27815706, Bug #90306)
* Attempts to create a new foreign key from within an
application resulted in an exception when the key was
generated by a server in the MySQL 8.0 release series.
(Bug #27715069)
* A variable of type POINT when used properly within an
application targeting MySQL 8.0 generated an SQL syntax
error. (Bug #27715007)
* The case-sensitive lookup of field ordinals was
initialized using case-insensitive comparison logic. This
fix removes the original case-sensitive lookup. (Bug
#27285641, Bug #88950)
* The TreatTinyAsBoolean connection option was ignored when
the MySqlCommand.Prepare() method was called. (Bug
#27113566, Bug #88472)
* The MySql.Data.Types.MySqlGeometry constructor called
with an array of bytes representing an empty geometry
collection generated an ArgumentOutOfRangeException
exception, rather than creating the type as expected.
Thanks to Peet Whittaker for the patch. (Bug #26421346,
Bug #86974)
* Slow connections made to MySQL were improved by reducing
the frequency and scope of operating system details
required by the server to establish and maintain a
connection. (Bug #22580399, Bug #80030)
* All columns of type TINYINT(1) stopped returning the
expected Boolean value after the connector encountered a
NULL value in any column of this type. Thanks to David
Warner for the patch. (Bug #22101727, Bug #78917)
Building Airbnb’s Change Data Capture system (SpinalTap), to enable propagating & reacting to data mutations in real time.
The dining hall in the San Francisco Office is always gleeming with natural sunlight!
Labor day weekend is just around the corner! Karim is amped for a well deserved vacation. He logs in to Airbnb to start planning a trip to San Francisco, and stumbles upon a great listing hosted by Dany. He books it.
A moment later, Dany receives a notification that his home has been booked. He checks his listing calendar and sure enough, those dates are reserved. He also notices the recommended daily price has increased for that time period. “Hmm, must be a lot of folks looking to visit the city over that time” he mumbles. Dany marks his listing as available for the rest of that week...
All the way on the east coast, Sara is sipping tea in her cozy Chelsea apartment in New York, preparing for a business trip to her company’s HQ in San Francisco. She’s been out of luck for a while and about to take a break, when Dany’s listing pops up on her search map. She checks out the details and it looks great! She starts writing a message: “Dear Dany, I’m traveling to San Francisco and your place looks perfect for my stay…”
Adapting to data evolution has presented itself as a recurrent need for many emerging applications at Airbnb over the last few years. The above scenario depicts examples of that, where dynamic pricing, availability, and reservation workflows need to react to changes from different components in our system in near real-time. From an infrastructure perspective, designing our architecture to scale is a necessity as we continually grow both in terms of data and number of services. Yet, as part of striving towards a service-oriented architecture, an efficient manner of propagating meaningful data model mutations between microservices while maintaining a decoupled architecture that preserved data ownership boundaries was just as important.
In response, we created SpinalTap; a scalable, performant, reliable, lossless Change Data Capture service capable of detecting data mutations with low latency across different data source types, and propagating them as standardized events to consumers downstream. SpinalTap has become an integral component in Airbnb’s infrastructure and derived data processing platform, on which several critical pipelines rely. In this blog, we will present an overview of the system architecture, use cases, guarantees, and how it was designed to scale.
Background
Change Data Capture (CDC) is a design pattern that enables capturing changes to data and notifying actors so they can react accordingly. This follows a publish-subscribe model where change to a data set is the topic of interest.
Requirements
Certain high-level requirements for the system were desirable to accommodate for our use cases:
Lossless: Zero tolerance to data loss, a requirement for on-boarding critical applications such as a stream-based accounting audit pipeline
Scalable: Horizontallyscalable with increased load and data cluster size, to avoid recurrent re-design of the system with incremental growth
Performant: Changes are propagated to subscribed consumers in near real-time (sub-second)
Consistent: Ordering and timeline consistency are enforced to retain sequence of changes for a specific data record
Fault Tolerant: Highly available with a configurable degree of redundancy to be resilient to failure
Extensible: A generic framework that can accommodate for different data source and sink types
Solutions Considered
There are several solutions promoted in literature for building a CDC system, the most referenced of which are:
Polling: A time-driven strategy can be used to periodically check whether any changes have been committed to the records of a data store, by keeping track of a status attribute (such as last updated or version)
Triggers: For storage engines that support database triggers (ex: MySQL), stored procedures triggered on row-based operations, those can be employed to propagate changes to other data tables in a seamless manner
Dual Writes: Data changes can be communicated to subscribed consumers in the application layer during the request, such as by emitting an event or scheduling an RPC after write commit
Audit Trail: Most data storage solutions maintain a transaction log (or changelog) to record and track changes committed to the database. This is commonly used for replication between cluster nodes, and recovery operations (such as unexpected server shutdown or failover).
There are several desirable features of employing the database changelog for detecting changes: reading from the logs allows for an asynchronous non-intrusive approach to capturing changes, as compared to triggers and polling strategies. It also supports strong consistency and ordering guarantees on commit time, and retains transaction boundary information, both of which are not achievable with dual writes. This allows to replay events from a certain point-in-time. With this in mind, SpinalTap was designed based on this approach.
Architecture
High level workflow overview
At a high-level, SpinalTap was designed to be a general purpose solution that abstracts the change capture workflow, enough to be easily adaptable with different infrastructure dependencies (data stores, event bus, consumer services). The architecture is comprised of 3 main components that aid in providing sufficient abstraction to achieve these qualities:
The source represents the origin of the change event stream from a specific data store. The source abstraction can be easily extended with different data source types, as long as there is an accessible changelog to stream events from. Events parsed from the changelog are filtered, processed, and transformed to corresponding mutations. A mutation is an application layer construct that represents a single change (insert, update, or delete) to a data entity. It includes the entity values before & after the change, a globally unique identifier, transaction information, and metadata derived from the originating source event. The source is also responsible for detecting dataschema evolution, and propagating the schema information accordingly with the corresponding mutations. This is important to ensure consistency when deserializing the entity values on the client side or replaying events from an earlier state.
The destination represents a sink for mutations, after being processed and converted to standardized event. The destination also keeps track of the last successfully published mutation, which is employed to derive the source state position to checkpoint on. The component abstracts away the transport medium and format used. At Airbnb, we employ Apache Kafka as event bus, given its wide usage within our infrastructure. Apache Thrift is used as the data format to offer a standardized mutation schema definition and cross-language support (Ruby & Java).
A major performance bottleneck identified through benchmarking on the system was mutation publishing. The situation was aggravated given our system settings were chosen to favor strong consistency over latency. To relieve the situation, we incorporated a few optimizations:
Buffered Destination: To avoid the source being blocked while waiting for mutations to be published, we employ an in-memory bounded queue to buffer events emitted from the source (consumer-producer pattern). The source would add events to the buffer while the destination is publishing the mutations. Once available, the destination would drain the buffer and process the next batch of mutations.
Destination Pool: For sources that display erratic spiky behavior in incoming event rate, the in-memory buffer gets saturated occasionally causing intermittent degradation in performance. To relieve the system from irregular load patterns, we employed application-level partitioning of the source events to a configurable set of buffered destinations managed by a thread pool. Events are multiplexed to thread destinations while retaining the ordering schema. This enabled us to achieve high throughput while not compromising latency or consistency.
The pipe coordinates the workflow between a given source and destination. It represents the basic unit of parallelism. It’s also responsible for periodically checkpointing source state, and managing the lifecycle of event streaming. In case of erroneous behavior, the pipe performs graceful shutdown and initiates the failure recovery process. A keep-alive mechanism is employed to ensure source streaming is restarted in event of failure, according to last state checkpoint. This allows to auto-remediate from intermittent failures while maintaining data integrity. The pipe manager is responsible for creating, updating, and removing pipes, as well as the pipe lifecycle (start/stop), on a given cluster node. It also ensures any changes to pipe configuration are propagated accordingly in run-time.
To achieve certain desirable architectural aspects — such as scalability, fault-tolerance, and isolation — we adopted a cluster management framework (Apache Helix) to coordinate distribution of stream processing across compute resources. This helped us achieve deterministic load balancing, and horizontal scaling with automatic redistribution of source processors across the cluster.
To promote high availability with configurable fault tolerance, each source is appointed a certain subset of cluster nodes to process event streaming. We use a Leader-Standby state model, where only one node streams events from a source at any given point, while the remaining nodes in the sub cluster are on standby. If the leader is down, then one of the standby nodes will assume leadership.
To support isolation between source type processing, each node in the cluster is tagged with the source type(s) that can be delegated to it. Stream processing is distributed across cluster nodes while maintaining this isolation criteria.
For resolving inconsistencies from network partition, in particular the case where more than one node assume leadership over streaming from a specific source (split brain), we maintain a global leader epoch per source that is atomically incremented on leader transition. The leader epoch is propagated with each mutation and inconsistencies are consequently mitigated with client-side filtering, by disregarding events that have a smaller epoch than the latest observed.
Guarantees
Certain guarantees were essential for the system to uphold, to accommodate for all downstream uses cases.
Data Integrity: The system maintains anat-least-once delivery guarantee, where any change to the underlying data store is eventually propagated to clients. This dictates that no event present in the changelog is permanently lost, and is delivered within the time window specified by our SLA. We also ensure there is no data corruption incurred, and mutation content maintains parity that of the source event .
Event Ordering: Ordering is enforced according to the defined partitioning scheme. We maintain ordering per data record (row), i.e. all changes to a specific row in a given database table will be received in commit order.
Timeline Consistency: Being consistent across a timeline demands that changes are received chronologically within a given time frame, i.e. two sequences of a given mutation set are not sent interleaved. A split brain scenario can potentially compromise this guarantee, but is mitigated with epoch fencing as explained earlier.
Validation
The SpinalTap validation framework
Justifying there is no breach in SpinalTap’s guarantees by virtue of design was not sufficient, and we wanted a more pragmatic data-driven approach to validate our assumptions. To address this, we developed a continuous online end-to-end validation pipeline, responsible for validating the mutations received on the consumer side against the source of truth, and asserting no erroneous behavior is detected in both pre-production and production environments.
To achieve a reliable validation workflow, consumed mutations are partitioned and stored on local disk, with the same partitioning scheme applied to source events. Once all mutations corresponding to events of a partition are received, the partition file is validated against with the originating source partition through a list of tests that asserted the guarantees described earlier. For MySQL specifically, the binlog file was considered a clean partition boundary.
We set up offline integration testing in a sandbox environment to prevent any regression from being deployed to production. The validator is also employed online in production by consuming live events for each source stream. This aids as a safeguard to detect any breaches that are not caught within our testing pipeline, and automatically remediate by rolling back source state to a previous checkpoint. This enforces that streaming does not proceed until any issues are resolved, and eventually guarantee consistency and data integrity.
Model Mutations
Left: Sync vs Async app workflow; Right: Propagating model mutations to downstream consumers
A shortcomings of consumer services tapping directly into SpinalTap events for a given service’s database is that the data schema is leaked, creating unnecessary coupling. Furthermore, domain logic for processing data mutations encapsulated in the owning service needs to be replicated to consumer services as well.
To mitigate the situation, we built a model streaming library on top of SpinalTap, which allowed services to listen to events from a service’s data store, transform them to domain model mutations, and re-inject them in the message bus. This effectively allowed data model mutations to become part of the service’s interface, and segregation of the request/response cycle from asynchronous data ingestion and event propagation. It also helped decouple domain dependencies, facilitate event-driven communication, and provide performance & fault tolerance improvements to services by isolating synchronous & asynchronous application workflows.
Use Cases
SpinalTap is employed for numerous use cases within our infrastructure, the most prominent of which are:
Cache Invalidation: A common application for CDC systems is cache invalidation, where changes to the backing data store are detected by a cache invalidator service or process that consequently evicts (or updates) the corresponding cache entries. Preferring an asynchronous approach allowed us to decouple our caching mechanism from the request path, and application code that serves production traffic. This pattern is widely used amongst services to maintain consistency between the source of truth data stores and our distributed cache clusters (e.g. Memcached, Redis).
Search Indexing: There are multiple search products at Airbnb that use real-time indexing (e.g. review search, inbox search, support ticket search). SpinalTap proved to be a good fit for building the indexing pipeline from data stores to the search backends (e.g. ElasticSearch), particularly due to its in-order and at least once delivery semantics. Services can easily consume events for the corresponding topics and convert the mutations to update the indices, which helps ensure search freshness with low latency.
Offline Processing: SpinalTap is also employed to export the online datastores to our offline big data processing systems (e.g. Hive, Airstream) in a streaming manner, which requires high throughput, low latency, and proper scalability. The system was also used historically for our database snapshot pipeline, to continuously construct backups of our online database and store them in HBase. This dramatically reduced the time to land our daily backups, and allowed for taking snapshots at a finer time granularity (ex: hourly).
Signaling: Another recurrent use cases for propagating data changes in a distributed architecture is as a signaling mechanism, where depending services can subscribe and react to data changes from another service in near real time. For example, the Availability service would block a listing’s dates by subscribing to changes from the Reservation service to be notified when a booking was made. Risk, security, payments, search, and pricing workflows are a few examples of where this pattern is employed within our ecosystem.
Conclusion
SpinalTap has become an integral part of our infrastructure over the last few years, and a system fueling many of our core workflows. It can be particularly useful for platforms looking for a reliable general purpose framework that can be easily integrated with your infrastructure. At Airbnb, SpinalTap is used to propagate data mutations from MySQL, DynamoDB, and our in-house storage solution. Kafka is currently the event bus of choice, but the system’s extensibility has allowed us to consider other mediums as well (ex: Kinesis).
Lastly, we have open-sourced several of our library components, and are in the process of reviewing the remaining modules for general release as well. Contributions are more than welcome!

 Please join Autodesk’s Senior Database Engineer, Vineet Khanna, and Percona’s Sr. MySQL DBA, Tate McDaniel as they present Migrating to Aurora and Monitoring with PMM on Thursday, August 9th, 2018, at 10:00 AM PDT (UTC-7) / 1:00 PM EDT (UTC-4).
Please join Autodesk’s Senior Database Engineer, Vineet Khanna, and Percona’s Sr. MySQL DBA, Tate McDaniel as they present Migrating to Aurora and Monitoring with PMM on Thursday, August 9th, 2018, at 10:00 AM PDT (UTC-7) / 1:00 PM EDT (UTC-4). Vineet Khanna, Senior Database Engineer, Autodesk
Vineet Khanna, Senior Database Engineer, Autodesk




 Join Percona Chief Evangelist Colin Charles as he covers happenings, gives pointers and provides musings on the open source database community.
Join Percona Chief Evangelist Colin Charles as he covers happenings, gives pointers and provides musings on the open source database community.








 Please join Percona’s Solution Engineer, Dimitri Vanoverbeke as he presents
Please join Percona’s Solution Engineer, Dimitri Vanoverbeke as he presents