MySQL introduced a JSON data type in version 5.7, and expanded the functionality in version 8.0.
Besides being able to store native JSON in MySQL, you can also use MySQL as a document store (doc store) to store JSON documents. And, you can use NoSQL CRUD (create, read, update and delete) commands in either JavaScript or Python.
This post will show you some of the basic commands for using MySQL as a document store.
Requirements
To use MySQL as a document store, you will need to use the following server features:
The X Plugin enables the MySQL Server to communicate with clients using the X Protocol, which is a prerequisite for using MySQL as a document store. The X Plugin is enabled by default in MySQL Server as of MySQL 8.0. For instructions to verify X Plugin installation and to configure and monitor X Plugin, see Section 20.5, “X Plugin”.
The X Protocol supports both CRUD and SQL operations, authentication via SASL, allows streaming (pipelining) of commands and is extensible on the protocol and the message layer. Clients compatible with X Protocol include MySQL Shell and MySQL 8.0 Connectors.
Clients that communicate with a MySQL Server using X Protocol can use X DevAPI to develop applications. X DevAPI offers a modern programming interface with a simple yet powerful design which provides support for established industry standard concepts. This chapter explains how to get started using either the JavaScript or Python implementation of X DevAPI in MySQL Shell as a client. See X DevAPI for in-depth tutorials on using X DevAPI.
(source: https://dev.mysql.com/doc/refman/8.0/en/document-store.html)
And, you will need to have MySQL version 8.0.x (or higher) installed, as well as the MySQL Shell version 8.0.x (or higher). For these examples, I am using version 8.0.17 of both. (You could use version 5.7.x, but I have not tested any of these commands in 5.7.x)
Starting MySQL Shell (mysqlsh)
When starting MySQL Shell (Shell), you have two session options. The default option is mysqlx (‐‐mx), and this allows the session to connect using the X Protocol. The other option when starting Shell is ‐‐mysql, which establishes a “Classic Session” and connects using the standard MySQL protocol. For this post, I am using the default option of mysqlx (‐‐mx). There are other MySQL Shell command-line options for the X Protocol available. And, there are specific X Protocol variables which may need to be set for the mysqlx connection.
Here is a list of all of the MySQL Shell commands and their shortcuts (for MySQL version 8.0).
(source: https://dev.mysql.com/doc/mysql-shell/8.0/en/mysql-shell-commands.html)
| Command |
Alias/Shortcut |
Description |
| \help |
\h or \? |
Print help about MySQL Shell, or search the online help. |
| \quit |
\q or \exit |
Exit MySQL Shell. |
| \ |
|
In SQL mode, begin multiple-line mode. Code is cached and executed when an empty line is entered. |
| \status |
\s |
Show the current MySQL Shell status. |
| \js |
|
Switch execution mode to JavaScript. |
| \py |
|
Switch execution mode to Python. |
| \sql |
|
Switch execution mode to SQL. |
| \connect |
\c |
Connect to a MySQL Server. |
| \reconnect |
|
Reconnect to the same MySQL Server. |
| \use |
\u |
Specify the schema to use. |
| \source |
\. |
Execute a script file using the active language. |
| \warnings |
\W |
Show any warnings generated by a statement. |
| \nowarnings |
\w |
Do not show any warnings generated by a statement. |
| \history |
|
View and edit command line history. |
| \rehash |
|
Manually update the autocomplete name cache. |
| \option |
|
Query and change MySQL Shell configuration options. |
| \show |
|
Run the specified report using the provided options and arguments. |
| \watch |
|
Run the specified report using the provided options and arguments, and refresh the results at regular intervals. |
| \edit |
\e |
Open a command in the default system editor then present it in MySQL Shell. |
| \system |
\! |
Run the specified operating system command and display the results in MySQL Shell. |
To start the MySQL Shell (Shell), you simply execute the mysqlsh command from a terminal window. The default mode is JavaScript (as shown by the JS in the prompt).
$ mysqlsh
MySQL Shell 8.0.17-commercial
Copyright (c) 2016, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates.
Other names may be trademarks of their respective owners.
Type '\help' or '\?' for help; '\quit' to exit.
MySQL JS
|
By starting Shell without any variables, you will need to connect to a database instance. You do this with the \connect command, or you can use the \c shortcut. The syntax is \c user@ip_address:
|
MySQL JS \c root@127.0.0.1
Creating a session to 'root@127.0.0.1'
Fetching schema names for autocompletion. . . Press ^C to stop.
Your MySQL connection id is 16 (X protocol)
Server version: 8.0.17-commercial MySQL Enterprise Server – Commercial
No default schema selected; type \use to set one.
MySQL 127.0.0.1:33060+ ssl JS
|
Or, to start Shell with the connection information, specify the user and host IP address. The syntax is mysqlsh user@ip_address:
|
$ mysqlsh root@127.0.0.1
MySQL Shell 8.0.17-commercial
Copyright (c) 2016, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates.
Other names may be trademarks of their respective owners.
Type '\help' or '\?' for help; '\quit' to exit.
Creating a session to 'root@127.0.0.1'
Fetching schema names for autocompletion. . . Press ^C to stop.
Your MySQL connection id is 18 (X protocol)
Server version: 8.0.17-commercial MySQL Enterprise Server – Commercial
No default schema selected; type \use to set one.
MySQL 127.0.0.1:33060+ ssl JS
|
You may find a list of all of the command-line options at https://dev.mysql.com/doc/mysql-shell/8.0/en/mysqlsh.html.
The Shell prompt displays the connection information, whether or not you are using ssl, and your current mode (there are three modes – JavaScript, Python and SQL). In the earlier example, you are in the (default) JavaScript mode. You can also get your session information with the session command:
|
MySQL 127.0.0.1:33060+ ssl JS session
<Session:root@127.0.0.1:33060>
|
All of these commands are case-sensitive, so if you type an incorrect command, you will see the following error:
|
MySQL 127.0.0.1:33060+ ssl JS Session
ReferenceError: Session is not defined
|
Here is how you switch between the three modes: – JavaScript, Python and SQL.
|
MySQL 127.0.0.1:33060+ ssl JS \sql
Switching to SQL mode. . . Commands end with ;
MySQL 127.0.0.1:33060+ ssl SQL \py
Switching to Python mode. . .
MySQL 127.0.0.1:33060+ ssl Py \js
Switching to JavaScript mode. . .
MySQL 127.0.0.1:33060+ ssl JS
|
There are also several different output formats. You may change the output using the shell.options.set command. The default is table. Here are examples of each one, using the same command:
table output format
|
MySQL 127.0.0.1:33060+ ssl JS shell.options.set('resultFormat','table')
MySQL 127.0.0.1:33060+ ssl JS session.runSql('select user, host from mysql.user')
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐+
| user | host |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐+
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐+
4 rows in set (0.0005 sec)
|
JSON output format
|
MySQL 127.0.0.1:33060+ ssl JS shell.options.set('resultFormat','json')
MySQL 127.0.0.1:33060+ ssl JS session.runSql('select user, host from mysql.user limit 2')
{
“user”: “mysql.infoschema”,
“host”: “localhost”
}
{
“user”: “mysql.session”,
“host”: “localhost”
}
2 rows in set (0.0005 sec)
|
tabbed format
|
MySQL 127.0.0.1:33060+ ssl JS shell.options.set('resultFormat','tabbed')
MySQL 127.0.0.1:33060+ ssl JS session.runSql('select user, host from mysql.user')
user host
mysql.infoschema localhost
mysql.session localhost
mysql.sys localhost
root localhost
4 rows in set (0.0004 sec)
|
vertical format
|
MySQL 127.0.0.1:33060+ ssl JS shell.options.set('resultFormat','vertical')
MySQL 127.0.0.1:33060+ ssl JS session.runSql('select user, host from mysql.user order by user desc')
*************************** 1. row ***************************
user: mysql.infoschema
host: localhost
*************************** 2. row ***************************
user: mysql.session
host: localhost
*************************** 3. row ***************************
user: mysql.sys
host: localhost
*************************** 4. row ***************************
user: root
host: localhost
4 rows in set (0.0005 sec)
|
MySQL Shell – Create & Drop Schema
Note: With the MySQL Doc Store, the terms to describe the database, table and rows are different. The database is called the schema (even thought the doc store is “schema-less”). The tables are called collections, and the rows of data are called documents.
To create a schema named test1, use the createSchema command:
|
MySQL 127.0.0.1:33060+ ssl JS session.createSchema("test1")
<Schema:test1>
|
To get a list of the current schemas, use the getSchemas command:
|
MySQL 127.0.0.1:33060+ ssl JS session.getSchemas()
[
<Schema:information_schema>,
<Schema:mysql>,
<Schema:performance_schema>,
<Schema:sys>,
<Schema:test1>
]
|
Also, you can run SQL commands inside of the Doc Store – something you can't natively do with most other NoSQL databases. Instead of using the getSchemas command, you can issue a SHOW DATABASES SQL command using the runSql NoSQL command.
|
MySQL 127.0.0.1:33060+ ssl JS session.runSql('show databases')
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+
| Database |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+
| information_schema |
| mysql |
| performance_schema |
| sys |
| test1 |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+
5 rows in set (0.0052 sec)
|
To drop a schema named test1, you use the dropSchema command:
MySQL 127.0.0.1:33060+ ssl JS session.dropSchema("test1")
|
Just like with MySQL, you have to select the schema (database) you want to use. This shows you how to create a schema and set it as your default schema. With the \use command, you are really setting a variable named db to equal the default schema. So, after you have set your schema with the \use command, when you issue the db command, you can see the default schema.
|
MySQL 127.0.0.1:33060+ ssl JS session.createSchema("workshop")
MySQL 127.0.0.1:33060+ ssl JS \use workshop
Default schema `workshop` accessible through db.
MySQL 127.0.0.1:33060+ ssl workshop JS db
<Schema:workshop>
|
To change the value of the variable db, you may use the \use command or you may set the value of db using the var (variable) command. The command session.getSchema will return a schema value, but it does not automatically set the db variable value.)
|
MySQL 127.0.0.1:33060+ ssl JS \use workshop
Default schema `workshop` accessible through db.
MySQL 127.0.0.1:33060+ ssl workshop JS db
<Schema:workshop>
MySQL 127.0.0.1:33060+ ssl workshop JS session.getSchema('mysql');
<Schema:mysql>
MySQL 127.0.0.1:33060+ ssl workshop JS db
<Schema:workshop>
MySQL 127.0.0.1:33060+ ssl workshop JS var db = session.getSchema('mysql');
MySQL 127.0.0.1:33060+ ssl mysql JS db
<Schema:mysql>
|
You can also create your own variables. Here is an example of setting the variable sdb to equal the SQL command SHOW DATABASES:
|
MySQL 127.0.0.1:33060+ ssl workshop JS var sdb = session.runSql('show databases')
MySQL 127.0.0.1:33060+ ssl workshop JS sdb
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+
| Database |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+
| information_schema |
| mysql |
| performance_schema |
| sys |
| workshop |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+
6 rows in set (0.0079 sec)
|
But the variables are only good for your current session. If you quit Shell, log back in, and re-run the variable, you will get an error stating the variable is not defined.
|
MySQL 127.0.0.1:33060+ ssl workshop JS \q
Bye!
# mysqlsh root@127.0.0.1
. . .
MySQL 127.0.0.1:33060+ ssl JS sdb
ReferenceError: sdb is not defined
|
After you have created your schema (database), and selected it via \use command, then you can create a collection (table) and insert JSON documents into the collection. I will create a collection named test1.
|
MySQL 127.0.0.1:33060+ ssl JS \use workshop
MySQL 127.0.0.1:33060+ ssl workshop JS db.createCollection("test1")
|
You can get a list of collections by using the getCollections command, and you can also execute SQL commands with the session.runSql command. The getCollections command is the same as the SQL command SHOW TABLES.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.getCollections()
[
<Collection:test1>
]
MySQL 127.0.0.1:33060+ ssl workshop JS session.runSql('SHOW TABLES')
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+
| Tables_in_workshop |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+
| test1 |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+
1 row in set (0.0001 sec)
|
To drop a collection, use the dropCollection command. You can verify the collection was dropped by using the getCollections command again.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.dropCollection("test1")
MySQL 127.0.0.1:33060+ ssl workshop JS db.getCollections()
[]
|
If you have not selected a default database, you may also specify the schema name prior to the collection name (which is the same type of syntax when you create a table inside of a database in MySQL). You will notice the output is different, as when you specify the schema name before the collection name, that schema name is returned as well.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.createCollection("foods")
<Collection:foods>
MySQL 127.0.0.1:33060+ ssl JS db.createCollection("workshop.foods2")
<Collection:workshop.foods2>
|
To add a JSON document to a collection, you use the add command. You must specify a collection prior to using the add command. (You can't issue a command like workshop.foods.add.) You can add the document with or without the returns and extra spaces (or tabs). Here the JSON document to add to the collection named workshop:
|
{
Name_First: "Fox",
Name_Last: "Mulder",
favorite_food: {
Breakfast: "eggs and bacon",
Lunch: "pulled pork sandwich",
Dinner: "steak and baked potato"
}
}
|
Note: Some JSON formats require double quotes around the keys/strings. In this example, Name_First has double quotes in the first example, and the second example doesn’t have double quotes. Both formats will work in Shell.
The -> in the examples below is added by Shell. You don’t need to type this on the command line.
MySQL 127.0.0.1:33060+ ssl project JS db.foods.add({
-> "Name_First": "Steve"})
->
Query OK, 1 item affected (0.0141 sec)
MySQL 127.0.0.1:33060+ ssl project JS db.foods.add({
-> Name_First: "Steve"})
->
Query OK, 1 item affected (0.0048 sec)
Here are examples of each method of adding a JSON document – one where all of the data in the JSON document is on one line, and another where the JSON document contains data on multiple lines with returns and spaces included.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.add({Name_First: "Fox", Name_Last: "Mulder", favorite_food: {Breakfast: "eggs and bacon", Lunch: "pulled pork sandwich", Dinner: "steak and baked potato"}})
Query OK, 1 item affected (0.0007 sec)
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.add( {
-> Name_First: "Fox",
-> Name_Last: "Mulder",
-> favorite_food: {
-> Breakfast: "eggs and bacon",
-> Lunch: "pulled pork sandwich",
-> Dinner: "steak and baked potato"
-> } } )
->
Query OK, 1 item affected (0.0005 sec)
|
So far, I have created a schema, and a collection, and I have added one document to the collection. Next, I will show you how to perform searches using the find command.
Searching Documents
To find all records in a collection, use the find command without specifying any search criteria:
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find()
{
"_id": "00005d6fc3dc000000000027e065",
"Name_Last": "Mulder",
"Name_First": "Fox",
"favorite_food": {
"Lunch": "pulled pork sandwich",
"Dinner": "steak and baked potato",
"Breakfast": "eggs and bacon"
}
}
1 document in set (0.0002 sec)
|
Note: The _id key in the output above is automatically added to each document and the value of _id cannot be changed. Also, an index is automatically created on the _id column. You can check the index using the SQL SHOW INDEX command. (To make the output easier to view, I switched the format to vertical and I switched it back to table)
|
MySQL 127.0.0.1:33060+ ssl workshop JS shell.options.set('resultFormat','vertical')
MySQL 127.0.0.1:33060+ ssl workshop JS session.runSql('SHOW INDEX FROM workshop.foods')
*************************** 1. row ***************************
Table: foods
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: _id
Collation: A
Cardinality: 1
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
1 row in set (0.0003 sec)
MySQL 127.0.0.1:33060+ ssl workshop JS shell.options.set('resultFormat','table')
|
Here is how you perform a search by specifying the search criteria. This command will look for the first name of Fox via the Name_First key.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find('Name_First = "Fox"')
{
"_id": "00005d6fc3dc000000000027e065",
"Name_Last": "Mulder",
"Name_First": "Fox",
"favorite_food": {
"Lunch": "pulled pork sandwich",
"Dinner": "steak and baked potato",
"Breakfast": "eggs and bacon"
}
}
1 document in set (0.0004 sec)
|
And, if your search result doesn't find any matching documents, you will get a return of Empty set and the time it took to run the query:
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find('Name_First = "Jason"')
Empty set (0.0003 sec)
|
The first search returned all of the keys in the document because I didn’t specify any search criteria inside the find command – db.foods.find(). This example is how you retrieve just a single key inside a document. And notice the key favorite_food contains a list of sub-keys inside of a key.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find('Name_First = "Fox"').fields('favorite_food')
{
“favorite_food”: {
“Lunch”: “pulled pork sandwich”,
“Dinner”: “steak and baked potato”,
“Breakfast”: “eggs and bacon”
}
}
1 document in set (0.0004 sec)
|
To return multiple keys, add the additional keys inside the fields section, separated by a comma.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find('Name_First = "Fox"').fields("favorite_food", "Name_Last")
{
“Name_Last”: “Mulder”,
“favorite_food”: {
“Lunch”: “pulled pork sandwich”,
“Dinner”: “steak and baked potato”,
“Breakfast”: “eggs and bacon”
}
}
1 document in set (0.0003 sec)
|
Note: The fields are returned in the order they are stored in the document, and not in the order of the fields section. The query field order does not guarantee the same display order.
To return a sub-key from a list, you add the key prior to the sub-key value in the fields section. This search will return the value for the Breakfast sub-key in the favorite_food key.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find( 'Name_First = "Fox"' ).fields( "favorite_food.Breakfast" )
{
“favorite_food.Breakfast”: “eggs and bacon”
}
1 document in set (0.0002 sec)
|
Modifying Documents
To modify a document, you use the modify command, along with search criteria to find the document(s) you want to change. Here is the original JSON document.
|
{
“_id”: “00005d6fc3dc000000000027e065”,
“Name_Last”: “Mulder”,
“Name_First”: “Fox”,
“favorite_food”: {
“Lunch”: “pulled pork sandwich”,
“Dinner”: “steak and baked potato”,
“Breakfast”: “eggs and bacon”
}
}
|
I am going to change Fox's favorite_food sub-keys to Lunch being “soup in a bread bowl” and Dinner to “steak and broccoli”.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.modify("Name_First = 'Fox'").set("favorite_food", {Lunch: "Soup in a bread bowl", Dinner: "steak and broccoli"})
Query OK, 0 items affected (0.0052 sec)
|
I can see the changes by issuing a find command, searching for Name_First equal to “Fox”.
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find('Name_First = "Fox"')
{
"_id": "00005d6fc3dc000000000027e065",
"Name_Last": "Mulder",
"Name_First": "Fox",
"favorite_food": {
“Lunch”: "Soup in a bread bowl",
"Dinner": "steak and broccoli"
}
}
1 document in set (0.0004 sec)
|
Notice that the Breakfast sub-key is no longer in the list. This is because I changed the favorite_food list to only include Lunch and Dinner.
To change only one sub-key under favorite_food, such as Dinner, I can do that with the set command:
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.modify("Name_First = 'Fox'").set('favorite_food.Dinner', 'Pizza')
Query OK, 1 item affected (0.0038 sec)
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find("Name_First='Fox'")
{
"_id": "00005d8122400000000000000002",
"Name_Last": "Mulder",
"Name_First": "Fox",
"favorite_food": {
"Lunch": "Soup in a bread bowl",
"Dinner": "Pizza",
}
}
|
If I want to remove a single sub-key under favorite_food, I can use the unset command. I will remove the Dinner sub-key:
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.modify("Name_First = 'Fox'").unset("favorite_food.Dinner")
Query OK, 1 item affected (0.0037 sec)
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find("Name_First='Fox'")
{
"_id": "00005d8122400000000000000002",
"Name_Last": "Mulder",
"Name_First": "Fox",
"favorite_food": {
"Lunch": "Soup in a bread bowl",
}
}
|
The key favorite_food contained a list, but a key can also contain an array. The main format difference in an array and a list is an array has opening and closing square brackets [ ]. The brackets go on the outside of the values for the array.
Here is the original document with a list for favorite_food:
|
db.foods.add( {
Name_First: "Fox",
Name_Last: "Mulder",
favorite_food: {
Breakfast: "eggs and bacon",
Lunch: "pulled pork sandwich",
Dinner: "steak and baked potato"
}
}
)
|
I am going to delete the document for Fox, confirm the deletion occurred and insert a new document – but this time, I am going to use an array for favorite_food (and notice the square brackets).
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.remove('Name_First = "Fox"')
Query OK, 1 item affected (0.0093 sec)
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find("Name_First='Fox'")
Empty set (0.0003 sec)
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.add( {
-> Name_First: "Fox",
-> Name_Last: "Mulder",
-> favorite_food: [ {
-> Breakfast: "eggs and bacon",
-> Lunch: "pulled pork sandwich",
-> Dinner: "steak and baked potato"
-> } ]
-> }
-> )
->
Query OK, 1 item affected (0.0078 sec)
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find("Name_First='Fox'")
{
"_id": "00005da09064000000000027e068",
"Name_Last": "Mulder",
"Name_First": "Fox",
"favorite_food": [
{
"Lunch": "pulled pork sandwich",
"Dinner": "steak and baked potato",
"Breakfast": "eggs and bacon"
}
]
}
1 document in set (0.0004 sec)
|
When dealing with an array, I can modify each element in the array, or I can add another array element. I am going to add Fox's favorite Snack to the array with the arrayAppend command:
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.modify("Name_First = 'Fox'").arrayAppend("favorite_food", {Snack: "Sunflower seeds"})
Query OK, 1 item affected (0.0048 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find("Name_First='Fox'")
{
“_id”: “00005da09064000000000027e068”,
“Name_Last”: “Mulder”,
“Name_First”: “Fox”,
“favorite_food”: [
{
“Lunch”: “pulled pork sandwich”,
“Dinner”: “steak and baked potato”,
“Breakfast”: “eggs and bacon”
},
{
“Snack”: “Sunflower seeds”
}
]
}
1 document in set (0.0004 sec)
|
The key favorite_food now contains an array with two separate values in it. The sub-keys in the array position favorite_food[0] contains values for Lunch, Breakfast and Dinner values, while the array position favorite_food[1] only contains the Snack value.
Note: If you aren't familiar with arrays, an array is like a list that contains elements. Elements of the array are contained in memory locations relative to the beginning of the array. The first element in the array is actually zero (0) elements away from the beginning of the array. So, the placement of the first element is denoted as array position zero (0) and this is designated by [0]. Most programming languages have been designed this way, so indexing from zero (0) is pretty much inherent to most languages.
I can now delete an element in an array with the arrayDelete command. I am going to remove the Snack array member, which is favorite_food[1].
|
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.modify("Name_First = 'Fox'").arrayDelete("$.favorite_food[1]")
Query OK, 1 item affected (0.0035 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find("Name_First='Fox'")
{
"_id": "00005da09064000000000027e068",
"Name_Last": "Mulder",
"Name_First": "Fox",
"favorite_food": [
{
"Lunch": "pulled pork sandwich",
"Dinner": "steak and baked potato",
"Breakfast": "eggs and bacon"
}
]
}
1 document in set (0.0004 sec)
|
Modifying a document – adding a key
If I want to add an extra key, I need to add a few more variables and their values. I will need to define my schema and collection. Then I can use the patch command to add a key to an existing document.
I am going to add a middle name to Fox's document.
|
MySQL 127.0.0.1:33060+ ssl workshop JS var schema = session.getSchema('workshop')
MySQL 127.0.0.1:33060+ ssl workshop JS var collection = schema.getCollection('foods')
MySQL 127.0.0.1:33060+ ssl workshop JS collection.modify("Name_First = 'Fox'").patch({ Name_Middle: 'William' })
Query OK, 1 item affected (0.0020 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL 127.0.0.1:33060+ ssl workshop JS db.foods.find("Name_First='Fox'")
{
"_id": "00005da09064000000000027e068",
"Name_Last": "Mulder",
"Name_First": "Fox",
"Name_Middle": "William",
"favorite_food": [
{
"Lunch": "pulled pork sandwich",
"Dinner": "steak and baked potato",
"Breakfast": "eggs and bacon"
}
]
}
1 document in set (0.0004 sec)
|
Importing Large Data Sets
In order to demonstrate indexes, I will need to import a large amount of data. Before I import data, I need to be sure that I have a variable set for the mysqlx client protocol to allow larger client packets. Specifically, I need to set the mysqlx_max_allowed_packet variable to the largest allowable size of 1TB. You can set this variable in the MySQL configuration file (my.cnf or my.ini) and reboot the MySQL instance, or you can set it for your session.
I can check the values of the mysqlx_max_allowed_packet variable from within Shell, and if it isn't set to 1TB, I will modify it for this session. (I can see the value for mysqlx_max_allowed_packet is set to 100MB or 100 megabytes)
|
MySQL 127.0.0.1:33060+ ssl JS session.runSql('SHOW VARIABLES like "%packet%"')
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐+
| Variable_name | Value |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐+
| max_allowed_packet | 943718400 |
| mysqlx_max_allowed_packet | 104857600 |
| slave_max_allowed_packet | 1073741824 |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐+
3 rows in set (0.0021 sec)
MySQL 127.0.0.1:33060+ ssl JS session.runSql('SET @@GLOBAL.mysqlx_max_allowed_packet = 1073741824')
Query OK, 0 rows affected (0.0004 sec)
MySQL 127.0.0.1:33060+ ssl JS session.runSql('SHOW VARIABLES like "%packet%"')
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐+
| Variable_name | Value |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐+
| max_allowed_packet | 943718400 |
| mysqlx_max_allowed_packet | 1073741824 |
| slave_max_allowed_packet | 1073741824 |
+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐+
3 rows in set (0.0021 sec)
|
I don't want to write this large import to the binary log (I have binlog enabled), so I can use the SQL command to SET SQL_LOG_BIN = 0 first. I am going to create a new collection named project, and then import a 400+ megabyte JSON file into the new collection.
|
MySQL 127.0.0.1:33060+ ssl JS session.runSql('SET SQL_LOG_BIN=0')
Query OK, 0 rows affected (0.0464 sec)
MySQL 127.0.0.1:33060+ ssl JS session.createSchema("project")
MySQL 127.0.0.1:33060+ ssl JS \use project
Default schema `project` accessible through db.
MySQL 127.0.0.1:33060+ ssl JS util.importJson("./workshop/Doc_Store_Demo_File.json", {schema: "project", collection: "GoverningPersons"})
Importing from file "./workshop/Doc_Store_Demo_File.json" to collection `project`.`GoverningPersons` in MySQL Server at 127.0.0.1:33060
.. 2613346.. 2613346
Processed 415.71 MB in 2613346 documents in 2 min 51.0696 sec (15.28K documents/s)
Total successfully imported documents 2613346 (15.28K documents/s)
|
As you can see from the output above, I imported 2,613,346 documents.
Note: This imported JSON document contains public data regarding businesses in the State of Washington.
Now that I have my 2.6 million documents in the database, I will do a quick search and limit the results to one record by using the limit command. This will show you the keys in the document.
|
MySQL 127.0.0.1:33060+ ssl JS \use project
Default schema `project` accessible through db.
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.find().limit(1)
{
"Ubi": "601544680",
"Zip": "99205",
"_id": "00005d6fc3dc000000000027e067",
"City": "SPOKANE",
"State": "WA",
"Title": "GOVERNOR",
"Address": "RT 5",
"LastName": "FRISCH",
"FirstName": "BOB",
"MiddleName": ""
}
1 document in set (0.0022 sec)
|
Again – notice an index for the key _id has automatically been added:
|
MySQL 127.0.0.1:33060+ ssl JS session.runSql('SHOW INDEX FROM project.GoverningPersons')
*************************** 1. row ***************************
Table: GoverningPersons
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: _id
Collation: A
Cardinality: 2481169
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
1 row in set (0.0137 sec)
|
To demonstrate indexes on a large dataset, I will perform two searches against all documents in the project collection – where LastName is equal to FRISCH and where LastName is equal to VARNELL. Then, I will create the index on LastName, and re-run the two find queries. Note: I am not displaying all of the returned documents to save space.
|
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.find('LastName = "FRISCH"')
{
"Ubi": "601544680",
"Zip": "99205",
"_id": "00005da09064000000000027e069",
"City": "SPOKANE",
"State": "WA",
"Title": "GOVERNOR",
"Address": "RT 5",
"LastName": "FRISCH",
"FirstName": "BOB",
"MiddleName": ""
}
. . .
82 documents in set (1.3559 sec)
|
|
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.find('LastName = "VARNELL"')
{
"Ubi": "602268651",
"Zip": "98166",
"_id": "00005da09064000000000028ffdc",
"City": "SEATTLE",
"State": "WA",
"Title": "GOVERNOR",
"Address": "18150 MARINE VIEW DR SW",
"LastName": "VARNELL",
"FirstName": "JAMES",
"MiddleName": ""
}
. . .
33 documents in set (1.0854 sec)
|
The searches took 1.3559 and 1.0854 seconds, respectively. I can now create an index on LastName. When I create an index, I have to specify the data type for that particular key. And for a text key, I have to specify how many characters of that key I want to include in the index. (Note: see TEXT(20) in the command below)
|
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.createIndex("i_Name_Last", {fields: [{field: "$.LastName", type: "TEXT(20)"}]})
Query OK, 0 rows affected (8.0653 sec)
|
Now I will re-run the same two queries where LastName equals FRISCH and where LastName equals VARNELL.
|
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.find('LastName = "FRISCH"')
{
"Ubi": "601544680",
"Zip": "99205",
"_id": "00005da09064000000000027e069",
"City": "SPOKANE",
"State": "WA",
"Title": "GOVERNOR",
"Address": "RT 5",
"LastName": "FRISCH",
"FirstName": "BOB",
"MiddleName": ""
}
. . .
82 documents in set (0.0097 sec)
|
|
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.find('LastName = "VARNELL"')
{
"Ubi": "602268651",
"Zip": "98166",
"_id": "00005da09064000000000028ffdc",
"City": "SEATTLE",
"State": "WA",
"Title": "GOVERNOR",
"Address": "18150 MARINE VIEW DR SW",
"LastName": "VARNELL",
"FirstName": "JAMES",
"MiddleName": ""
}
. . .
33 documents in set (0.0008 sec)
|
The queries ran much faster with an index – 0.0097 seconds and 0.0008 seconds. Not bad for searching 2.6 million records.
Note: The computer I was using for this post is a Hackintosh, running Mac OS 10.13.6, with an Intel i7-8700K 3.7GHz processor with six cores, with 32GB 2666MHz DDR4 RAM, and an SATA III 6 Gb/s, M.2 2280 SSD. Your performance results may vary.
And I can take a look at the index for LastName:
|
MySQL 127.0.0.1:33060+ ssl JS shell.options.set('resultFormat','vertical')
MySQL 127.0.0.1:33060+ ssl JS session.runSql('SHOW INDEX FROM project.GoverningPersons')
*************************** 1. row ***************************
Table: GoverningPersons
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: _id
Collation: A
Cardinality: 2481169
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: GoverningPersons
Non_unique: 1
Key_name: i_Name_Last
Seq_in_index: 1
Column_name: $ix_t20_F1A785D3F25567CD94716D955607AADB04BB3C0E
Collation: A
Cardinality: 300159
Sub_part: 20
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
2 rows in set (0.0059 sec)
MySQL 127.0.0.1:33060+ ssl JS shell.options.set('resultFormat','table')
|
I can create an index on multiple columns as well. Here is an index created on the State and Zip fields.
|
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.createIndex('i_state_zip', {fields: [ {field: '$.State', type: 'TEXT(2)'}, {field: '$.Zip', type: 'TEXT(10)'}]})
Query OK, 0 rows affected (10.4536 sec)
|
I can take a look at the index as well (the other index results were removed to save space).
|
MySQL 127.0.0.1:33060+ ssl JS shell.options.set('resultFormat','vertical')
MySQL 127.0.0.1:33060+ ssl JS session.runSql('SHOW INDEX FROM project.GoverningPersons')
. . .
*************************** 3. row ***************************
Table: GoverningPersons
Non_unique: 1
Key_name: i_state_zip
Seq_in_index: 1
Column_name: $ix_t2_00FFBF570DC47A52910DDA38C0C1FB1361F0426A
Collation: A
Cardinality: 864
Sub_part: 2
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 4. row ***************************
Table: GoverningPersons
Non_unique: 1
Key_name: i_state_zip
Seq_in_index: 2
Column_name: $ix_t10_18619E3AC96C74FECCF6B622D9DB0864C2938AB6
Collation: A
Cardinality: 215626
Sub_part: 10
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
4 rows in set (0.0066 sec)
MySQL 127.0.0.1:33060+ ssl JS shell.options.set('resultFormat','table')
|
I will run a query looking for the first entry FRISH based upon his state (WA) and Zip (99205). The query result time is still pretty good, even though I am also returning his LastName.
|
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.find("State='WA' AND Zip = '99205' AND LastName = 'FRISCH'")
{
"Ubi": "601544680",
"Zip": "99205",
"_id": "00005da09064000000000027e069",
"City": "SPOKANE",
"State": "WA",
"Title": "GOVERNOR",
"Address": "RT 5",
"LastName": "FRISCH",
"FirstName": "BOB",
"MiddleName": ""
}
1 document in set (0.0011 sec)
|
To drop an index, use the dropIndex command:
|
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.dropIndex("i_Name_Last")
|
NoSQL and SQL in the same database
The great advantage to using MySQL to store JSON documents is that the data is stored in the InnoDB storage engine. So, the NoSQL document store database has features and benefits of InnoDB – such as transactions and ACID-compliance. This also means that you can use MySQL features like replication, group replication, transparent data encryption, etc. And if you need to restore a backup and play back the binlog files for a point-in-time recovery, you can do that as well, as all of the NoSQL transactions are written to the MySQL Binary Log. Here is what a NoSQL transaction looks like in the MySQL binary log:
NoSQL:
|
collection.modify(""Name_First = 'Selena'").patch({ Name_Middle: 'Kitty' })
|
MySQL Binlog:
|
# at 3102
#191018 11:17:41 server id 3451 end_log_pos 3384 CRC32 0xd0c12cca Query thread_id=15 exec_time=0 error_code=0
SET TIMESTAMP=1571411861/*!*/;
UPDATE `workshop`.`foods` SET doc=JSON_SET(JSON_MERGE_PATCH(doc, JSON_OBJECT('Name_Middle','Kitty')),'$._id',JSON_EXTRACT(`doc`,'$._id')) WHERE (JSON_EXTRACT(doc,'$.Name_First') = 'Selena')
/*!*/;
# at 3384
#191018 11:17:41 server id 3451 end_log_pos 3415 CRC32 0xe0eaf4ef Xid = 246
COMMIT/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
|
Finally, here is an example of how to do a transaction:
|
MySQL 127.0.0.1:33060+ ssl JS session.startTransaction()
Query OK, 0 rows affected (0.0013 sec)
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.modify("Ubi = '601544680'").set("MiddleName", "PETER")
Query OK, 1 item affected (0.0089 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL 127.0.0.1:33060+ ssl JS session.rollback()
Query OK, 0 rows affected (0.0007 sec)
MySQL 127.0.0.1:33060+ ssl JS db.GoverningPersons.modify("Ubi = '601544680'").set("MiddleName", "STEVEN")
Query OK, 1 item affected (0.0021 sec)
Rows matched: 1 Changed: 1 Warnings: 0
MySQL 127.0.0.1:33060+ ssl JS session.commit()
Query OK, 0 rows affected (0.0002 sec)
|
JSON functions
Since the MySQL Document Store utilizes the MySQL database server and since the documents are stored in InnoDB, you can also use MySQL SQL JSON functions as well to manipulate the data stored in either a JSON document or in a JSON data type. Here is a list of the JSON functions available, and while JSON functions were introduced in 5.7, not all of these functions will be in 5.7 – but they are all in version 8.0.
| JSON_ARRAY |
JSON_ARRAY_APPEND |
JSON_ARRAY_INSERT |
JSON_CONTAINS |
| JSON_CONTAINS_PATH |
JSON_DEPTH |
JSON_EXTRACT |
JSON_INSERT |
| JSON_KEYS |
JSON_LENGTH |
JSON_MERGE_PATCH |
JSON_MERGE_PRESERVE |
| JSON_OBJECT |
JSON_OVERLAPS |
JSON_PRETTY |
JSON_QUOTE |
| JSON_REMOVE |
JSON_REPLACE |
JSON_SCHEMA_VALID |
JSON_SCHEMA_VALIDATION_REPORT |
| JSON_SEARCH |
JSON_SET |
JSON_STORAGE_FREE |
JSON_STORAGE_SIZE |
| JSON_TABLE |
JSON_TYPE |
JSON_UNQUOTE |
JSON_VALID |
| MEMBER OF |
|
|
|
But you already use Mongo? And you have MySQL as well?
If you already use Mongo and MySQL, and you want to switch to MySQL, or if your DBA's already know Mongo, then moving to MySQL or using the MySQL doc store is pretty easy. The commands used in Mongo are very similar to the ones used in the MySQL Document Store. The login command is similar to the MySQL “regular” client command in that you specify the user and password with the -u and -p.
In MySQL Shell, you put the username followed by the @ and the IP address. And you can specify which database or schema you want to use upon login. Mongo does have a few shortcuts with the show command, as in show dbs, show schemas or show collections. But you can do almost the same in MySQL Shell by setting variables to equal certain functions or commands (like I did earlier.)
To create a schemda/database in Mongo, you simply execute the use database name command – and it creates the schema/database if it doesn't exist. The other commands having to do with collections are almost the same.
Where there are differences, they are relatively small. Mongo uses the command insert and MySQL uses add when inserting documents. But then, other commands such as the remove document command are the same.
As for the last item in the table below, native Mongo can't run any SQL commands (without using a third-party software GUI tool) – so again, if you have MySQL DBA's on staff, the learning curve can be lower because they can use SQL commands if they don't remember the NoSQL commands.
| Command |
Mongo |
MySQL Document Store (via Shell) |
| Login
|
mongo ‐u ‐p ‐‐database
|
mysqlsh root@127.0.0.1 ‐‐database |
| Select schema
|
use database_name
|
\use database_name |
| Show schemas/dbs
|
show dbs
|
session.getSchemas() |
| Create schema
|
use database_name
|
session.createSchema() |
| Show collections
|
show collections or db.getCollectionNames();
|
db.getCollections() |
| Create collection
|
db.createCollection("collectionName");
|
db.createCollection("collectionName"); |
| Insert document
|
db.insert({field1: "value", field2: "value"})
|
db.insert({field1: "value", field2: "value"}) |
| Remove document
|
db.remove()
|
db.remove() |
| Run SQL command
|
|
session.runSql(SQL_command) |
So, with MySQL, you have a hybrid solution where you can use both SQL and NoSQL at the same time. And, since you are storing the JSON documents inside MySQL, you an also use the MySQL JSON functions to search, update and delete the same records.

 MySQL Workbench is a great multi-purpose GUI tool for MySQL, which I think is not marketed enough by the MySQL team and is not appreciated enough by the community for what it can do.
MySQL Workbench is a great multi-purpose GUI tool for MySQL, which I think is not marketed enough by the MySQL team and is not appreciated enough by the community for what it can do.




























 ProxySQL 2.0.7, released by
ProxySQL 2.0.7, released by 












 In MySQL 8.0.18 there is a new feature called
In MySQL 8.0.18 there is a new feature called 
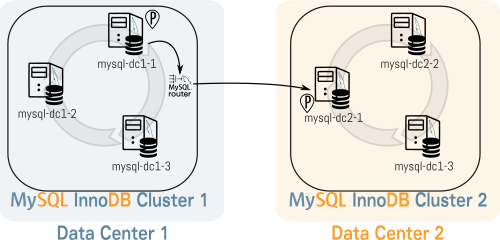
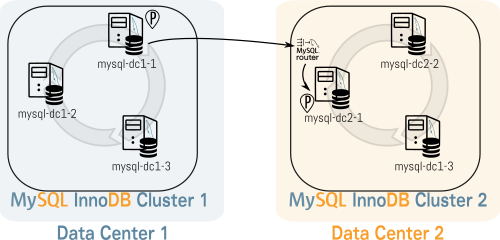

 From time to time you may have experienced that MySQL was not able to find the best execution plan for a query. You felt the query should have been faster. You felt that something didn’t work, but you didn’t realize exactly what.
From time to time you may have experienced that MySQL was not able to find the best execution plan for a query. You felt the query should have been faster. You felt that something didn’t work, but you didn’t realize exactly what.




 In
In